Vous aimerez peut-être aussi
- A Visual Environment For The Lua LanguageDocument6 pagesA Visual Environment For The Lua LanguageMikhail MiguelPas encore d'évaluation
- The Evolution of Lua: Roberto Ierusalimschy Luiz Henrique de Figueiredo Waldemar CelesDocument26 pagesThe Evolution of Lua: Roberto Ierusalimschy Luiz Henrique de Figueiredo Waldemar Celesansible007Pas encore d'évaluation
- The LUA 5.1 Language Short ReferenceDocument4 pagesThe LUA 5.1 Language Short Reference_FANTA_Pas encore d'évaluation
- World of Warcraft 10000000 Lua Users and Growing!Document23 pagesWorld of Warcraft 10000000 Lua Users and Growing!Mikhail MiguelPas encore d'évaluation
- Open at Dynamic Programming With Lua TutorialDocument26 pagesOpen at Dynamic Programming With Lua TutorialMikhail MiguelPas encore d'évaluation
- Minix 3 and Lua, Berkeley DB, and SqliteDocument3 pagesMinix 3 and Lua, Berkeley DB, and SqliteMikhail MiguelPas encore d'évaluation
- Fabio Mascarenhas, Roberto IerusalimschyDocument11 pagesFabio Mascarenhas, Roberto IerusalimschyMikhail MiguelPas encore d'évaluation
- Lua Programming GemsDocument17 pagesLua Programming Gemscross trigger100% (1)
- Nasa Lua Beer PresentationDocument16 pagesNasa Lua Beer PresentationMikhail MiguelPas encore d'évaluation
- The Implementation of Lua 5.0: Roberto Ierusalimschy Luiz Henrique de Figueiredo Waldemar CelesDocument32 pagesThe Implementation of Lua 5.0: Roberto Ierusalimschy Luiz Henrique de Figueiredo Waldemar CelesMikhail MiguelPas encore d'évaluation
- LuaDocument1 pageLuaMikhail MiguelPas encore d'évaluation
- Lua Scripting in WiresharkDocument45 pagesLua Scripting in WiresharkMikhail Miguel100% (1)
- Lua Regex On ParrotDocument5 pagesLua Regex On ParrotMikhail MiguelPas encore d'évaluation
- Lua ProgrammingDocument13 pagesLua ProgrammingMikhail Miguel0% (1)
- Lua Presentation For The Chicago Glug 5-5-2007Document17 pagesLua Presentation For The Chicago Glug 5-5-2007Mikhail MiguelPas encore d'évaluation
- Lua - First Steps in Programming: Knut Lickert March 12, 2007Document14 pagesLua - First Steps in Programming: Knut Lickert March 12, 2007Mikhail MiguelPas encore d'évaluation
- Lua Plugin For BarracudaDocument1 pageLua Plugin For BarracudaMikhail MiguelPas encore d'évaluation
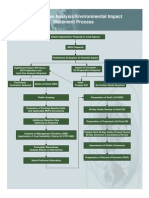
- Lua Eis Process Rev TarDocument1 pageLua Eis Process Rev TarMikhail MiguelPas encore d'évaluation
- Roberto Ierusalimschy Luiz Henrique de Figueiredo Waldemar CelesDocument53 pagesRoberto Ierusalimschy Luiz Henrique de Figueiredo Waldemar CelesMikhail MiguelPas encore d'évaluation
- Lua 5.1 A Short ReferenceDocument8 pagesLua 5.1 A Short ReferenceMikhail MiguelPas encore d'évaluation
- Fidelis Assis - Spam.finalDocument7 pagesFidelis Assis - Spam.finalMikhail MiguelPas encore d'évaluation
- Languages Implementation With Parrot Lua On Parrot A Study CaseDocument24 pagesLanguages Implementation With Parrot Lua On Parrot A Study CaseMikhail MiguelPas encore d'évaluation
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5795)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Data Cleansing LectureDocument18 pagesData Cleansing Lectureharshilsurti100% (1)
- 400+ TOP COMPILER DESIGN LAB VIVA Questions and AnswersDocument22 pages400+ TOP COMPILER DESIGN LAB VIVA Questions and Answersravi sharmaPas encore d'évaluation
- BDB User GuideDocument224 pagesBDB User GuidePaul AsturbiarisPas encore d'évaluation
- 1 LR ParserDocument6 pages1 LR Parsernajma rasool100% (1)
- Spos Unit 2 PPT 2022 CompressedDocument89 pagesSpos Unit 2 PPT 2022 Compressedअभिजित शिंदेPas encore d'évaluation
- SDT PDFDocument16 pagesSDT PDFAnonymous OJwO906FrPas encore d'évaluation
- Ai Unit-5 NotesDocument30 pagesAi Unit-5 Notes4119 RAHUL S100% (1)
- Syntax Analysis With BisonDocument30 pagesSyntax Analysis With BisonahmfawPas encore d'évaluation
- ISRO CS 2016-Watermark - pdf-80Document6 pagesISRO CS 2016-Watermark - pdf-80Govind VijayPas encore d'évaluation
- VI Sem Scheme and Syllabus of ITDocument16 pagesVI Sem Scheme and Syllabus of ITSOUMY PRAJAPATIPas encore d'évaluation
- Integration Using SAP PI: A Case StudyDocument18 pagesIntegration Using SAP PI: A Case StudyChandra ChPas encore d'évaluation
- Oops TutorialDocument20 pagesOops TutorialRajesh MandadapuPas encore d'évaluation
- Language Processors IntroDocument39 pagesLanguage Processors IntroPearl RodriguesPas encore d'évaluation
- How To Read XML File From QTPDocument5 pagesHow To Read XML File From QTPapi-19840982Pas encore d'évaluation
- Natural Language Processing State of The Art, Current Trends and Challenges - s11042-022-13428-4 PDFDocument32 pagesNatural Language Processing State of The Art, Current Trends and Challenges - s11042-022-13428-4 PDFarshiya khanPas encore d'évaluation
- NewsDocument106 pagesNewsBojan TodorovićPas encore d'évaluation
- Command Line Arguments in C Example PDFDocument2 pagesCommand Line Arguments in C Example PDFRebeccaPas encore d'évaluation
- Compiler Construction ToolsDocument2 pagesCompiler Construction Toolsbijay khadka100% (1)
- Hall Ticket Number:: Answer Question No.1 Compulsorily. Answer ONE Question From Each UnitDocument7 pagesHall Ticket Number:: Answer Question No.1 Compulsorily. Answer ONE Question From Each Unitsatyamoorthy mPas encore d'évaluation
- Lex and YaccDocument2 pagesLex and Yaccsomy19janPas encore d'évaluation
- CS3201 Assignment 4: Extended Prototype: 12pm. SubmissionDocument10 pagesCS3201 Assignment 4: Extended Prototype: 12pm. SubmissionNicholasLumPas encore d'évaluation
- 04 - Parsing in NLPDocument39 pages04 - Parsing in NLPnupur104btit20Pas encore d'évaluation
- The Cocke-Younger-Kasami Algorithm 1Document17 pagesThe Cocke-Younger-Kasami Algorithm 1abida rasoolPas encore d'évaluation
- 04 Influences in Language DesignDocument24 pages04 Influences in Language DesignEron Miranda50% (2)
- UPTU B.tech Computer Science 3rd 4th YrDocument51 pagesUPTU B.tech Computer Science 3rd 4th YrAmit MishraPas encore d'évaluation
- Compiler Construction Principles and PracticeDocument15 pagesCompiler Construction Principles and PracticeTarun BeheraPas encore d'évaluation
- Bottom Up Parsing: Session 14-15-16Document28 pagesBottom Up Parsing: Session 14-15-16Rifky PratamaPas encore d'évaluation
- UGC NET Syllabus 2018 For Computer Science and ApplicationDocument9 pagesUGC NET Syllabus 2018 For Computer Science and Applicationshashi28janPas encore d'évaluation
- SRM B.tech Part-Time CurriculumDocument78 pagesSRM B.tech Part-Time CurriculumSathish Babu S GPas encore d'évaluation
- Web ServicesDocument16 pagesWeb ServicesjesudosssPas encore d'évaluation