Vous aimerez peut-être aussi
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- Math7 - Q1 - Mod1 - Introduction To SetsDocument37 pagesMath7 - Q1 - Mod1 - Introduction To SetsJinky Verano Cortez92% (24)
- 2016 12 07 Mcr3u1 Sinusoidal Functions TestDocument8 pages2016 12 07 Mcr3u1 Sinusoidal Functions Testapi-350642180Pas encore d'évaluation
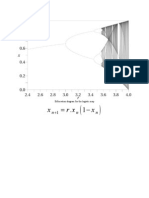
- X RX X: Bifurcation Diagram For The Logistic MapDocument1 pageX RX X: Bifurcation Diagram For The Logistic MapmeysamhemmatiPas encore d'évaluation
- MG As A Path To Smart GridsDocument3 pagesMG As A Path To Smart GridsmeysamhemmatiPas encore d'évaluation
- Behavior of Capstone and Honeywell Microturbine Generators During Load ChangesDocument38 pagesBehavior of Capstone and Honeywell Microturbine Generators During Load Changeskats2404Pas encore d'évaluation
- MG As A Path To Smart GridsDocument3 pagesMG As A Path To Smart GridsmeysamhemmatiPas encore d'évaluation
- Technical Reference: Stand Alone Operation - Capstone Model C30 and C60/C65Document22 pagesTechnical Reference: Stand Alone Operation - Capstone Model C30 and C60/C65meysamhemmatiPas encore d'évaluation
- A Methodology For Evaluating Field Performance and Emissions of A Gas Microturbine Based Cogeneration SystemDocument10 pagesA Methodology For Evaluating Field Performance and Emissions of A Gas Microturbine Based Cogeneration SystemmeysamhemmatiPas encore d'évaluation
- Operation of My Commission Tarh EnteghalDocument1 pageOperation of My Commission Tarh EnteghalmeysamhemmatiPas encore d'évaluation
- 1 Bbfe 85215620Document12 pages1 Bbfe 85215620meysamhemmatiPas encore d'évaluation
- 37Document9 pages37meysamhemmatiPas encore d'évaluation
- 62315Document10 pages62315meysamhemmatiPas encore d'évaluation
- E Letter2Document7 pagesE Letter2meysamhemmatiPas encore d'évaluation
- 1 Lactus RectumDocument11 pages1 Lactus RectumAkpa KenechukwuPas encore d'évaluation
- Intro To TensorsDocument22 pagesIntro To TensorsSumeet KhatriPas encore d'évaluation
- ConditionalDocument5 pagesConditionalkomal sitaPas encore d'évaluation
- Adaline and KDocument29 pagesAdaline and KBHAVNA AGARWAL0% (1)
- Tifr 05Document228 pagesTifr 05Atharva KordePas encore d'évaluation
- Discrete StructureDocument9 pagesDiscrete StructureKaiser VillaceranPas encore d'évaluation
- Is 1.3 A Rational NumberDocument5 pagesIs 1.3 A Rational NumbernishagoyalPas encore d'évaluation
- Differentiation Class 12Document243 pagesDifferentiation Class 12hiteshPas encore d'évaluation
- Notes On Stochastic Processes: 1 Learning OutcomesDocument26 pagesNotes On Stochastic Processes: 1 Learning OutcomesSheikh Mijanur RahamanPas encore d'évaluation
- Pdetool Example: U (0, Y, T) U (1, Y, T) 0 U (X, 0, T) U (X, 1, T) 0Document4 pagesPdetool Example: U (0, Y, T) U (1, Y, T) 0 U (X, 0, T) U (X, 1, T) 0أبو كعب علاء الدينPas encore d'évaluation
- Cannon Strassen DNS AlgorithmDocument10 pagesCannon Strassen DNS AlgorithmKeshav BhutaniPas encore d'évaluation
- Two-Step Equations More Practice 2Document14 pagesTwo-Step Equations More Practice 2Joh TayagPas encore d'évaluation
- Vector Calculus: Divergence TheoremDocument53 pagesVector Calculus: Divergence TheoremSiti HajarPas encore d'évaluation
- Chapter 3. Multi-View DrawingDocument69 pagesChapter 3. Multi-View DrawingAansi FuulleePas encore d'évaluation
- Entity Resolution: TutorialDocument179 pagesEntity Resolution: TutorialSudhakar BhushanPas encore d'évaluation
- Assign Minesweeper GameDocument2 pagesAssign Minesweeper GameIsseusagi AzaliaPas encore d'évaluation
- Chapter 4 DBM 10063Document20 pagesChapter 4 DBM 10063LimitversePas encore d'évaluation
- Diagnostic Test in Math FinalDocument8 pagesDiagnostic Test in Math FinalNerissa LacsonPas encore d'évaluation
- Permutation & Combination SpardhaDocument73 pagesPermutation & Combination SpardhaAkshit VarshneyPas encore d'évaluation
- Mathematical Modeling and ODEDocument44 pagesMathematical Modeling and ODESalma SherbazPas encore d'évaluation
- Itc Imp QuestionsDocument2 pagesItc Imp QuestionsAsaPas encore d'évaluation
- An Introduction To Formal Language Theory That Integrates Experimentation and Proof - Allen StoughtonDocument288 pagesAn Introduction To Formal Language Theory That Integrates Experimentation and Proof - Allen Stoughtonapi-26345612Pas encore d'évaluation
- Class 12th - Relations and FunctionsDocument33 pagesClass 12th - Relations and FunctionsessenzzoPas encore d'évaluation
- 07 RegularizationDocument7 pages07 RegularizationJuan Salvador Sánchez BonnínPas encore d'évaluation
- 11 Half Yearly Exam Dec 2022 MathsDocument3 pages11 Half Yearly Exam Dec 2022 Mathssaraswatin088Pas encore d'évaluation
- Distance and MidpointsDocument6 pagesDistance and MidpointsMohamed YousryPas encore d'évaluation
- Command Description !: Page 1 of 53Document53 pagesCommand Description !: Page 1 of 53Raul Panca PancaPas encore d'évaluation
- 211 Sample ChapterDocument46 pages211 Sample ChapterHuarcaya Nina JhonPas encore d'évaluation