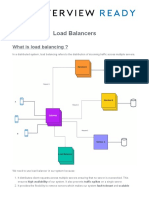
Vous aimerez peut-être aussi
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Structured Coding Techniques of Software DevelopmentDocument38 pagesStructured Coding Techniques of Software DevelopmentJimmey88% (8)
- Post-Quiz - DSDMDocument4 pagesPost-Quiz - DSDMSunetra Mukherjee67% (3)
- Apache Cassandra Sample ResumeDocument17 pagesApache Cassandra Sample Resumerevanth reddyPas encore d'évaluation
- ElectronicVATRegisterBooksWithSII V1.5Document26 pagesElectronicVATRegisterBooksWithSII V1.5ordonezpedroPas encore d'évaluation
- Reactive Programming Java 9Document551 pagesReactive Programming Java 9Marcos OttonelloPas encore d'évaluation
- Documentum Composer 6.5 SP1 User GuideDocument225 pagesDocumentum Composer 6.5 SP1 User GuideSindhu Bharathi ChandranPas encore d'évaluation
- Lex and Yacc InstallationDocument26 pagesLex and Yacc InstallationAshriti JainPas encore d'évaluation
- 1.1 3DXXX-200VA-Vulnerability Assessment Management: Training Schedule MonthDocument100 pages1.1 3DXXX-200VA-Vulnerability Assessment Management: Training Schedule MonthNathaniel JackPas encore d'évaluation
- Combine SEGY FilesDocument16 pagesCombine SEGY FilesNazeer AhmedPas encore d'évaluation
- 1st CBSE NIZ PaperDocument2 pages1st CBSE NIZ PaperAaditya Vignyan VellalaPas encore d'évaluation
- Bucket Sort AlgorithmDocument8 pagesBucket Sort Algorithmkarthik gundaPas encore d'évaluation
- Embedded Systems ProgrammingDocument24 pagesEmbedded Systems ProgrammingMena AimanPas encore d'évaluation
- Ride IntroDocument15 pagesRide IntrosakthikothandapaniPas encore d'évaluation
- EXP10 - CocomoDocument4 pagesEXP10 - Cocomorboy1993Pas encore d'évaluation
- Software Design & Architecture: Logical Architecture and UML Package DiagramsDocument14 pagesSoftware Design & Architecture: Logical Architecture and UML Package DiagramsRabbia KhalidPas encore d'évaluation
- Endevor QuickEditDocument31 pagesEndevor QuickEditAkash KumarPas encore d'évaluation
- A Crash Course On TheDepths of Win32 Structured Exception Handling, MSJ January 1997Document19 pagesA Crash Course On TheDepths of Win32 Structured Exception Handling, MSJ January 1997tzving100% (1)
- University Management System (UMS) : Mini Project OnDocument29 pagesUniversity Management System (UMS) : Mini Project OnSuhaib Alam67% (3)
- SQL 1Document40 pagesSQL 1439 SrivishnuPas encore d'évaluation
- Nosql : Knowledge Engineering and RepresentationDocument30 pagesNosql : Knowledge Engineering and RepresentationvalerPas encore d'évaluation
- Load BalancerDocument7 pagesLoad BalancerigvieiraPas encore d'évaluation
- Sumbilon, Austine Couline G. Basic Computer Bsit-2Nd YearDocument8 pagesSumbilon, Austine Couline G. Basic Computer Bsit-2Nd YearHayizswahf Yoezs EixorbPas encore d'évaluation
- Curiosity+Stream+VPAT®+2 4+-+WCAG+EditionDocument15 pagesCuriosity+Stream+VPAT®+2 4+-+WCAG+EditionTeohKXPas encore d'évaluation
- HTTP Client RequestDocument6 pagesHTTP Client RequestvhfyhfbcbtyfPas encore d'évaluation
- Hostel Management System Literature Review SampleDocument4 pagesHostel Management System Literature Review SampleaflskfbuePas encore d'évaluation
- HedEx Lite V100R003 Introduction V1.0Document33 pagesHedEx Lite V100R003 Introduction V1.0Sameer IbraimoPas encore d'évaluation
- PLSQL 9 2 PracticeDocument7 pagesPLSQL 9 2 PracticeAikoPas encore d'évaluation
- Build Docker ImageDocument5 pagesBuild Docker ImageJarek Bob DylewskiPas encore d'évaluation
- Unit 4: Functions and Program Structure 9Document24 pagesUnit 4: Functions and Program Structure 9SURIYA M SEC 2020Pas encore d'évaluation
- Jview TechnicalNote en v1 LoadingJigsawMSQLExtensionsToAnSQLServerDocument3 pagesJview TechnicalNote en v1 LoadingJigsawMSQLExtensionsToAnSQLServerJose BezerraPas encore d'évaluation