Académique Documents
Professionnel Documents
Culture Documents
Analisis Sintactico
Transféré par
Alejandro ZacariasTitre original
Copyright
Formats disponibles
Partager ce document
Partager ou intégrer le document
Avez-vous trouvé ce document utile ?
Ce contenu est-il inapproprié ?
Signaler ce documentDroits d'auteur :
Formats disponibles
Analisis Sintactico
Transféré par
Alejandro ZacariasDroits d'auteur :
Formats disponibles
11631
CAPITULO 4
Anlisis sintctico
Todo lenguaje de programacibn tiene reglas que prescriben la estructura sintactica de
programas bien formados. En Pascal, por ejemplo, un programa se compone de
bloques, un bloque de proposiciones, una proposiciOn de expresiones, una expresibn de componentes lexicos, y asi sucesivamente. Se puede describir la sintaxis de las construcciones de los lenguajes de programacibn por medio de gramaticas independientes del contexto o notaci6n BNF (forma de Backus-Naur), que se introdujo en la seccidn 2.2. Las gramaticas ofrecen ventajas significativas a los disehadores de lenguajes y a los escritores de compiladores. Una gramatica da una especificacibn sintactica precisa y facil de entender de un lenguaje de programacibn. A partir de algunas clases de gramaticas se puede construir automaticamente un analizador sintactico eficiente que determine si un programs fuente esta sintac-
ticamente bien formado. Otra ventaja es que el proceso de construcci6n del analizador sintactico puede revelar ambiguedades sintacticas y otras construcciones dificiles de analizar que de otro modo podrian pasar sin detectar en la fase inicial de disefo de un lenguaje y de su compilador. Una gramAtica disehada adecuadamente imparte una estructura a un lenguaje
de programacibn util para la traduccibn de programas fuente a cbdigo objeto correcto y para la detecci6n de errores. Existen herramientas para convertir descripciones de traducciones basadas en gramaticas en programas operativos.
Los lenguajes evolucionan con el tiempo, adquiriendo nuevas construcciones y
realizando tareas adicionales. Estas nuevas construcciones se pueden ac adir con mss
facilidad a un lenguaje cuando existe una aplicacibn basada en una descripcibn
gramatical del lenguaje. La mayor parte de este capitulo esta dedicada a los metodos de analisis sintactico de use tipico en compiladores. Primero se introducen los conceptos basicos, despu6s las tecnicas adecuadas para la aplicacibn manual y, por ultimo, los algoritmos que han silo utilizados en herramientas automatizadas. Como Jos programas pueden contener errores sintacticos, se amplian los metodos de analisis sintactico para que se recuperen de Jos errores de ocurrencia mss frecuente.
164
ANALISIS SIN TACTICO
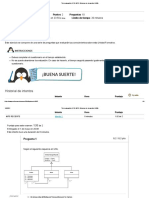
4.1 EL PAPEL DEL ANALIZADOR SINTACTICO En este modelo de compilador, el analizador sintactico obtiene una cadena de com-
ponentes lexicos del analizador lexico, como se muestra en la figura 4.1, y comprueba si la cadena pueda ser generada por la gramatica del lenguaje fuente. Se su-
pone que el analizador sintactico informara de cualquier error de sintaxis de manera
inteligible. Tambien deberia recuperarse de los errores que ocurren frecuentemente para poder continuar procesando el resto de su entrada.
programa fuente
analizador lexico
components lexico cohlener siguiente
analt_udor arbol de recto de Ia rc pre cntacion sintactir0 analisis etapa inicial intermedia sintactico
c omponente lxico
tabla de simbolos
Fig. 4.1. Posicion del analizador sintactico en el modelo del compilador.
Existen tres tipos generates de analizadores sintacticos para gramaticas. Los metodos universales de analisis sintactico, como el algoritmo de Cocke-Younger-Kasami y el de Earley, pueden analizar cualquier gramatica (veanse las notas bibliograficas). Estos metodos, sin embargo, son demasiado ineficientes para usarlos en la
produccion de compiladores. Los m etodos empleados generalmente en los compi-
ladores se clasifican como descendentes o ascendentes. Como sus nombres indican,
los analizadores sintacticos descendentes construyen arboles de analisis sintactico
desde arriba (la raiz) hasta abajo (las hojas), mientras que los analizadores sintacticos ascendentes comienzan en [as hojas y suben hacia la raiz. En ambos casos, se examina la entrada al analizador sintactico de izquierda a derecha, un simbolo a la
vez.
Los metodos descendentes y ascendentes mas eficientes trabajan solo con subclases de gramaticas, pero varias de estas subclases, como las gramaticas LL y LR,
son to suficientemente expresivas para describir la mayoria de las construcciones
sintacticas de los lenguajes de programaciOn. Los analizadores sintacticos implantados a mano a menudo trabajan con gramaticas LL 1, por ejemplo, el metodo de la seccidn 2.4 construye analizadores sintacticos para gramaticas LL 1. Los analizadores sintacticos para la clase mas grande de gramaticas LR se construyen normalmente con herramientas automatizadas. En este capitulo se asume que la salida del analizador sintactico es una represen-
tacibn del arbol de analisis sintactico para la cadena de componentes lexicos pro-
4.1
EL PAPEL DEL .ANALIZA OR SIN I .\C I-WO
165
ducida por el analizador lexico. En la practica, hay varias tareas que se pueden rea lizar
durante el analisis sintactico, como recoger informaci6n sobre distintos componentes lexicos en la tabla de simbolos, realizar la verificaci6n de tipo y otras clases de analisis semantico, y generar c6digo intermedio como en el capitulo 2. Se han agrupado todas estas actividades en la casilla de "resto de la etapa inicial" de la figura 4.1 y se analizara con detalle en los tres capitulos siguientes. En el resto de esta secci6n. se considera la naturaleza de los errores sintacticos y las estrategias generales para su recuperaci6n. Dos de estas estrategias. llamadas recuperaci6n en modo de panico y a nivel de frase. se estudian con mas detalle junto con los metodos de analisis sintactico individuales. La implantaci6n de cada estrategia depende del criterio del que escribe el compilador. pero aqui se darfin algunas
sugerencias respecto al metodo.
Manejo de errores sintacticos
Si un compilador tuviera que procesar s6lo programas correctos. su diseho e im-
plantacian se simplificarian mucho. Pero los programadores a menudo escriben
programas incorrectos. v un buen compilador deberia ayudar al programador a identificar y localizar errores. Es sorprendente que aunque los errores sewn tan frecuentes, pocos lenguajes han lido diserlados teniendo en cuenta el manejo de errores. Esta civilizaci6n seria completarnente distinta si los lenguajes hablados exigieran
tanta exactitud sintactica como los lenguajes de programaci6n. La mayoria de las especificaciones de los lenguajes de programaci6n no describen c6mo debe respon-
der un compilador a los errores: la respuesta se deja al dischador del compilador.
Considerar desde el principio el manejo de errores puede simplificar la estructura de un
compilador N. mejorar su respuesta a los errores.
Se sabe que los programas pueden contener errores de muv diverso tipo. Por
ejemplo. los errores pueden ser:
lexicon, como escribir mal un identificador, palabra slave u operador
sintzicticos. como una expresi6n aritmetica con parentesis no equilibrados semanticos, corno un operador aplicado a un operando incompatible 16gicos. como una Ilamada infinitamente recursiva A menudo. gran parts de la detecci6n y recuperaciOn de errores en un compilador se contra en la Case de analisis sintactico. Una razOn es que muchos errores son
de naturaleza sintactica o se manifiestan cuando la cadena de componentes lexicos
que proviene del analizador lexico desobedece las reglas gramaticales que definen al
lenguaje de prograrnaci6n. Otra raz6n es la precisi6n de los metodos modernos de analisis sintacticos, que pueden detectar la presencia de errores denim de los programas de una forma muy eficiente. La detecci6n exacta de la presencia de errores Semanticos y l6gicos en el momento de la compilaci6n es mucho mas dificil. En esta secci6n se presentan algunas tecnicas basicas para recuperarse de errores sintacticos: en este capitulo se estudia su implantaci6n junto con los metodos de analisis sintac tico.
El manejador de errores en un analizador sintactico tiene objetivos faciles de establecer:
166
-\NALISIS SINTA('TI('O
Debe informar de la presencia de errores con claridad r exactitud.
Se debe recuperar de cada error con la suficiente rapidez como para detectar
errores posteriores.
No debe retrasar de manera signilicativva ci procesamiento de programas correctOs.
La realizacion efectiva de estos objctivos plantea desaflos importantes.
Afortunadarnente. los errores mas comunes son simples y. a menudo basta con
un mecanismo sencillo Lie manejo de errores. Sin embargo. en algunos casos un error
pudo haab er ocurrido mucho antes de la posicion en que se detecto su presencia. y puede ser mu\ dificil deducir la naturaleza precisa del error. En los casos dificiles, el
manejador de errores qui7a tenga quc adivinar que tenia en mente el programador
cuando escrihio el programa.
Varios metodos de analisis sintactico, como los metodos LL v LR. detectan un
error to antes posihle. Es decir. tienen la propic'dad del prefijo viable, lo cual quiere decir
quc. detectan la presencia de un error nada mas e'er un prefijo de la entrada que no es prefijo de ninguna cadena del lenguaje.
Ejemplo 4.1. Para comprobar la clase de errores que ocurren en la practica. se exa-
minan los errores que Ripley y Druseikis [ 19781 encontraron en una muestra de
programas en Pascal realizados por estudiantes.
Descubrieron que los errores no ocurren tan frecuentemente: el 60 por 100 de
los programas compilados era correcto sintactica y semanticamente. Aun cuando
hahia errores, estos estahan hastante dispersos: el 80 por 100 de las proposiciones con errores solo tenia un error. v el 13 por 100, dos. Por ultimo. la mayoria eran
errores triviales: el 90 por 100 eran errores de un componente lexieo.
\tuchos de los errores se podrian clasificar simplemente: 60 por 100 eran errores
de puntuacion. el 20 por 100 eran errores de operador y operando. el 1 5 por 100.
errores de palabras clave. Y el restante 5 por 100, de otras clases. La mayoria de los
errores de puntuacion giraha alrededor del use incorrecto del punto y coma. Como ejemplo concreto. considerese el siguiente programa en Pascal.
(I )
(2)
program impmax(input, output);
var
(3) (4)
x, y: integer; function max(i:integer; j:integer) : integer; idevuelve el mdximo de los enteros iy j}
begin if i > j then max := i
(5)
(6) (7)
(8)
else max
:= j
(9)
(10) ( 1 1)
end;
begin
readin (x, y) ;
(I ?)
(1 3) end.
writeln (max(x,y) )
4.1
EL PAPEL DEL ANALIZADOR SINTACTICO
167
Un error de puntuacion frecuente es usar una coma en lugar del punto y coma en la
lista de argumentos de una declaracion de funcion (por ejemplo. usar una coma
en Lugar del primer punto y coma en la linea (4)): otro es no poner un punto y coma
obligatorio al final de una linea (por ejemplo, el punto y coma del final de la Iinea
(4)); otro es poner un punto y coma indebido al final de una linea antes de un else (por ejemplo. poner un punto v coma at final de la linea (7)).
Tal vez los errores de punto y coma son tan comunes porque el use del punto y
coma varia mucho de un lenguaje a otro. En Pascal. tin punto y coma es un sepa-
rador de proposiciones; en PL/ I y en C. termina una proposicion. Algunos estudios
han sugerido que este ultimo use es menos propenso a errores (Gannon y Horning
[1975]).
: _. Los errores de escritura de Las palabras clave son bastante raros. pero un ejemplo
Un ejemplo tipico de un error de operador es no poner los dos puntos en
ilustrativo es olvidar la i en writein.
Muchos compiladores de Pascal no tienen dificultades para manejar errores comunes de insercion, borrado y mutacion. De hecho, varios compiladores de Pascal compilaran correctamente el programa anterior con un error comun de puntuac16n o de operador: emitiran solo un diagnostico de advertencia. sehalando la construccion erronea. Sin embargo. hay otra clase habitual de error mucho mas dificil de reparar
correctamente: no poner un begin o un end (por ejemplo. la omision de la Iinea
(9)). La mayoria de los compiladores no intentaria reparar esta clase de error.
j,C6mo debe informar un manejador de errores de la presencia de un error? Al
menos debe informar del lugar en el programa fuente donde se detecta el error. porque es muy probable que el error real se haya producido en alguno de los componentes lexicos anteriores. Una estrategia comun empleada por muchos compiladores es imprimir la linea erronea con un apuntador a la posicion donde se detecta el error. Si hay una posibilidad razonable de saber cull es realmente eel error, tambien
se incluye un mensaje de diagnostico informativo y comprensible; por ejemplo. "talta
punto y coma en esta posicion".
Una vez detectado el error. -,como se debe recuperar el analizador sintactico?
Como se vera. existen varias estrategias gencrales. pero ningun metodo es clara-
mente superior. En la mayoria de los casos, no es adecuado que el analizador sintactico abandone despuds de detectar el primer error. porque el posterior
procesamiento de la entrada podria revelar mas errores. Normalmente. hay alguna
forma de recuperaci6n del error donde el analizador sintactico intenta volver 0
mismo a un estado en el que el procesamiento de la entrada pueda continuar con una esperanza razonable de que se hard el analisis de la entrada correcta o de que sera manejada correctamente por el compilador.
Una recuperaci6n inadecuada puede introducir una avalancha abrumadora de errores "espurios". no cometidos por el programador. sino introducidos por los
cambios hechos al estado del analizador sintactico durante la recuperaci6n del error. De forma similar. la recuperaci6n del error sintactico puede introducir errores semanticos espurios que mas tarde detectaran las fases de analisis semantico o de generacion de codigo. Por ejemplo. al recuperarse de un error. el analizador sintactico
168
AN, LISIS SIN"1 A(TICO
puede haber omitido una declaracion de alguna variable, por ejemplo zap. Cuando luego se encuentra zap en expresiones, nada es sintdcticamente incorrecto, pero como no hay una entrada en la tabla de simbolos para zap, se genera el mensaje zap indetinida". Una estrategia conservadora pars un compilador es inhibir los mensajes de error que provengan de errores descubiertos demasiado cerca unos de otros en la cadena de entrada. Despues de descuhnr un error sintactico, el compilador podria exigir que varios componentes lexicos se analizardn sintacticamente con exito antes de permi-
tir otro mensaje de error. En algunos casos, puede haber demasiados errores como
para que el compilador continue un procesamiento razonable. (Por ejemplo, Lcomo
debe responder un compilador de Pascal a un programa en FORTRAN como entrada?) Parece que una estrategia de recuperacion de errores tiene que ser un com-
promiso cuidadosamente considerado, teniendo en cuenta las clases de errores que
se pueden presentar y que sean de procesamiento razonable.
Como ya se ha mencionado, algunos compiladores intentan reparar el error, proceso en el cual el compilador intenta adivinar lo que pretendia escribir el progra-
mador. El compilador de PL/C (Conway y Wilcox [ 1973)) es un ejemplo de este
tipo de compilador. Excepto tal vez en un entorno de programas cortos escritos por estudiantes inexpertos, no es probable que la recuperacion completa de los errores sea rentable. De hecho. con la importancia creciente de la informdtica interactiva y los buenos entornos de programacion, la tendencia parece ser hacia mecanismos
sencillos de recuperacion de errores.
Estrategias de recuperacibn de errores
Hav muchas estrategias generales distintas que puede emplear un analizador sintactico para recuperarse de un error sintactico. Aunque ninguna de ellas ha demostrado ser de aceptacion universal, algunos metodos tienen una amplia aplicabilidad. Aqui se introducen ]as siguientes estrategias: en modo de panico a nivel de frase de producciones de error de correccion global RecuperaciOn en rnodo de panico. Este es el metodo mas sencillo de implantar y pueden utilizarlo la mayoria de los metodos de analisis sintactico. Al des.cubrir un error. el analizador sintactico desecha simbolos de entrada, de uno en uno, hasta que encuentra uno perteneciente a un conjunto designado de componentes lexicos de sincronizacion. Estos componentes lexicos de sincronizacion son generalmente delimitadores, coma el punto y coma o la palabra clave end, cuyo papel en el programa fuente esta claro. Es evidente que quien diserla el compilador debe seleccionar los componentes lexicos de sincronizacion adecuados para el lenguaje fuente. Aunque la correccion en modo de panico a menudo omite una cantidad considerable de entrada sin comprobar la existencia de errores adicionales, tiene la ventaja
de la sencillez y, a diferencia de otros mctodos considerados mas adelante, esta garantizado contra lazos infinitos. En situaciones en donde son raros los errores
multiples en la misma proposicion. este metodo puede resultar bastante adecuado.
4.2
GRAMATICAS INDEPENDIE N'T FS DEL C'ON,TC X I O
169
Recuperacion a nivel de Jrase. Al descubrir un error, el analizador sintactico puede realizar una correccion local de la entrada restante; es decir. puede sustituir un prefijo de la entrada restante por alguna cadena que permita continuar al analizador sintactico. Una correccion local tipica seria sustituir una coma por un punto y coma, suprimir un punto y coma sobrante, o insertar un punto y coma que falta. La eleccion de la correccion local corresponde al disehador del compilador. Por supuesto, se debe tener cuidado de elegir sustituciones que no conduzcan a lazos infinitos, como seria el caso. por ejemplo, si siempre se insertara algo en la entrada por delante del simbolo de entrada en curso. Este tipo de sustitucion puede corregir cualquier cadena de entrada y ha sido empteado en varios compiladores que corrigen los errores. El metodo se us6 por primera vez en el analisis sintactico descendents. Su principal desventaja es su dificultad pars afrontar situaciones en que el error real se produjo antes del punto de deteccion. Producciones dc' error. Si se tiene una buena idea de los errores comunes que pueden encontrarse, se puede aumentar la gramatica del lenguaje con producciones que
generen las construcciones erroneas. Entonces se usa esta gramatica aumentada
con las producciones de error para construir el analizador sintactico. Si el analizador
sintactico usa una produccion de error, se pueden generar diagnbsticos de error apropiados para indicar la construcci6n err6nea reconocida en la entrada. C'orreeciOOn global. Idealmente, seria deseable que un compilador hiciera el minimo de cambios posibles at procesar una cadena de entrada incorrecta. Existen algoritmos para elegir una secuencia minima de cambios para obtener una correccion global de menor costo. Dada una cadena de entrada incorrecta x y la gramatica G.
estos algoritmos encontraran un arbol de analisis sintactico para una cadena relacionada ti', tal que el numero de inserciones, supresiones y modificaciones de componentes lexicos necesario para transformar x env sea el minimo posible. Por desgracia, la implantacion de estos metodos es en general demasiado costosa en terminos de tiempo y espacio, asi que estas tecnicas en la actualidad solo son de interes te6rico.
Se debe sehalar que un programa correcto mas parecido at original puede no ser to
que el programador tenia en mente. Sin embargo, la nocion de correccion de costo minimo proporciona una escala para evaluar las tecnicas de recuperacion de errores, y se ha usado para encontrar cadenas de sustitucion optimas para la recuperacion a nivel de
frase.
4.2 GRAMATICAS INDEPENDIENTES DEL CONTEXTO Muchas construcciones de los lenguajes de programaci6n tienen una estructura inherentemente recursive que se puede definir mediante gramaticas independientes del contexto. Por ejemplo, se puede tener una proposicion condicional definida por una regla como
Si S, y S, son proposiciones y F. es una expresi6n. entonces "if f; then S, else S," es una proposici6n. (4.1)
170
ANAI.ISIS SINI-ACTICO
No se puede especificar esta forma de proposicion condicional usando la notacion de
las expresiones regulares: en el capitulo 3 se vio que las expresiones regulares puc den
especificar la estructura lexicografica de los componentes ldxicos. Por otro lado,
utilizando la variable sintactica prop pars denotar la clase de las proposiciones y expr para la clase de las expresiones. ya se puede expresar (4.1) usando la produccion gramatical
prop --* if e. pr then prop else prop
(4.2)
En esta seccion se revisa la definicion de una gramatica independiente del contexto y se introduce terminologia para el analisis sintactico. Segun la seccibn 2.2.
una gramatica independiente del contexto (gramatica, per brevedad) consta de terminales. no terminales. un simbolo inicial y producciones. 1 . Los terminates son los simbolos basicos con que se forman las cadenas. "Componente lexico" es un sinonimo de "terminal" cuando se trata de gramaticas para lenguajes de programacidn. En (4.2). cads una de las palabras clave if. then y else
es un terminal.
?. Los no terminales son variables sintacticas que denotan conjuntos de cadenas. En (4.2), prop y (x pr son no terminales. Los no terminales definen conjuntos de cadenas que ayudan a definir el lenguaje generado per la gramatica. Tambien imponen una estructura jerarquica sobre el lenguaje que es titil tanto para
el analisis sintactico como para la traduccion. 3. En una gramatica, un no terminal es considerado corno el simbolo inicial, y el
conjunto de cadenas que represents es el lenguaje definido por la gramatica. 4. Las producciones de una gramatica especifican como se pueden combinar los terminales y los no terminales pars formar cadenas. Cada produccion consta de
un no terminal, seguido per una flecha (a veces se usa el simbolo en lugar de la flecha), seguida per una cadena de no terminales y terminales. Ejemplo 4.2. La gramatica con las siguientes producciones define expresiones aritmeticas simples.
e pr - expr op expr expr -- ( expr ) expr --+ - expr e v pr - id op -+ +
op -.3 ---
op - * op --/ op --T
En esta gramatica, los simbolos terminales son id + - */T( ) Los simbolos no terminales son expr y op, y expr es el simbolo inicial. lf
4.2
GRAMA FKC'AS INDEPENDIENTES DEL coNTEX ro
171
Convenciones de notacion
Para evitar tener que establecer siempre que "estos son los terminales". "estos son
los no terminales", etcetera. a partir de ahora se emplearan las siguientes convenciones de notacion con respecto a las gramaticas. 1 Estos si m bolos son terminales:
a) Las primeras letras minusculas del alfabeto. como ct. h. c.
b) Los simbolos de operador. como +. -. etcetera.
c) Los simbolos de puntuacion. coma parentesis. coma. etcetera.
d) Los digitos (1, 1 ..... 9.
e) Cadenas en negritas, como id o if. 2. Estos simbolos son no terminales:
a) Las primeras letras mayusculas del alfabeto. como.-1. 13, C.
b) La tetra S. que cuando aparece suele ser el simbolo inicial.
c) Los nombres en cursivas minusculas, como c'tpr o prop.
3. Las tiltimas letras mavtisculas del alfabeto. como X. V. /. representan .cim olo.c grurnaiicale.s, es decir. terminales o no terminales.
4. Las tiltimas tetras minusculas del alfabeto. principalmente U. v, ............. -, represen-
tan cadenas de terminales. 5. Las letras griegas minusculas, a, f , y, por ejemplo. representan cadenas de simbolos gramaticales. Por tanto, una produccion gencrica podria escrihirse ;1 --), a.
indicando quc hay un solo no terminal .-i a la izquierda de la flecha (el /ado i. quierclo de la produccion) y una cadena de simbolos gramaticales a a la dereeha de la
flecha (el lade derecho de la produccl6n ). 6. Si .4 -+ a,.A -+ a,, ............ A -* aA son todas producciones. con .1 a la izquierda (se les llama producciones de.-O. se puede eseribir.4 - a, I a, ... i a4. a, , a: .............. se denominan alternatira. de.-I. simbolo inicial. Ejemplo 4.3. Usando estas ahreviaturas, se podria escrihir en forma concisa la gra-
7. A menos que se digs otra cosa. el lado izquierdo de la primera produccion es el
matica del ejemplo 4.2 como
Las convenciones de notacion indican que E y A son no terminales. con E como
E--.* EAEI(E)I -- EIid + -- * / I I H IT
simbolo inicial. El resto de los simbolos son terminales. Derivaciones
C)
Hav 'arias formas de considerar el proceso mediante el cual una gramatica define un
lenguaje. En la seccion 2.2 se considero este proceso como el de construccion de arboles de analisis sintactico, pero existe tambien una vision derivative relacionada que suele resultar titil. De hecho. esta vision derivativa da una descripciOn precisa
172
AtiALISIS SIN I AC'TICo
de la construccion descendente de un arbol de analisis sintactico. La idea central es que se considers una produccion como una regla de reescritura. donde el no termi-
nal de la izquierda es sustituido por la cadena del ]ado derecho de la produccion.
Por ejemplo. considcrese la siguiente gramatica Para expresiones aritmeticas.
donde el no terminal F; representa una expresion.
E--E + E+E E I ( E ) I - EIid (4.3)
La produccion 1: + - F; significa que una expresion precedida por un signo menos es tambien una expresion. Esta produccion se puede usar Para generar expresiones mss complejas a partir de expresiones mss simples permitiendo sustituir cualquier
presencia de 1: por -- E. En el caso mss simple. se puede sustituir una sola 1: por
- E. Se puede describir esta accion escribiendo
1: -F
-p
que se lee "E deriva - E". La produccion E
(1:) establece que tambien se podria
sustituir una presencia de una E en cualquier cadena de simbolos gramaticales por (E)*E o E*E E*(I: ). (F): por ejemplo. E*E
Se puede tomar una cola E. y aplicar repetidamente producciones en cualquier orden Para obtener una secuencia de sustituciones. Por ejemplo. E=:> -E
-- (E)=:> -(id)
A dicha secuencia de sustituciones se le llama derivaeivn de - (id) a partir de E. Esta
derivacion proporciona una prueba de que un caso determinado de una expresion
es la cadena - (id).
De forma mss abstracta, se dice que a..40
av
ayf. si .a -- y es una produccion v
a= an. se
R son cadenas arbitrarias de simbolos gramaticales. Si a,
significa "deriva en un Paso". A menudo se dice que a, deriva a a,,. El simbolo desea decir "deriva en cero o mss pasos". Para este proposito se puede usar el
simbolo*. Asi: l . a a Para cualquier cadena a*y
?. Sia
0 v0=::* y. entonces a =:> y.
Del mismo modo se puede usar = para expresar "deriva en uno o mss pasos" Dada una gramatica G con simbolo inicial S, se puede utilizar la relacion
Para def i n i r L(G ), el lenguaje generado por G. Las cadenas de 1.(G) pueden contener solo simbolos terminales de G. Se dice que una cadena de terminales w esta en L(G) si,
VV solo si, S Hw. A la cadena vv se le llama rase de G. De un lenguaje que pueda ser generado por una gramatica se dice que es un lenguaje independiente del conte.vto. Si dos gramaticas generan el mismo lenguaje, se dice que son equivalentes. Si Spa. donde a puede contener no terminales. entonces se dice que a es una lurma dc' (rase de G. Una frase es una forma de frase sin no terminales. Ejemplo 4.4. La cadena - (id + id) es una frase de la gramdtica (4.3). porque existe la derivacion E=:o, -E-(E)=-(E+E) => -(id+E)=-(id+id) (4.4)
4.2 GRAMATICAS INDEPENDIE:NTES DEL CONTEXTO
173
Las cadenas E. -- E, - (E ) ...... (id + id) que aparecen en esta derivacion son todas formas de (rases de esta gramatica. Se escribe E> (id + id) para indicar que
-- (id id) se puede derivar de E. Se puede demostrar por induccion sobre la longitud de una derivacion que toda frase del lenguaje de la gramatica (4.3) es una expresion aritmetica que comprende a los operadores binarios + v *, al operador unario -, parentesis y al operando id. De
manera similar, se puede demostrar por induccion sobre la longitud de una expresion aritmetica que todas estas expresiones pueden ser generadas por esta gramatica. Asi, la gramatica (4.3) genera precisamente el conjunto de todas las expre-
siones aritmeticas que comprenden a los binarios tesis y al operando id.
+ y *, al - unario. a los parenEl
En calla paso de una derivacion hay que hacer dos elecciones. Es necesario escoger que no terminal se debe sustituir v. una vez hecha esta eleccion, que alternativa usar para este no terminal. Por ejemplo, la derivacion (4.4) del ejemplo 4.4 podria continuer desde - (E+ E) como sigue
- (E+ E - (E id) - (id id)
(4.5)
Se sustituye cada no terminal de (4.5) por el mismo lado derecho que en el ejemplo 4.4, pero el orden de sustitucion es diferente. Para comprender como trabajan algunos analizadores sintacticos, hay que considerar derivaciones donde tan solo el no terminal de mis a la izquierda de cualquier forma de frase se sustituya a cada paso. Dichas derivaciones se denominan por
la i:quierda. Si a- ->p un paso en el que se sustituye el no terminal mas a la izquierda de a. se escribe a= >P. Puesto que la derivacion (4.4) es por la izquierda, se puede escribir asi:
1: -E -(E)= -(E+E)=> -(id+E)=::o. -(id+id)
P111
MI
MI
Usando las convenciones de notacion, todo paso por la izquierda se puede escribir vvAy vvSy,, donde w consta solo de terminales..A --). S es la produccion aplicada y y es una cadena de simbolos gramaticales. Para subrayar el hecho de que a deriva a por medio de una derivacion por la izquierda, se escribe a+ 3. Si S4a, entonces Se dice que a es una firma de_lrase is quierda de la gramatica en cuestion. Analogas definiciones se aplican a ]as derivaciones derecha.i, donde el no terminal
mas a la derecha se sustituye en cada paso. Las derivaciones derechas a menudo se denominan derivaciones canonicas. Arboles de analisis sintactico y derivaciones Un arbol de analisis sintactico se puede considerar como una representaciOn grafica
de una derivacion que no muestra la eleccidn relativa al orden de sustitucion. Como
se vio en la seccibn 2.2, cada nodo interior de un arbol de analisis sintactico se etiqueta con algun no terminal A, y que los hijos de ese nodo se etiquetan, de izquierda a
derecha, con los simbolos del lado derecho de la produccibn por la cual se sustituye esta A en la derivacion. Las hojas del arbol de analisis sintactico se etiquetan
174
ANALISIS SI`T ACI IC'O
con terminales o no terminales v. leidas de izquierda a derecha, constituyen una forma de frase, llamada el producto o frontera del drbol. Por ejemplo, en la figura 4.2 se muestra el arbol de analisis sintactico para - (id + id) indicado por la derivacion (4.4). Para ver la relaciOn entre derivaciones y Arboles de analisis sintactico, considerese cualquier derivacion a,=:*a2=> ...=> a,,, donde 'a, es un solo no terminal A. Para cada forma de (rase a, de la derivacion, se construye un arbol de analisis sin-
tactico cuyo producto es a,. El proceso es una induccion sobre I. Para la base, el arbol para a, - .-I es un solo nodo etiquetado con A. Para hacer la induccion, supon gase
que ya se ha construido un arbol de analisis sintactico cuvo producto es a, = X,X ......... l'. (Recordando las convenciones, cada X, es o un terminal o un no terminal.) Supongase que a, Sc deriva de a, , sustituyendo X,, que es un no terminal. por a = Y, Y, ... Y,. Es decir, en el i-esimo paso de la derivacion, la produccion X, -+
0 se aplica a a, , para dcrivar a, _ .t',A', . . . X,-,13X,., ... X,-.
Para modelar este paso de la derivacidn, hay que encontrar la j-esima hoja por la izquierda en el arbol de analisis sintactico en curso. Esta hoja esta etiquetada con X,. A esta hoja se le asignan r hijos, etiquetados con Y,, Y:, ... , Y, desde la izquierda.
Como caso especial. si r = 0. es decir. hijo etiquetado con e.
R = f, entonces a la j-dsima hoja se le asigna un
Fig. 4.2. Arbol de analisis sintactico para
- (id - id).
Ejemplo 4.5. Considerese la derivacion (4.4). La secuencia de arboles de analisis sintactico construidos a partir de esta derivacion se muestra en la figura 4.3. En el primer paso de la derivacion, E=> E. Para modelar este paso, se ahaden dos hijos,
etiquetados con - y con E. a la raiz E del arbol inicial para crear el Segundo drbol.
En el segundo paso de la derivacion,
- F.=:> - (E). En consecuencia, se araden
tres hijos, etiquetados con (. E y ). a la hoja etiquetada con E del segundo arbol para
obtener cal tercer arbol con producto - (E). Si se continua asi se obtiene el drbol de Cl analisis sintactico completo como sexto arbol.
Como ya se ha mencionado, un arbol de analisis sintactico ignora las variaciones en
el orden en que se sustituyen los simbolos en las formas de frases. Por ejemplo,
si se continuara la derivacion (4.4) como en la linea (4.5), daria como resultado el
4.2
GRAMA FIC'AS INDLPENEIF NTES DEL. CONTEXTO
175
E E
E E
/ I \
/ 1
+ F_
Fig. 4.3. Construccion del arbol de analisis sintactico a partir de la derivaci6n (4.4).
mismo arbol de analisis sintactico final de la figura 4.3. Tambien se pueden eliminar estas variaciones en el orden en que se aplican las producciones si se consideran unicamente derivaciones por la izquierda (o por la derecha). No es diticil ver que todo arbol de analisis sintactico tiene asociado una tinica derivacion izquierda v una unica derivaci6n derecha. En lo que sigue. a menudo se hard el analisis sintactico produciendo una derivaci6n por la izquierda o por la derecha. sabiendo que en lugar de esta derivaci6n se podria producir el propio arhol (le analisis sintactico. Sin embargo, no se debe suponer que toda frase tiene ohligatoriamente un solo arbol de analisis sintactico o una sola derivaci6n por la izquicrda o por la derecha. Fjemplo 4.6. Se considera de nuevo la gramatica (4.3) de expresiones aritmeticas. La frase id + id*id tiene las dos claras derivaciones por la izquierda:
E=E+E
=id+E =id+E*E
E=E*f:
=> E+E*F. =id+E*E
id + id*K
= id + id*L
id + id*id
= id + id*id
con los dos arboles de analisis sintactico correspondientes que se muestran en la figura 4.4. Observese que el arbol de analisis sintactico de la figura 4.4(a) refleja la precedencia comunmente aceptada de + Es decir, es habitual considerar que el operador * tiene mayor precedencia que + . lo cual corresponde al hecho de que una expresion como a+ h*c normalmente se
y *, mientras que el arbol de la figura 4.4(b) no.
evaluaria como a + (h*c), en lugar de Como (a + h)*c.
176
ANAL.ISIS SINTACTICO
F' x I "'
E id
+ f_'
id
(a)
E E
id (b)
Fig. 4.4. Dos arboles de analisis sintactico para id + id*id.
Ambiguedad Se dice que una gramatica que produce mas de un arbol de andlisis sintactico para alguna frase es amhigua. 0, dicho de otro modo, una gramatica ambigua es la que produce mas de una denvacion por Ia izquierda o por la derecha para la misma frase. Para algunas tipos de analizadores sintacticos es preferible que la gramatica no sea ambigua, pues si to fuera, no se podria determinar de manera exclusiva qu6 arbol de analisis sintactico seleccionar para una frase. Para algunas aplicaciones se consideraran tambien los metodos mediante los cuales se puedan utilizar ciertas gramaticas ambiguas. junto con reglas para eliminar ambiguedades que desechan arboles de analisis sintactico indeseables, dejando solo un arbol para cada (rase.
4.3 ESCRITURA DE ULNA GRAMIATICA Las gramaticas son capaces de describir la mayoria, pero no todas. de las sintaxis de los lenguajes de programacion. Un analizador lexico efectda una cantidad limitada de analisis sintactico conforme produce la secuencia de componentes lexicos a partir de los caracteres de entrada. Ciertas limitaciones de la entrada, como el requisito de que los identificadores se declaren antes de ser utilizados, no pueden describirse mediante una gramatica independiente del contexto. Por tanto, las secuencias de componentes lexicos aceptadas por un analizador sintactico forman un superconjunto de un lenguaje de programacion; las faces posteriores deben analizar la salida del analizador sintactico para garantizar la obediencia a reglas que el analizador sintac tico
no comprueba. (Vease Cap. 6.)
Esta seccion se- inicia considerando la division del trabajo entre un analizador lexico v un analizador sintactico. Puesto que cads metodo de analisis sintactico puede manejar solo gramaticas de una cierta forma, quita se deba reescribir la gramatica inicial para hacerla analizable por el metodo elegido. A menudo se pueden construir gramaticas adecuadas para expresiones utilizando la informacion acerca de la asociatividad y la precedencia, como en la seccibn 2.2. Aqui, se consideran transformaciones Wiles para reescribir gramaticas y hacerlas apropiadas para el analisis sin-
tactico descendente. Esta seccion concluye considerando algunas construcciones de
los lenguajes de programacion que no pueden ser descritas por ninguna gramatica.
4.3
ESCRITURA DE UNA GRAMATICA
177
Expresiones regulares, o gramaticas independientes del contexto Toda construccion que se pueda describir mediante una expresion regular tambien se puede describir por medio de una gramatica. Por ejemplo, la expresion regular (alb)*ahh y la gramatica
AO -+aAOI hAoIa.A, A, - hA2 .42-bA3 .4z -- f
describen el mismo lenguaje, el conjunto de cadenas de caracteres a y h que termi nan en
abb.
Se puede convertir de manera mecanica un automata finito no determinista (AFv) en una gramatica que genere el mismo lenguaje reconocido por el AFN. La gramatica anterior se construyb a partir del AFB de la figura 3.23 utilizando la siguiente construccion: para cada estado i del AFN, creese un simbolo no terminal A,. Si el
estado i tiene una transicion al estado j con el simbolo de entrada a. introduzcase la produccibn A, aA,. Si el estado i va al estado.j con la entrada e, introduzease la produccion .4 --+ A,. Si i es un estado de aceptacion, introdUzcase A, --> F, Sj i es el estado de inicio. hacer de A, el simbolo inicial de la gramatica. Puesto que todo conjunto regular es un lenguaje independiente del contexto, es
razonable preguntar: ZPor que utilizar expresiones regulares para definir la sintaxis
lexicografica de un lenguaje? Existen varias razones. 1. Las reglas lexicograficas de un lenguaje a menudo son bastante s.encillas, v para describirlas no se necesita una notaciOn tan poderosa como las gramaticas. 2. Las expresiones regulares por lo general proporcionan una notacion mas concisa y facil de entender para los componentes lexicos que una gramatica.
3. Se pueden construir automaticamente analizadores lexicos mas eficientes a partir de expresiones regulares que de gramaticas arbitrarias. 4. Separar la estructura sintactica de un lenguaje en partes lexicas y no lexicas pro-
porciona una forma conveniente de modularizar la etapa inicial de un compilador en dos componentes de tamaho razonable. No existen normas fijas en cuanto a que poner en las reglas lcxicograficas, en vez de
las reglas sintacticas. Las expresiones regulares son muy utiles para describir la
estructura de las construcciones lexicas, como identificadores. constantes. palabras
slave. etcetera. Las gramaticas, por otra pane, son muy Wiles para describir estruc turas
anidadas, como parentesis equilibrados, concordancia de las palabras clave begin y, end, los correspondientes if-then-else, etcetera. Como ya se ha sehalado, estas estructuras anidadas no se pueden describir con expresiones regulares. Comprobacidn del lenguaje generado por una gramatica
Aunque los diserladores de compiladores rara vez to hacen para una gramatica completa de un lenguaje de programacion, es importante ser capaz de razonar que un conjunto dado de producciones genera un lenguaje determinado. Las construccio-
178
ANALISIS SINT.NCTIC'O
nes problematicas se pueden estudiar escribiendo una gramatica abstracta concisa y estudiando el lenguaje que genera. Mas adelante se construira una de estas gramaticas para los condicionales. Una prueba de que una gramatica G genera u n lenguaje L tiene dos parses: se debe demostrar que toda cadena generada por G esta en L, y lo opuesto, que toda cadena de L puede de hecho ser generada por G. Ejemplo 4.7. Considerese la gramatica (4.6)
S -> (.S)S t E
(4.6)
Al principio puede no resultar evidente. pero esta simple gramatica genera todas las cadenas de parentesis equilibrados y solo estas cadenas. Para comprobarlo, primero se
demostrara que toda frase derivable de S esta equilibrada, y despues, que toda
cadena equilibrada es derivable de S. Para demostrar que toda (rase derivable de S
esta equilibrada, se usa una prueba inductiva sobre el numero de pasos de una derivacion. Para el paso base, se observa que la unica cadena de terminales derivable
de S en un paso es la cadena vacia, que sin duda esta equilibrada.
Ahora, supongase que todas las derivaciones de menos de n pasos producen frascs equilibradas y considerese una derivacion por la izquierda de exactamente n pa-
sos. Dicha derivacion debe tener la forma S =(S)S (x)S
W)
Las derivaciones de x e y a partir de S ocupan menos de n pasos, de modo que, por la
hipotesis de inducci6n, x e Y estAn equilibradas. Por tanto, la cadena (x)j7 debe estar equilibrada. Se ha demostrado asi que cualquier cadena derivable de S esta equilibrada. A
continuacion se debe demostrar que toda cadena equilibrada es derivable de S. Para
hacerlo. se utiliza inducci6n sobre la longitud de una cadena. Para el paso base, la
cadena vacia es derivable de S. Ahora, supongase que toda cadena equilibrada de longitud menor que 2n es de-
rivable de S y considerese una cadena equilibrada it, de longitud 2n, n > 1. Sin duda. it,
comienza con un parentesis izquierdo. Sea (x) el prefijo mas corto de w que tenga un numero igual de parentesis izquierdos N. derechos. Entonces w se puede escribir (.v)v.
donde tanto x como v estan equilibrados. Puesto que x e v son de longitud menor que 2n. son derivables de S por la hipotesis de induccion. Por canto. se puede encontrar una derivacion de la forma S
(.S)S
(x)S
(x)i
to dual demuestra que w = (x)v tambien es derivable de S.
Supresion de la ambiguedad A veers, una gramatica ambigua se puede reescribir para eliminar la ambiguedad.
Como ejemplo. se eliminara la ambiguedad de la siguiente gramatica con "else ambiguo":
4.3
FSCRI 1 URA DID. (."NA GRAMATICA
179
prop --* if etpr then prop
if a yr then prop else prop
ofra
(4.7)
Aqui, otra represents cualquier otra proposicion. De acuerdo con esta gramatica. la proposicion condicional compuesta if l:, then S, else if E then S. else S1
tiene el arbol de analisis sintactico que se muestra en la figura 4.5. La gram itica (4.7) es
amhigua, puesto que la cadena if 1:; then if E, then .S, else S
tiene los dos arholes de analisis sintactico que se muestran en la figura 4.6.
prt,p
(4.8)
if
expr
then prOOt) S,
if
else
prop
E,
prop then
E2
prop
else pr( )p
S,
S2
Fig. 4.5. Arbol de analisis sintactico para la proposicion condicional.
prop
if
expr then prop
If
prop
then
prop
else
prop
S2
Ez
prop
S,
if
expr then prop else prop
if
expr then prop
L\ [_
E2
S,
Fig. 4.6. Dos arboles de analisis sintactico para una (rase ambigua.
180
ANALIS1S SINTACTICO
En todos los lenguajes de programacion con proposiciones condicionales de esta forma, se prefiere el primer arbol de analisis sintactico. La regla general es, "emparejar cada else con el then sin emparejar anterior mas cercano". Esta regla Para eliminar ambiguedades se puede incorporar directamente a la gramatica. Por ejemplo. se puede reescribir Ia gramatica (4.7) como Ia siguiente gramatica no ambigua. La idea es que una proposicion que aparezca entre un then y un else debe estar "emparejada", es decir, no debe terminar con un then sin emparejar seguido de cualquier proposicion, porque entonces el else estaria obligado a concordar con este then no emparejado. Una proposicion emparejada es o una proposicion if-then-else que
no contenga proposiciones sin emparejar o cualquier otra clase de proposicion no
condicional. Asi, se puede utilizar Ia gramatica prop -p prop- emparejada
pro_ no_empure jada prop_emparcjada -* if erpr then prop_emparcjada else prop_emparcjada
otra prop- no_emparejada
- if expr then prop
(4.9)
if expr then prop_emparejada else prop_no_emparejada Esta gramatica genera el mismo conjunto de cadenas que (4.7), pero permite solo
un analisis sintactico Para Ia cadena (4.8), es decir, el que asocia cada else con el
then sin emparejar anterior mas cercano.
Eliminacion de Ia recursion por Ia izquierda
Una gramatica es recur-viva por la izquierda si tiene un no terminal .-I tal que exists una derivacion .4 =:>Aa Para alguna cadena a. Los metodos de analisis sintactico descendents no pueden manejar gramaticas recursivas por la izquierda, asi que se
necesita una transformacion que elimine Ia recursion por Ia izquierda. En la seccion
2.4 se analizo la recursion simple por Ia izquierda. donde habia una produccion de Ia forma ,4 -+ Aa. Aqui se estudia el caso general. En Ia seccion 2.4 se demostro que el par de producciones recursivas por Ia izquierda . l -+ Aa podian sustituirse por las producciones no recursivas por la izquierda
A - j3A'
sin modificar el conjunto de cadenas derivables de A. Esta regla ya es suficiente en
muchas gramaticas.
Ejemplo 4.8. Considerese la siguiente gramatica Para expresiones aritmeticas. E
T - T * F. I F. F--(E)Iid
E+TT
(4.10)
Eliminando Ia recursion directa por la i:quierda (producciones de la forma .4
a [as producciones de E y despues a las de T. se obtiene
* .9a)
4.3
ES('RI I t'R.\ 1)I: [INA 6R NI
1I('A
181
E TE
E'-)+TVIE
T - F7"
(4.1 1 )
r - *Fr F(E)Iid
Independientemente de cuantas producciones de .A existan, se puede eliminar de
ellas la recursion directa por la izquierda mediante la siguiente tecnica. Arimero se agrupan ]as producciones de .-1 en la forma
A -+ Au, .-1 por
1.4a, I ... I .1a 1
P,
1 P21 ... I p
donde ninguna
a, comienza con una A. I)espues se sustituven las produccioncs de
.a' I E
.I'
A' a, A'
El no terminal A genera las mismas cadenas que antes, pero ya no es recursivo por la izquierda. Este procedimiento elimina toda la recursion inmediata por la izquierda de [as producciones A y A' (suponiendo que ning0n a, es E ). pero no eli-
mina la recursion por la izquierda que incluya derivaciones de dos o mas pasos. Por ejemplo, considerese la gramatica
S AaIb A --), Ac Sd I E
recursivo inmediato por la izquierda.
(4.12)
El no terminal S es recursivo por la izquierda. porque S =:>.la =Sda, pero no es El algoritmo 4.1, eliminar sistematicamente la recursion por la izquierda de una
gramatica. Siempre funciona si la gramatica no tiene ciclos (derivaciones de la forma A
A) o producciones e (producciones de la forma A + t). Los ciclos, al igual
que las producciones f., se pueden eliminar sistematicamente de una gramatica
(veanse Ejercicios 4.20 y 4.22).
Algoritmo 4.1. Eliminacion de la recursion por la izquierda.
F,'nlrada. La gramatica G sin ciclos ni producciones .
Salida. Una gramatica equivalente sin recursion por la izquierda.
1 . Ordenense los no terminates en un orden :t,, A2, ... , A,,.
2. fort:=Itondo
begin
forj:= I toi- I do
sustituir cada produccion de la forma A, -- A,y
por las producciones A, -> S,y I S:YI ... I Sky, donde .-1, - S. I S, ... I SA son todas las producciones actuales de A,; eliminar la recursividad inmediata por la izquierda entre las producciones de A, end Fig. 4.7. Algoritmo para eliminar la recursividad por la izquierda de una gramatica.
182
;N;\l_ISIS SIN I AC IWO
Akoldo. Apliquese el algoritmo de la figura 4.7 a G. Observese que la gramatica sin
recursividad por la izquierda resultants puede tener producciones c. (i - l)-esima iteracion del Lazo for externo en el paso 2. cualquier produccion
0
La razOn por la que el procedimiento de la figura 4.7 funciona es que despues de la
de la forma .-14 donde k < i, debe tener 1> k. Como resultado, en la siguiente iteracion. el lazo intcrno (sobre j) aumenta progresivamente el limite inferior en m hasta que se tenga in_i. Entonces, eliminar la en cualquier produccion .1
recursion directa por la izquierda de las producciones de .4, hace que arm sea mayor que
i.
Ejemplo 4.9. Aplicacion de este procedimiento a la gramatica (4.12). Desde el punto de vista tecnico. el algoritmo 4.1 no siempre funciona. debido a la produccion E.
pero en este caso la produccion .4 --> E resulta ser inofensiva.
Se ordenan los no terminales S.A. No hay recursion directa por la izquierda entre las producciones de S, de modo que no ocurre nada durante el paso 2 para el 1 . Para r caso i = 2. se sustituven las producciones de S en .4 * Sd para obtener
las siguientes producciones de.-I.
.4
-+AcI:1ad
I hdI E
Eliminando la recursion directa por la izquierda entre las producciones de.-I. se ohtiene la siguiente gramatica.
S-l .aIh
1 -. hd^1'' -T .-l' --(:-1' I adA'(
Factorizacion por la izquierda
La factorizacion por la izquicrda es una transformacion gramatical Otil para producir una gramatica adecuada para el analisis sintactico predictivo. La idea basica es que cuando no esta claro cual de dos producciones alternativas utilizar para ampliar un no terminal .4. se pueden reescribir las producciones de A para retrasar la decision hasta haber visto
lo suficiente de la entrada como para elegir la opcion correcta.
Por ejemplo, si se tienen las dos producciones prop -, if expr then prop else prop
if e v pr then prop
al ver el componente lexico de entrada if. no se puede saber de inmediato que pro1 --+ aa, ; aP2 son dos produccioduccion elegir para expandir prop. En general, si nes de .4 v la entrada comienza con una cadena no vacia derivada de a. no se sabe si
,-
expandir.4 a up, o a ap,. Sin embargo, se puede retrasar is decision expandiendo .A a a.T. Entonces, despues de ver la entrada derivada de a, s.e puede expandir A' a P, o a R,. Es decir. factorizadas por la izquierda, las producciones originales se convierten en
A' P, 1 1 2
.4 -- uA'
4.3
ESCRITUR:\ 1)F UNA GRaMA IIC
183
Algoritmo 4.2. Factorizacion por la izquierda de una gramatica. Entrada. La gramatica (:. Salida. Una gramatica equivalente factorizada por la izquierda.
.%h'iodo. Para cada no terminal A, encuentrese el prefijo a mas largo comun a dos o mas de sus alternativas. Si a s F. es decir, existe un prefijo comun no trivial. sustittiyanse todas las producciones de .-1..1 -- aa, I a0z I ... afi I y. donde y representa todas las alternativas que no comienzan con a. por
.4 -- aA' I y
A' - 01 1021. . . 1
Aqui, A' es un nuevo no terminal. Aplicar repetidamente esta transformacion hasta que
no haya dos alternativas para un no terminal con un prefijo comun.
Ejemplo 4.10. La siguiente gramatica resume el problema del else amhiguo: P ' 1 '1P I 1EtPc'P I a
E--b
(4.13)
Aqui, i. t y e representan if. then v, else; E v P representan "expresibn" y "proposicion". Factorizada por la izquierda, esta gramatica se convierte en:
P-iE:1PP'I a P' eP I e E+b
(4.14)
Asi, se puede expandir P a iEiPP con la entrada i. y esperar hasta que if.-W hava aparecido para decidir si expandir P a c'P o a e. Por supuesto, las gramaticas (4.13) y (4.14) son ambiguas, y con la entrada e. no esta claro qu6 alternativa de P se deberia
elegir. El ejemplo 4.19 analiza una mancra de solucionar este dilema. 0
Construcciones de lenguajes no independientes del contexto No debe sorprender que algunos lenguajes no puedan ser generados por ninguna
gramatica. De hecho. unas cuantas construcciones sintacticas de muchos lenguajes
de programacibn no se pueden especificar utilizando tan solo gramaticas. En esta seccibn se introducen algunas de estas construcciones usando lenguajes abstractos
sencillos pars ilustrar las dificultades.
Ejemplo 4.11. Considerese el lenguaje abstracto L, = {vw I , esta en (a b)*}. L, consta de todas las palabras compuestas por una cadena repetida de caracteres a y h
separados por una e. como aahcaah. Se puede demostrar que este lenguaje no es
independiente del contexto. Este lenguaje resume el prohlema de asegurar que los
identificadores se declaren antes de su use en un programa. Es decir. la primera de c representa la declaracibn de un identificador w. La segunda t! representa su uso. Mientras que demostrarlo esta mas ally del proposito de este libro, la falta de independencia del contexto de L, implica directamente la no independencia del
contexto de lenguajes de programaci6n como ALGOL y Pascal, que exigen decla-
184
ANALISIS SIN 1 \CTICO
racion de los identif icadores antes de su uso, y que admiten identificadores de cualquier longitud. Por esta razon. una gramatica para la sintaxis de ALGOL o Pascal no especifica los caracteres en un identificador, sino que todos los identificadores se representan en la gramatica mediante un componente lexico como id. En un compilador para un lenguaje de este tipo. la fase de analisis semAntico comprueba si los identifica-
dores han sido declarados antes de su uso.
Ejemplo 4.12. El lenguaje L') = {a"b"Y'd'" I n > 1 y m > 11 no es independiente del contexto. Es decir. L, consta de cadenas en el lenguaje generado por la expresion
regular a*b*c*d* tales que los numeros de a y c son iguales, to mismo que los numeros de h y d. (Recuerdese que a" significa a escrita n veces.) L2 resume el pro-
blema de comprobar si el numero de parametros formales en la declaracion de un
procedimiento coincide con el numero de parametros actuales en un use de este
procedimiento. Es decir, a" y b'" podrian representar las listas de parametros formales en dos procedimientos con n y in argumentos, respectivamente. Entonces,
v d"' representan las listas de parametros reales en liamadas a dichos procedimientos.
De nuevo, se observa que la sintaxis tipica de las definiciones y usos de procedimientos no se ocupa de contar el numero de parametros. Por ejemplo, la proposicion CALL en un lenguaje del tipo FORTRAN se podria describir
prop -- call id (lista_etpr) 1i.sta_(vpr - lisia_evpr, , c'vpr
c'vpi
con las producciones adecuadas para evpr. Generalmente se comprueba si el nu-
mero de parametros actuales en la llamada es correcto durante la fase de analisis
scmantico.
a
Ejemplo 4.13. El lenguaje L,
= {a"b"c" n > 01. es decir, cadenas en L(a*b*c*) con
el misino nUmero de caracteres a. b y c, no es independiente del contexto. Un ejem-
plo de un programa que incluye L; es el siguiente. Los textos de tipografia utilizan
cursiva.s donde los textos corrientes utilizan el subrayado. Al convertir un archivo de
texto destinado a imprimirse en una impresora de lineas en texto adecuado para un dispositivo de fotocomposicion, hay que sustituir las palabras subrayadas por cursivas. Una palabra subrayada es una cadena de letras seguida de un mismo numero de retrocesos (caracteres de back space de ASCII) y de un numero igual de caracteres de subrayado. Si se considera a como una tetra, b como el caracter de retroceso y e como el caracter de subrayado, el lenguaje L3 representa palabras subrayadas. La conclusion es que no se puede utilizar una gramatica para describir palabras subrayadas de esta forma. Por otra parte, si se represents una palabra subrayada mediante una secuencia de triples letra-retroceso-subrayado, entonces se pueden representar las palabras subrayadas con la expresion regular (abc)*. Cl
Es interesante observar que lenguajes muy similares a L,, L2 y L, son independientes del contexto. Por ejemplo, l_', _ {wcw1e I w esta en (a I b)*}, donde wR represents una tt invertida, es independiente del contexto. Se genera por la gramatica
4.3
ESCRITURA DE UNA GRAMA I-IC'A
185
S -+ aSa I hSb I cEl lenguaje I_', = {a"b"'c" cf' t n gramatica vin > I } es independiente del contexto. con la
S -paSda.Ad A -- bile be
Asimismo. L ; = {a"h"cd"' I n > I y in >
11 es independiente del contexto. con la
gramatica S--p.18
8 + ccBd (cd
-*u..lhI ab
Por ultimo, L'; = {a"h"
S -.aSh(ah
Jn
> I } es independiente del contexto, con la gramatica
Es conveniente observar que L'z es el tipico ejemplo de lenguaje no definable por ninguna expresic n regular. Como prueba. sup6ngase que L'; fuera el lenguaje definido por una expresi6n regular. Asimismo, sup6ngase que se pudiera construir un AFD D que aceptara L'z. D debe tener un ntimero finito de estados, por ejemplo k.
Considerese la secuencia de estados s,,, s, , s,, .......... sc introducidos por D al haber
leido e. a, aa ........ , ak. Es decir. s, es el estado visitado por D al haber leido i caracteres a.
camino etiquetado a'
camino etiquetado a` N
/ camino etiquetado b`
sw Fig. 4.8. AFD D que acepta a'h' y a'b'.
Puesto que D solo tiene k estados distintos, al menos dos estados de la secuencia so,
.s,, .s' ............. , sA. deben ser el mismo, por ejemplo s, y s,. Desde el estado s una secuencia de i caracteres h 11eva a D a un estado de aceptaci6n f, ya que a'b' esta en L':. Pero entonces tamhien hay un camino desde el estado inicial so a .s, y de ahi a f etiquetado con alb', como se muestra en la figura 4.8. Por tanto. D tambien acepta alb', que no esta en L'3, contradiciendo el supuesto de que L'3 es el lenguaje aceptado por D. Coloquialmente, se dice que "un aut6mata finito no puede contar", to cual significa que un automata finito no puede aceptar un lenguaje como L'3, que le exigiria Ilevar la cuenta del numero de caracteres a antes de ver los caracteres h. Asimismo, se
dice que "una gramatica puede lievar la cuenta de dos elementos, pero no de tres", puesto que con una gramatica se puede definir L'3 pero no L.
186
NNAI ISIS Sim A(TICO
4.4 ANAL ISIS SINTACHCO DESCENDENTE En esta session se introducen las ideas basicas del analisis sintactico descendente v se enscha a construir una forma eficiente sin retroceso de un analizador sintactico
descendente llamada analizador sintactico predictivo. Se define la clase de gramaticas LW 1). a partir de las cuales se pueden construir de manera automatica analiza-
dores sintacticos predictivos. Ademas de formalizar el estudio de los analizadores
sintacticos predictivos de la session 2.4, se consideran analizadores sintacticos predictivos no recursivos. Esta session concluve con un analisis sobre la recuperacion de errores. Los analizadores sintacticos ascendentes se estudian en las secciones 4.5
a 4.7.
analisis sintactico por descenso recursivo
Se puede considerar el analisis sintactico descendente como un intento de encontrar
una derivacion por la izquierda para una cadena de entrada. Tambien se puede considerar como un intento de construir un Arbol de analisis sintactico para la entrada
comenzando desde la raiz v creando los nodos del arbol en orden previo. En la seccion 2.4 se estudio el caso especial del analisis sintactico por descenso recursivo. Ilamado analisis sintactico predictivo. donde no se necesita retroceso. Ahora se considers una forma general de analisis sintactico descendente. denominado por descenso recursivo.
que puede incluir retrocesos. es decir. varios examenes de la entrada. Sin embargo. no hay muchos analizadores sintacticos con retroceso. En parse. porque casi nunca se
necesita el retroceso para analizar sintacticamente las construcciones de los lenguajes
de programacion. En casos como el analisis sintactico del lenguaje natural. el retroceso tampoco es muy eficiente, v se prefieren los metodos tahulares. como el algoritmo de programacion dinamica del ejercicio 4.63 o el metodo de Ear ley [ 19701. Vease en Aho y Ullman [ 1972b] una descripcibn de metodos generales de analisis sintactico.
En el siguiente ejemplo. el retroceso es necesario. y se sugiere una forma de no perder la entrada cuando tiene lugar el retroceso. Ejemplo 4.14. Considerese la gramatica
S -+ c A d
A--pab a (4.15)
v la cadena de entrada w = cad. Para construir un arbol de analisis sintactico descendente para esta cadena. primero se crea un arhol formado por un solo nodo etiquetado con S. Un apuntador a la entrada apunta a c. el primer simbolo de w. Despues se utiliza la primera produccion de S para expandir el arbol y obtener el arbol de la figura 4.9(a).
Se empareja la hoja situada mss a la izquierda, etiquetada con c. con el primer
simbolo de iv. v a continuacion se aproxima el apuntador de entrada a a. el Segundo simbolo de it-, v Sc considera la siguiente hoja etiquetada con A. Entonces se puede
expandir.-t utilizando la primera alternativa de A para obtener el arbol de la figura
4.9(h). Como va se tiene una concordancia para el segundo simbolo de la entrada se Ileva
el apuntador de entrada a cl. el terser simbolo de la entrada. v se compara d
4.4
ANALISIS S(NTACT1CO DESC'ENDEN I E
187
S
c.
u
(a)
b (b)
Fig. 4.9. Pasos en el analisis sintactico descendente.
con la hoja siguiente. etiquetada con b. Como b no concuerda con d, se indica fallo y se
regress a .4 para saber si existe otra alternativa de .4 que no se haya intentado. pero que pueda dar lugar a un emparejamiento.
Al regresar a A, sc debe restablecer el apuntador de entrada a la posicion 2. aqueIla que tenia al it a .4 por primera vez. lo cual significa que el procedimiento para A (analogo al procedimiento para no terminales de la Fig. 2.17) debe almacenar el apuntador a la entrada en una variable local. Se intenta a continuacion la segunda alternativa de .a para obtener el arbol de la figura 4.9(c). Se empareja la hoja a con el segundo simbolo de w. yy la hoja d. con el tercer simbolo. Como ya se ha producido un arbol de analisis sintactico pars w. se para y se anuncia el exito de la realizacion completa del analisis sintactico. 0 Una gramatica recursive por la izquierda puede hacer que un analizador sintactico por descenso recursivo, incluso uno con retroceso, entre en un Iazo infinito. Es decir. cuando se intenta expandir A, puede que de nuevo se este intentando expandir.A sin haber consumido ningun simbolo de entrada. Analizadores sintacticos predictis'os En muchos casos. escribiendo con cuidado una gramatica, eliminando su recursion por la izquierda y factorizando por la izquierda la gramatica resultante. se puede obtener una gramatica analizable con un analizador sintactico por descenso recursivo que no necesite retroceso. es decir. un analizador sintactico predictivo, como se estudio en la session 2.4. Para construir un analizador sintactico predictivo, se debe conocer. dado el simbolo actual a de entrada y el no terminal A a expandir, cual de las alternativas de produccion.a-oa, a, fi ... a,, es la unica alternativa que da lugar a
una cadena que comience con a. Es decir, la alternativa apropiada debe ser detectable con solo ver el primer simbolo al que da lugar. Asi se detectan generalmente las construcciones de flujo de control de la mayoria de los lenguajes de programa-
cion, con sus palabras slave diferenciadoras. Por ejemplo, si se tienen ]as producciones
prop --> if evpn- then prop else prop
while e V f)r do prop begin /ista_prop.c end
las palabras slave if. while ,% begin indican que alternativa es la unica con posihilidad
de exito para encontrar una proposicion.
188
ANAI.JSIS SIN TACTICO
Diagramas de transiciones para analizadores sinticticos predictivos
En la seccion 2.4 se estudio la implantacion de analizadores sintacticos predictivos
mediante procedimientos recursivos, como los de la figura 2.17. Igual que en la seccion 3.4 se vio que un diagrama de transiciones es un plan o diagrama de flujo titil
para un analizador lexico, se puede crear un diagrama de transiciones como plan
para un analizador sintactico predictivo. En seguida se evidencian varias dif erencias entre los diagramas de transiciones para un analizador lexico y para un analizador sintactico predictivo. En el caso de un analizador sintactico, hay un diagrama para cada no terminal. Las etiquetas de las aristas son componentes lexicos y no terminales. Una transicion con un componente lexico (terminal) supone que se debe tomar dicha transicion si ese componente lexico es el siguiente simbolo de entrada. Una transicion con un no terminal .1 es una Ilamada al procedimiento para A. Para construir el diagrama de transiciones de un analizador sintactico predictivo a partir de una gramatica, primero se debe eliminar la recursion por la izquierda de la gramatica, y despues factorizar dicha gramatica por la izquierda. Luego. pars cada no terminal A Sc hace to siguiente: I. Creese un estado inicial y un estado final We retorno). Para cada produccion.t - .V',X, ... X, creese un camino desde el estado inicial al estado final. con aristas etiquetadas con X,, X, ...............
El analizador sintactico predictivo que se desprende de los diagramas de transiciones se comporta como sigue. Comienza en el estado de inicio del simbolo inicial.
Si despues de algunos movimientos se encuentra en el estado s con una arista etiquetada con el terminal a al estado t. y si el siguiente simbolo de entrada es a,
entonces el analizador sintactico cambia el cursor de la entrada una posicion a la derecha y se va al estado t. Si, por otra parte. la arista esta etiquetada con un no terminal .4. el analizador sintactico va al estado de inicio de .4. sin mover el cursor de la en trada. Si Ilega a alcanzar el estado final de A. inmediatamente va al estado t. habiendo en efecto "leido" A de la entrada cuando se traslado del estado s al t. For ultimo. si hay una arista de s a t etiquetada con e. el analizador sintactico va in mediatamente del estado s al t sin avanzar la entrada. Un programa para hacer analisis sintactico predictivo basado en un diagrama de transiciones intenta emparejar simbolos terminates con la entrada, y realiza una Ilamada potencialmente recursiva a un procedimiento siempre que deba seguir una arista etiquetada con un no terminal. Se puede obtener una implantaci6n no recursiva con una pila para guardar los estados s cuando hay una transicion con un no terminal saliendo de s, y eliminando la pila al alcanzar el estado final de un no terminal. Muv pronto se analizara mas detalladamente la implantacion de diagramas de transicion. El enfoque anterior funciona si el diagrama de transiciones dado no presenta indeterminismo, en el sentido de que haya mas de una transicion desde un estado con la misma entrada. Si existe ambiguedad, se puede solucionar de una forma especifica. como se very en el siguiente ejemplo. Si no se puede eliminar el indeterminismo. no se puede construir un analizador sintactico predictivo, Pero si un anali-
4.4
ANALISIS SINTACTICO DESCENDENTE
189
zador sintactico por descenso recursivo utilizando el retroceso para intentar sistematicamente todas las posibilidades, si esa fuera la mejor estrategia de analisis
posible. Ejemplo 4.15. La figura 4.10 contiene un conjunto de diagramas de transiciones para la gramAtica (4.11). Las unicas ambiguedades se refieren a si se debe o no tomar una arista a. Si se interpreta que las aristas que salen del estado inicial de FL como indicativas de tomar la transicion con + siempre que esta sea la entrada siguiente o
tomar la transicion con F. en otro caso, y realizar el mismo supuesto para T. entonces se elimina la ambiguedad y se puede escribir un programa de analisis sintdctico predictivo para la gramatica (4.11). Se pueden simplificar los diagramas de transiciones sustituyendo unos diagramas por otros: estas sustituciones son similares a las transformaciones en las grad
mdticas de la seccibn 2.5. Por ejemplo, en la figura 4.11(a), la llamada de E' se ha reemplazado a si misma por un salto hasta el principio del diagrama de L.
E':
T
E
E'
To:
Fig. 4.10. Diagramas de transiciones para la grarnatica (4-11).
En la figura 4.11(b) se muestra un diagrama de transiciones equivalente Para E.
Despues se podria sustituir el diagrama de la figura 4.11 para la transicion para ' en el diagrama de l; de la figura 4.10. obteniendose el diagrama de la figura 4.11 (c).
Por Ultimo. se observa que el primero y tercer nodos de la figura 4.11(c) son equivalentes y se fusionan. El resultado, figura 4.11 (d). se repite en el primer diagrama
190
AN. 1.ISIS SIN1ACTIC()
E':
E':
(a)
(b)
(C)
Fig. 4.11. Diagramas de transiciones simplificados .
(d)
de la figura 4.12. Las mismas tecnicas sirven para los diagramas de T y 7. En la figura 4.12 se muestra el conjunto completo de los diagramas obtenidos. Una implantaciOn en C de estc analizador sintactico predictivo funciona un 20 c 25 por
100 mas rapidamente que una implantaciOn en el mismo lenguaje de la figura 4.10.
+-
Fig. 4.12. Diagramas de transiciones simplificados para las expresiones aritmtticas.
Analisis sintactico predictivo no recursivo Se puede construir un analizador sintactico predictivo no recursivo explicitamente
manteniendo una pila. en lugar de hacerlo implicitamente mediante llamadas recursivas. El problema clave durante el andlisis sintactico predictivo es determinar la
Vous aimerez peut-être aussi
- Análisis léxico en sistemas computacionalesDocument4 pagesAnálisis léxico en sistemas computacionalesKristy AlizPas encore d'évaluation
- Introducción a la Teoría de Lenguajes FormalesDocument4 pagesIntroducción a la Teoría de Lenguajes FormalesTaniia Mendez50% (2)
- Lenguajes RegularesDocument32 pagesLenguajes Regularesper3xPas encore d'évaluation
- Haskell lenguaje funcionalDocument7 pagesHaskell lenguaje funcionalMax SanchezPas encore d'évaluation
- Ejemplo ANTLRDocument6 pagesEjemplo ANTLRHumberto José MejiasPas encore d'évaluation
- Diseño de lenguajes de programación: lecciones del pasado y principios para el futuroDocument16 pagesDiseño de lenguajes de programación: lecciones del pasado y principios para el futuroErnes Zuares Ortega0% (1)
- Clasificacion de CompiladoresDocument2 pagesClasificacion de CompiladoresMiguel Chicas0% (1)
- 3.6 Generadores Codigo Lexico Lex y FlexDocument2 pages3.6 Generadores Codigo Lexico Lex y FlexAlbus Jesse CullenPas encore d'évaluation
- Ejercicios Expresiones RegularesDocument3 pagesEjercicios Expresiones Regularesrealvaradog4831Pas encore d'évaluation
- Expresiones regulares: definición, operaciones y aplicacionesDocument11 pagesExpresiones regulares: definición, operaciones y aplicacionescharitoveraaPas encore d'évaluation
- Ensayo Analisis LexicoDocument13 pagesEnsayo Analisis LexicoanthonyPas encore d'évaluation
- Tutorial de XML en EspañolDocument12 pagesTutorial de XML en Españolspleoivt6326Pas encore d'évaluation
- Antologia Automatas IIDocument47 pagesAntologia Automatas IIRamon Cano PrietoPas encore d'évaluation
- Gramatica y AutomatasDocument101 pagesGramatica y AutomatasEdwin Raul Capaquira ChuraPas encore d'évaluation
- Interpretes y Compiladores Cuadro ComparativoDocument6 pagesInterpretes y Compiladores Cuadro ComparativoANGEL ROSARIO MARTINEZPas encore d'évaluation
- Introducción a la Teoría de Lenguajes y AutómatasDocument4 pagesIntroducción a la Teoría de Lenguajes y AutómatasLuis Enrique ArgüellesPas encore d'évaluation
- Tema 2 Estructura SecuencialDocument22 pagesTema 2 Estructura SecuencialArlen FonsecaPas encore d'évaluation
- Equivalencia de Automatas Finitos y Expresiones RegularesDocument24 pagesEquivalencia de Automatas Finitos y Expresiones RegularesJuan Carlos SosaPas encore d'évaluation
- Tecnicas de Programacion Orientada A Objetos - Java Semana 6 Sesion 1-2-3Document15 pagesTecnicas de Programacion Orientada A Objetos - Java Semana 6 Sesion 1-2-3Carlos SanchezPas encore d'évaluation
- Perl: Lenguaje de programación multiparadigma y su historiaDocument15 pagesPerl: Lenguaje de programación multiparadigma y su historiaEdgar Alexander Esteves MillánPas encore d'évaluation
- Lenguajes y Autómatas IDocument91 pagesLenguajes y Autómatas ICeleste Hernández GarayPas encore d'évaluation
- Python Expresiones RegularesDocument7 pagesPython Expresiones RegularesPaulo CastilloPas encore d'évaluation
- Inicio PrologDocument14 pagesInicio PrologOlgaPas encore d'évaluation
- Expresiones regulares: componentes y aplicacionesDocument16 pagesExpresiones regulares: componentes y aplicacionesJULIANPas encore d'évaluation
- Pract 1Document4 pagesPract 1Cristian Bueno GonzálezPas encore d'évaluation
- Lenguajes y Autómatas IDocument26 pagesLenguajes y Autómatas IClaudia TapiaPas encore d'évaluation
- Resumen JavaDocument15 pagesResumen JavaKatita Arias50% (2)
- Instr Didactica Lenguajes y Automatas SCD-1015Document16 pagesInstr Didactica Lenguajes y Automatas SCD-1015Martin Cruz ValenzuelaPas encore d'évaluation
- Exposicion - Expresiones RegularesDocument12 pagesExposicion - Expresiones Regularessimposio2Pas encore d'évaluation
- LYA T5 Resumen Tema 5Document19 pagesLYA T5 Resumen Tema 5Jorge Alberto Jimenez RosalesPas encore d'évaluation
- Automatas y Lenguajes FormalesDocument15 pagesAutomatas y Lenguajes FormalesJesus SanchezPas encore d'évaluation
- 3.1. CSS 2.1Document158 pages3.1. CSS 2.1Daniel GuzmánPas encore d'évaluation
- Características Principales de Los AFNDocument2 pagesCaracterísticas Principales de Los AFNRoman ZapataPas encore d'évaluation
- Examenes de PF Con Haskell Vol11Document46 pagesExamenes de PF Con Haskell Vol11Iván AveigaPas encore d'évaluation
- Lenguajes y Autómatas 1 Unidad 1Document39 pagesLenguajes y Autómatas 1 Unidad 1Elvis De Lal Cruz67% (3)
- Resumen Examen Final EstructuraDocument5 pagesResumen Examen Final EstructuraJoaqui RodriguezPas encore d'évaluation
- Arboles de Análisis GramaticalDocument15 pagesArboles de Análisis GramaticalgilbertoPas encore d'évaluation
- Ensayo Sobre La Teoría de Lenguajes Formales PDFDocument7 pagesEnsayo Sobre La Teoría de Lenguajes Formales PDFRamon Gabriel Burruel ValenzuelaPas encore d'évaluation
- Cocke Younger KasamiDocument64 pagesCocke Younger KasamiElMisterioDeCalendaPas encore d'évaluation
- Modelo OSIDocument9 pagesModelo OSIFausto TapiaPas encore d'évaluation
- Traductor y Su EstructuraDocument7 pagesTraductor y Su EstructuraAndres E. Torrealba T.Pas encore d'évaluation
- TEORIA InvestigacionDocument17 pagesTEORIA Investigacionarte_betaPas encore d'évaluation
- Expresiones Regulares PDFDocument20 pagesExpresiones Regulares PDFbimlakePas encore d'évaluation
- Clases de Gramatica Formal de ChomskyDocument2 pagesClases de Gramatica Formal de ChomskyAnonymous v2tzTJG6100% (1)
- Analizador léxico: funciones y componentes léxicosDocument27 pagesAnalizador léxico: funciones y componentes léxicosMaggie Treto100% (1)
- Proceso de CompilaciónDocument14 pagesProceso de CompilaciónAurelio A. G. BorjasPas encore d'évaluation
- Diagrama de ComponentesDocument2 pagesDiagrama de ComponentesAbraham Rodriguez GutierrezPas encore d'évaluation
- Analizador Lexico Pattern Matcher PDFDocument19 pagesAnalizador Lexico Pattern Matcher PDFjonathan vazquezPas encore d'évaluation
- Test Evaluación (UF3) - MP5. Entornos de Desarrollo (DAM)Document9 pagesTest Evaluación (UF3) - MP5. Entornos de Desarrollo (DAM)javier100% (1)
- Investigación sobre lenguaje de programación CDocument7 pagesInvestigación sobre lenguaje de programación CSydney FernandezPas encore d'évaluation
- Generación de código intermedioDocument13 pagesGeneración de código intermedioEmmanuel Valentin Ramirez Garcia50% (2)
- Proceso de Arquitectura de SoftwareDocument144 pagesProceso de Arquitectura de SoftwareRafael HernandezPas encore d'évaluation
- Rompecabezas en Prolog PDFDocument14 pagesRompecabezas en Prolog PDFAndryGarciaPas encore d'évaluation
- Gestión archivos log MySQLDocument14 pagesGestión archivos log MySQLJose Emmanuel Castro PalmaPas encore d'évaluation
- Unidad IIDocument4 pagesUnidad IIHéctor MárquezPas encore d'évaluation
- Dialnet LaJerarquiaDeChomskyYLaFacultadDelLenguaje 2580734Document14 pagesDialnet LaJerarquiaDeChomskyYLaFacultadDelLenguaje 2580734Diego Arturo PozzoPas encore d'évaluation
- Bibliotecas de CDocument47 pagesBibliotecas de CRicardo Macias JamaicaPas encore d'évaluation
- Analisis Sintactico 2013Document83 pagesAnalisis Sintactico 2013Andrés Quintero AriasPas encore d'évaluation
- Actividad 11 Nvestigacion Manejo Errores SemanticosDocument11 pagesActividad 11 Nvestigacion Manejo Errores Semanticosjessica ramirezPas encore d'évaluation
- Catedra de Compiladores e IntérpretesDocument23 pagesCatedra de Compiladores e IntérpretesKarelin RiveraPas encore d'évaluation
- 26a-Guénon, René - ReseñasDocument103 pages26a-Guénon, René - ReseñasRocinante777Pas encore d'évaluation
- Paqueterías de OfimáticaDocument6 pagesPaqueterías de OfimáticaKarem SilvaPas encore d'évaluation
- Apuntes InglesDocument6 pagesApuntes InglesEdisonPas encore d'évaluation
- Glosario de PragmáticaDocument14 pagesGlosario de PragmáticaXixonuda50% (2)
- Verbos Intermedio - Unidad 4Document6 pagesVerbos Intermedio - Unidad 4Angel PalaciosPas encore d'évaluation
- Usos y Diferencias de Actual y ActuallyDocument4 pagesUsos y Diferencias de Actual y ActuallyJosé Guadalupe JaimesPas encore d'évaluation
- RacionalesDocument13 pagesRacionalesalirio guerreroPas encore d'évaluation
- Manual de Interpretacion de La Carta Natal - Stephen ArroyoDocument146 pagesManual de Interpretacion de La Carta Natal - Stephen ArroyoMia Salgado93% (76)
- Las Relaciones NuméricasDocument27 pagesLas Relaciones NuméricasRamonGalan33% (3)
- Ejércitos Warhammer: Skavens Actualización 1.7Document6 pagesEjércitos Warhammer: Skavens Actualización 1.7tobaldjPas encore d'évaluation
- Lógica proposicionalDocument19 pagesLógica proposicionalalondraPas encore d'évaluation
- Modulo Ingles IV 2020-I 1Document74 pagesModulo Ingles IV 2020-I 1Pedro BjPas encore d'évaluation
- Guia Aprendizaje Estudiante Cuarto Grado Lenguaje f3 s5Document6 pagesGuia Aprendizaje Estudiante Cuarto Grado Lenguaje f3 s5Luis SarPas encore d'évaluation
- Octavo MartesDocument6 pagesOctavo MartesShirley Cortes SusunagaPas encore d'évaluation
- Preposiciones en PortuguesDocument13 pagesPreposiciones en PortuguescymlastarriaPas encore d'évaluation
- El Curso Mas Completo de Ingles (Gramatica)Document205 pagesEl Curso Mas Completo de Ingles (Gramatica)Braulio86100% (2)
- Reconocemos los aportes de la ciencia y tecnologíaDocument20 pagesReconocemos los aportes de la ciencia y tecnologíasara jabo caveroPas encore d'évaluation
- PNL Sexta Parte - Otros 16 ArtículosDocument75 pagesPNL Sexta Parte - Otros 16 ArtículosDaniel Anti-sofistaPas encore d'évaluation
- Perifrasis VerbalDocument2 pagesPerifrasis VerbalKari NadjPas encore d'évaluation
- LEDs con ArduinoDocument3 pagesLEDs con ArduinoDiego PinzonPas encore d'évaluation
- 3.memorias de Corta DuraciónDocument60 pages3.memorias de Corta DuraciónmaitergPas encore d'évaluation
- 4 El Kurripako 67 85Document20 pages4 El Kurripako 67 85calle41Pas encore d'évaluation
- Garrido LorenaDocument318 pagesGarrido LorenaRoger Smith RomeroPas encore d'évaluation
- CupidoComputarizadoDocument5 pagesCupidoComputarizadoCarolina BalderramaPas encore d'évaluation
- Manual de Trabajo de Grado de La UmcDocument43 pagesManual de Trabajo de Grado de La UmcJoffer IrtPas encore d'évaluation
- ADocument51 pagesAJavi Fernanda FigueroaPas encore d'évaluation
- Repaso Prehistoria Correccic3b3nDocument2 pagesRepaso Prehistoria Correccic3b3nAnonymous Tk63QKPas encore d'évaluation
- Pauta Collage El Arte de AmarDocument2 pagesPauta Collage El Arte de AmarMauricio Collao MuñozPas encore d'évaluation
- Plan - Día Plurinacional de La LecturaDocument3 pagesPlan - Día Plurinacional de La LecturaMicaela ibethPas encore d'évaluation
- Definir Informe de RequerimientosDocument12 pagesDefinir Informe de Requerimientosconny9923Pas encore d'évaluation