Vous aimerez peut-être aussi
- Healthy Citizens: Applying Math to BMIDocument28 pagesHealthy Citizens: Applying Math to BMIYuki Tan0% (1)
- (Lecture 4) Discrete Probability DistributionsDocument57 pages(Lecture 4) Discrete Probability DistributionsSabaPas encore d'évaluation
- Probility DistributionDocument41 pagesProbility Distributionnitindhiman30Pas encore d'évaluation
- Probability and Distributions II Tutorial 3 2023 SolutionsDocument4 pagesProbability and Distributions II Tutorial 3 2023 SolutionsJinitha BabePas encore d'évaluation
- Normal Distribution 2012Document29 pagesNormal Distribution 2012Gabriel LloydPas encore d'évaluation
- Binomial Normal DistributionDocument47 pagesBinomial Normal DistributionGopal GuptaPas encore d'évaluation
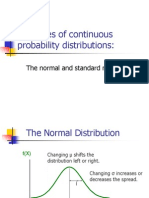
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 pagesExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuPas encore d'évaluation
- f (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,Document4 pagesf (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,missy74Pas encore d'évaluation
- Hypothesis Testing With Z TestsDocument43 pagesHypothesis Testing With Z TestsSudhagarSubbiyanPas encore d'évaluation
- NormalDistribution2012 PDFDocument29 pagesNormalDistribution2012 PDFElisa Dela Reyna BaladadPas encore d'évaluation
- The Binomial, Poisson, and Normal DistributionsDocument39 pagesThe Binomial, Poisson, and Normal DistributionsGianna FaithPas encore d'évaluation
- Probability & Probability Distribution 2Document28 pagesProbability & Probability Distribution 2Amanuel MaruPas encore d'évaluation
- Probability DistributionDocument52 pagesProbability DistributionParul JainPas encore d'évaluation
- 2s03 Session 3 CLT & Normal Dist (Handout)Document51 pages2s03 Session 3 CLT & Normal Dist (Handout)Sabrina RuncoPas encore d'évaluation
- Quantitative AnalysisDocument47 pagesQuantitative AnalysisPhương TrinhPas encore d'évaluation
- Normal DistributionDocument29 pagesNormal Distributionatul_rockstarPas encore d'évaluation
- Statistical Tests Martin G 161131 V15 UPLOADDocument33 pagesStatistical Tests Martin G 161131 V15 UPLOADAnonymous F8kqoYPas encore d'évaluation
- Probability and random variablesDocument7 pagesProbability and random variablesjernejajPas encore d'évaluation
- 6.1: Discrete and Continuous Random VariablesDocument24 pages6.1: Discrete and Continuous Random VariablesJen Mamuyac-CastilloPas encore d'évaluation
- Continuous Probability Distributions and the Normal CurveDocument57 pagesContinuous Probability Distributions and the Normal CurveAkshay VetalPas encore d'évaluation
- Regression AnalysisDocument280 pagesRegression AnalysisA.Benhari100% (1)
- Review 2Document10 pagesReview 2Anastasia Monica KhunniegalshottestPas encore d'évaluation
- 3 DistributionsDocument42 pages3 DistributionsAngga Ade PutraPas encore d'évaluation
- Definition Of Statistics And Key TermsDocument19 pagesDefinition Of Statistics And Key TermsMarie TripoliPas encore d'évaluation
- Probability Distributions.Document47 pagesProbability Distributions.Sarose ThapaPas encore d'évaluation
- Assignment Inferential Statistics 1Document5 pagesAssignment Inferential Statistics 1maudy octhalia d4 kepPas encore d'évaluation
- ADKDocument17 pagesADKSepfira ReztikaPas encore d'évaluation
- QTM Cycle 7 Session 4Document79 pagesQTM Cycle 7 Session 4OttiliePas encore d'évaluation
- Discrete Probability DistributionDocument20 pagesDiscrete Probability Distribution김태태Pas encore d'évaluation
- Notes PDFDocument187 pagesNotes PDFLibyaFlowerPas encore d'évaluation
- Econ SummaryDocument3 pagesEcon SummarycelopurplePas encore d'évaluation
- Understanding Discrete Probability DistributionsDocument4 pagesUnderstanding Discrete Probability DistributionsSheena Mae Noga100% (1)
- 05 Discrete PDDocument44 pages05 Discrete PDAyushi MauryaPas encore d'évaluation
- Business Statistics and Management Science NotesDocument74 pagesBusiness Statistics and Management Science Notes0pointsPas encore d'évaluation
- The Poisson DistributionDocument9 pagesThe Poisson Distributionsyedah1985Pas encore d'évaluation
- Probability and Probability DistributionsDocument8 pagesProbability and Probability DistributionsDr PPas encore d'évaluation
- AP Stats 6.1 LectureDocument28 pagesAP Stats 6.1 LectureLindsay CowdinPas encore d'évaluation
- Central Limit TheoremDocument38 pagesCentral Limit TheoremNiraj Gupta100% (2)
- ECONOMETRICS BASICSDocument61 pagesECONOMETRICS BASICSmaxPas encore d'évaluation
- Lekcija 5 - VjerovatnocaDocument60 pagesLekcija 5 - VjerovatnocaАнђела МијановићPas encore d'évaluation
- Chapter2-New (Compatibility Mode)Document52 pagesChapter2-New (Compatibility Mode)Hafiz SuhaimiPas encore d'évaluation
- ECON 2P91 Assignment #1 AnalysisDocument7 pagesECON 2P91 Assignment #1 AnalysisJoel Christian MascariñaPas encore d'évaluation
- The Normal DistributionDocument9 pagesThe Normal DistributionDog VenturesPas encore d'évaluation
- Review of StatisticsDocument36 pagesReview of StatisticsJessica AngelinaPas encore d'évaluation
- Some Probability Distributions: Marnielle A. Salig LecturerDocument59 pagesSome Probability Distributions: Marnielle A. Salig LecturerPonkan BPas encore d'évaluation
- Stat 255 Supplement 2011 FallDocument78 pagesStat 255 Supplement 2011 Fallgoofbooter100% (1)
- ALLDocument419 pagesALLMangala SemagePas encore d'évaluation
- Chapter 2 - Lesson 4 Random VariablesDocument19 pagesChapter 2 - Lesson 4 Random VariablesChi VirayPas encore d'évaluation
- Statistical Inference FrequentistDocument25 pagesStatistical Inference FrequentistAnkita GhoshPas encore d'évaluation
- Regression Analysis - STAT510Document43 pagesRegression Analysis - STAT510Vivian TranPas encore d'évaluation
- CHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: AssumptionsDocument9 pagesCHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: Assumptionssound05Pas encore d'évaluation
- Multiple Linear RegressionDocument18 pagesMultiple Linear RegressionJohn DoePas encore d'évaluation
- Lecture21 HypothesisTest1Document53 pagesLecture21 HypothesisTest1Sonam AlviPas encore d'évaluation
- Normal Distribution StanfordDocument43 pagesNormal Distribution Stanfordapi-204699162100% (1)
- Categorical Data Analysis IntroductionDocument51 pagesCategorical Data Analysis IntroductionRicardo TavaresPas encore d'évaluation
- 04 Normal Approximation For Data and Binomial DistributionDocument24 pages04 Normal Approximation For Data and Binomial DistributionadmirodebritoPas encore d'évaluation
- Notes St260 Lec6Document16 pagesNotes St260 Lec6mclee7Pas encore d'évaluation
- Station IslandDocument246 pagesStation Islandpiej1209Pas encore d'évaluation
- Cryptography BasicDocument14 pagesCryptography BasicBhargav MendaparaPas encore d'évaluation
- Finite AutomataDocument34 pagesFinite AutomataBhargav MendaparaPas encore d'évaluation
- National Online Examination System An Architectural PerspectiveDocument14 pagesNational Online Examination System An Architectural PerspectiveBhargav MendaparaPas encore d'évaluation
- Fill AlgorithmDocument31 pagesFill Algorithmponga_punditPas encore d'évaluation
- Hello TestDocument1 pageHello TestBhargav MendaparaPas encore d'évaluation
- AZIZ Ur RehmanDocument3 pagesAZIZ Ur Rehmantop writerPas encore d'évaluation
- 1 s2.0 S0149763418301957 MainDocument24 pages1 s2.0 S0149763418301957 MainjackPas encore d'évaluation
- JD - Hygiene Promotion OfficerDocument2 pagesJD - Hygiene Promotion OfficerBeauty ChigwazaPas encore d'évaluation
- Usos HummusDocument36 pagesUsos HummusAlisson FernandaPas encore d'évaluation
- Police Log January 23, 2016Document9 pagesPolice Log January 23, 2016MansfieldMAPolicePas encore d'évaluation
- On Prem Vs CloudDocument10 pagesOn Prem Vs CloudJeev AnandPas encore d'évaluation
- Cognitive and Psychopathological Aspects of Ehlers DanlosDocument5 pagesCognitive and Psychopathological Aspects of Ehlers DanlosKarel GuevaraPas encore d'évaluation
- HW2 4930 Undergraduate SolutionDocument4 pagesHW2 4930 Undergraduate SolutionMatt Mac100% (1)
- Brake System Troubleshooting GuideDocument98 pagesBrake System Troubleshooting Guideruben7mojicaPas encore d'évaluation
- Frenny PDFDocument651 pagesFrenny PDFIftisam AjrekarPas encore d'évaluation
- StarFish BrochureDocument9 pagesStarFish BrochureSaepul HerdianPas encore d'évaluation
- 01 Basic Design Structure FeaturesDocument8 pages01 Basic Design Structure FeaturesAndri AjaPas encore d'évaluation
- Do We Still Need Formocresol in Pediatric DentistryDocument3 pagesDo We Still Need Formocresol in Pediatric DentistryAlexanderDetorakisPas encore d'évaluation
- t-47 Residential Real Property Affidavit - 50108 ts95421Document1 paget-47 Residential Real Property Affidavit - 50108 ts95421api-209878362Pas encore d'évaluation
- Self Level Pu FlooringDocument2 pagesSelf Level Pu FlooringRyan EncomiendaPas encore d'évaluation
- Schematic 1280 - So Do Nokia 1 PDFDocument18 pagesSchematic 1280 - So Do Nokia 1 PDFanh3saigon0% (1)
- Solarizer Value, Spring & UltraDocument4 pagesSolarizer Value, Spring & UltraEmmvee SolarPas encore d'évaluation
- Numerical Modelling of Drying Kinetics of Banana Flower Using Natural and Forced Convection DryersDocument5 pagesNumerical Modelling of Drying Kinetics of Banana Flower Using Natural and Forced Convection DryersMuthu KumarPas encore d'évaluation
- Chapter 4 MoldingDocument46 pagesChapter 4 MoldingTamirat NemomsaPas encore d'évaluation
- Data SheetDocument15 pagesData SheetLucian Sorin BortosuPas encore d'évaluation
- Pastillas DelightDocument12 pagesPastillas DelightBryan DutchaPas encore d'évaluation
- Welder Training in SMAW, GTAW & GMAW Welding Engineering & NDT Consultancy Welding Engineering Related TrainingDocument4 pagesWelder Training in SMAW, GTAW & GMAW Welding Engineering & NDT Consultancy Welding Engineering Related TrainingKavin PrakashPas encore d'évaluation
- RICKETSDocument23 pagesRICKETSDewi SofyanaPas encore d'évaluation
- Job's Method of Continuous VariationDocument11 pagesJob's Method of Continuous Variationalex3bkPas encore d'évaluation
- Res Ipsa LoquiturDocument6 pagesRes Ipsa LoquiturZydalgLadyz NeadPas encore d'évaluation
- Integrated Management of Childhood IllnessDocument8 pagesIntegrated Management of Childhood IllnessSehar162Pas encore d'évaluation
- Making your own Agar PlateDocument8 pagesMaking your own Agar PlateCheska EngadaPas encore d'évaluation
- Best WiFi Adapter For Kali Linux - Monitor Mode & Packet InjectionDocument14 pagesBest WiFi Adapter For Kali Linux - Monitor Mode & Packet InjectionKoushikPas encore d'évaluation
- Multiple Choice RadioactivityDocument4 pagesMultiple Choice RadioactivityGodhrawala AliasgerPas encore d'évaluation
- Duties and Responsibilities of Housekeeping Staff:-1) Executive Housekeeper/Director of HousekeepingDocument8 pagesDuties and Responsibilities of Housekeeping Staff:-1) Executive Housekeeper/Director of HousekeepingsachinPas encore d'évaluation