Vous aimerez peut-être aussi
- Assembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageD'EverandAssembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageÉvaluation : 5 sur 5 étoiles5/5 (1)
- Huffman CodingDocument77 pagesHuffman CodingSyed Umair AnwerPas encore d'évaluation
- Huffman Codes Tree PDFDocument47 pagesHuffman Codes Tree PDFJhomerPas encore d'évaluation
- Huffman CodingDocument44 pagesHuffman CodingTanmay BaranwalPas encore d'évaluation
- L10 Huffman Encoding GreedyDocument52 pagesL10 Huffman Encoding GreedyShivansh RagPas encore d'évaluation
- Huffman Algorithm - Code Construction 2Document18 pagesHuffman Algorithm - Code Construction 2Tommy HizkiaPas encore d'évaluation
- Static Huffman Coding Term PaperDocument23 pagesStatic Huffman Coding Term PaperRavish NirvanPas encore d'évaluation
- Ch3 Block Ciphers and DES - BlackboardDocument37 pagesCh3 Block Ciphers and DES - BlackboardYazanAlomariPas encore d'évaluation
- CCE5102 - 2 - Data Compression MethodsDocument9 pagesCCE5102 - 2 - Data Compression MethodsperhackerPas encore d'évaluation
- Cryptography Programming Workshop, Project 1: Submission InstructionsDocument7 pagesCryptography Programming Workshop, Project 1: Submission Instructionsחיים שפיראPas encore d'évaluation
- Unit 2 - Part 7 Coding Information Sources: 1 Adaptive Variable-Length CodesDocument5 pagesUnit 2 - Part 7 Coding Information Sources: 1 Adaptive Variable-Length CodesfsaPas encore d'évaluation
- Source Coding Theory: TSBK01 Image Coding and Data CompressionDocument14 pagesSource Coding Theory: TSBK01 Image Coding and Data CompressionsrinivaskaredlaPas encore d'évaluation
- Source Coding Theory: TSBK01 Image Coding and Data CompressionDocument14 pagesSource Coding Theory: TSBK01 Image Coding and Data CompressionNada TantawyPas encore d'évaluation
- GVG Editware EDL FormatDocument10 pagesGVG Editware EDL FormatJanusz BaranekPas encore d'évaluation
- DCT Based CodingDocument49 pagesDCT Based CodingLurthu PushparajPas encore d'évaluation
- January 23, 2011: C 2011 Avinash Kak, Purdue UniversityDocument32 pagesJanuary 23, 2011: C 2011 Avinash Kak, Purdue Universitymoon_manPas encore d'évaluation
- Chapter 07 - Lossless Compression AlgorithmsDocument50 pagesChapter 07 - Lossless Compression Algorithmsa_setiajiPas encore d'évaluation
- Lec0 Source Coding & CompressionDocument38 pagesLec0 Source Coding & CompressionYaseen MoPas encore d'évaluation
- Mad Unit 3-JntuworldDocument53 pagesMad Unit 3-JntuworldDilip TheLipPas encore d'évaluation
- Assignment 6: Huffman Encoding: Assignment Overview and Starter FilesDocument20 pagesAssignment 6: Huffman Encoding: Assignment Overview and Starter FilesHarsh TiwariPas encore d'évaluation
- Chapter 1. Introduction To Programming and The Java LanguageDocument49 pagesChapter 1. Introduction To Programming and The Java Languagechloe8hauxwellPas encore d'évaluation
- Compiler - Lexical AnalysisDocument17 pagesCompiler - Lexical Analysistrupti.kodinariya9810Pas encore d'évaluation
- Compression For Sending and Storing Information: Text, Audio, Images, VideosDocument28 pagesCompression For Sending and Storing Information: Text, Audio, Images, VideosPradeep RamuPas encore d'évaluation
- 20 CompressionDocument58 pages20 CompressionSudhakar YadavPas encore d'évaluation
- Modern Block Ciphers: CSE 651: Introduction To Network SecurityDocument52 pagesModern Block Ciphers: CSE 651: Introduction To Network SecurityVinothsaravanan RamakrishnanPas encore d'évaluation
- Chapter 3-Part IIDocument26 pagesChapter 3-Part IIAbebaw Gebre100% (1)
- CH - 03 Huffman & Extended HuffmanDocument10 pagesCH - 03 Huffman & Extended HuffmanHermandeep KaurPas encore d'évaluation
- Notes 07 Compression PDFDocument193 pagesNotes 07 Compression PDFhussein hammoudPas encore d'évaluation
- Unit 2Document28 pagesUnit 2Zohaib Hasan KhanPas encore d'évaluation
- Data Compression: by R.N. AkolDocument31 pagesData Compression: by R.N. AkolEmmanuel OpolotPas encore d'évaluation
- Why Needed?: Without Compression, These Applications Would Not Be FeasibleDocument11 pagesWhy Needed?: Without Compression, These Applications Would Not Be Feasiblesmile00972Pas encore d'évaluation
- Chapter 2 CryptographyDocument79 pagesChapter 2 CryptographyShankar BhattaraiPas encore d'évaluation
- Run Length EncodingDocument7 pagesRun Length EncodingfatimatumbiPas encore d'évaluation
- String CompressionDocument13 pagesString CompressionvatarplPas encore d'évaluation
- Unit 2 CA209Document29 pagesUnit 2 CA209Farah AsifPas encore d'évaluation
- Unit Ii: Block Ciphers & Public Key CryptographyDocument109 pagesUnit Ii: Block Ciphers & Public Key CryptographyDhivyabharathi APas encore d'évaluation
- Assignment No: 02 Title: Huffman AlgorithmDocument7 pagesAssignment No: 02 Title: Huffman AlgorithmtejasPas encore d'évaluation
- Compression IIDocument51 pagesCompression IIJagadeesh NaniPas encore d'évaluation
- Howto UnicodeDocument9 pagesHowto UnicodedomielPas encore d'évaluation
- Final CSI 4107 - 2009 SolutionDocument11 pagesFinal CSI 4107 - 2009 SolutionMerelup100% (1)
- Data Compression: Chapter - 2 Mathematical Preliminaries For Lossless CompressionDocument26 pagesData Compression: Chapter - 2 Mathematical Preliminaries For Lossless CompressionDhrumil Mistry100% (2)
- Entropy: A 00 A 01 A 10 A 11Document22 pagesEntropy: A 00 A 01 A 10 A 11Darshan ShahPas encore d'évaluation
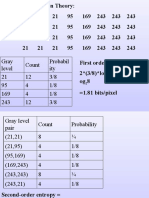
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Document51 pagesGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaPas encore d'évaluation
- Chapter 4 MultiDocument45 pagesChapter 4 Multiadu gPas encore d'évaluation
- Huffman Coding TechniqueDocument13 pagesHuffman Coding TechniqueAnchal RathorePas encore d'évaluation
- Aes and DesDocument11 pagesAes and Des20PCT19 THANISHKA SPas encore d'évaluation
- Chapter ThreeDocument30 pagesChapter ThreemekuriaPas encore d'évaluation
- Chapter 2 - EditedDocument45 pagesChapter 2 - EditedmulusewPas encore d'évaluation
- Information Theory and Coding - Chapter 3Document33 pagesInformation Theory and Coding - Chapter 3Dr. Aref Hassan KurdaliPas encore d'évaluation
- Compiler Design: Ambo University School of Informatics and Electrical Engineering Department of Computer ScienceDocument35 pagesCompiler Design: Ambo University School of Informatics and Electrical Engineering Department of Computer ScienceBEKAN FAYERAPas encore d'évaluation
- Lecture 3: Block Ciphers and The Data Encryption Standard Lecture Notes On "Computer and Network Security"Document51 pagesLecture 3: Block Ciphers and The Data Encryption Standard Lecture Notes On "Computer and Network Security"Majid BasharatPas encore d'évaluation
- Dlangspec PDFDocument516 pagesDlangspec PDFrahim1409Pas encore d'évaluation
- Problems Chaptr 1 PDFDocument4 pagesProblems Chaptr 1 PDFcaught inPas encore d'évaluation
- What Is Huffman Coding and Its HistoryDocument5 pagesWhat Is Huffman Coding and Its HistoryNam PhươngPas encore d'évaluation
- FALLSEM2020-21 CSE4022 ETH VL2020210104471 Reference Material I 25-Jul-2020 NLP2-Lecture 1 3Document35 pagesFALLSEM2020-21 CSE4022 ETH VL2020210104471 Reference Material I 25-Jul-2020 NLP2-Lecture 1 3SushanPas encore d'évaluation
- Assignment of SuccessfulDocument5 pagesAssignment of SuccessfulLe Tien Dat (K18 HL)Pas encore d'évaluation
- Chapter 2 Lexical AnalysisDocument26 pagesChapter 2 Lexical AnalysisElias HirpasaPas encore d'évaluation
- Unit 2 IssDocument40 pagesUnit 2 Issharshit TPas encore d'évaluation
- LexicalDocument34 pagesLexicalADITYA SINGHPas encore d'évaluation
- Assignment 03 InstructionsDocument1 pageAssignment 03 InstructionsdivyangkapadiaPas encore d'évaluation
- Btech Mtech Complete Mid march2015ECED PDFDocument4 pagesBtech Mtech Complete Mid march2015ECED PDFdivyangkapadiaPas encore d'évaluation
- Transient Response AnaDocument14 pagesTransient Response AnadivyangkapadiaPas encore d'évaluation
- Block Diagram ReductionDocument21 pagesBlock Diagram ReductionAzeem AliPas encore d'évaluation
- Iot CiscoDocument11 pagesIot Ciscoapi-253592912Pas encore d'évaluation
- English Teachers ClubDocument116 pagesEnglish Teachers Clubjilanlucky222Pas encore d'évaluation
- Block Diagram ReductionDocument21 pagesBlock Diagram ReductionAzeem AliPas encore d'évaluation
- ArtDocument1 pageArtdivyangkapadiaPas encore d'évaluation
- Iit Jee 2010 Paper 1Document33 pagesIit Jee 2010 Paper 1Umang MishraPas encore d'évaluation
- Revised Btech - Mtech - Complete - Mid - Sem201419092014 PDFDocument4 pagesRevised Btech - Mtech - Complete - Mid - Sem201419092014 PDFdivyangkapadiaPas encore d'évaluation
- Hit PDFDocument6 pagesHit PDFdivyangkapadiaPas encore d'évaluation
- 01 IntroDocument17 pages01 IntroabdifatahPas encore d'évaluation
- L3 - Network Algorithms: NGEN06 (TEK230) - Algorithms in Geographical Information SystemsDocument16 pagesL3 - Network Algorithms: NGEN06 (TEK230) - Algorithms in Geographical Information SystemsdivyangkapadiaPas encore d'évaluation
- List of VLSI CompaniesDocument2 pagesList of VLSI CompaniesdivyangkapadiaPas encore d'évaluation
- Gujarat Technological University Ahmedabad: ResultDocument1 pageGujarat Technological University Ahmedabad: ResultdivyangkapadiaPas encore d'évaluation
- Presentation On T&P Activities (2013-14batch)Document15 pagesPresentation On T&P Activities (2013-14batch)divyangkapadiaPas encore d'évaluation
- Basic Concepts: 1. What Is A Database?Document8 pagesBasic Concepts: 1. What Is A Database?divyangkapadiaPas encore d'évaluation
- Ofss IiDocument3 pagesOfss IidivyangkapadiaPas encore d'évaluation
- VDocument1 pageVdivyangkapadiaPas encore d'évaluation
- Second Floor PlanDocument1 pageSecond Floor PlandivyangkapadiaPas encore d'évaluation
- Academic Calendar 2012Document1 pageAcademic Calendar 2012Rimpal ParikhPas encore d'évaluation
- 76 1 Scholarship-Booklet2Document30 pages76 1 Scholarship-Booklet2divyangkapadiaPas encore d'évaluation
- Assi 1 BJT Diff Amp.Document3 pagesAssi 1 BJT Diff Amp.divyangkapadiaPas encore d'évaluation
- Solution of Aic Assignment 1 (Mrunal Sir)Document1 pageSolution of Aic Assignment 1 (Mrunal Sir)shubhamgarg2222Pas encore d'évaluation
- First Floor PlanDocument1 pageFirst Floor PlandivyangkapadiaPas encore d'évaluation
- Assi 2 MOSFET Diiff Amp.Document2 pagesAssi 2 MOSFET Diiff Amp.divyangkapadiaPas encore d'évaluation
- Assi 1 BJT Diff Amp.Document3 pagesAssi 1 BJT Diff Amp.divyangkapadiaPas encore d'évaluation
- Assi 2 MOSFET Diiff Amp.Document2 pagesAssi 2 MOSFET Diiff Amp.divyangkapadiaPas encore d'évaluation
- It 603 Information Theory and CodingDocument2 pagesIt 603 Information Theory and Codingrnagu1969Pas encore d'évaluation
- New Decoding Methods For LDPC Codes On Error and Error-Erasure ChannelsDocument92 pagesNew Decoding Methods For LDPC Codes On Error and Error-Erasure ChannelsIlke AltinPas encore d'évaluation
- CAPE Computer Science Internal Assessment ProjectDocument4 pagesCAPE Computer Science Internal Assessment ProjectHerbert Morrion50% (2)
- Syllabus 2021Document106 pagesSyllabus 2021SparksPas encore d'évaluation
- ABC Universal Code 1881Document486 pagesABC Universal Code 1881Max PowerPas encore d'évaluation
- Assignment Solutions GUIDE (2019-2020)Document12 pagesAssignment Solutions GUIDE (2019-2020)Rajni KumariPas encore d'évaluation
- Chapter 6Document53 pagesChapter 6Sam KhanPas encore d'évaluation
- Chapter 1 BC-MGT 269Document30 pagesChapter 1 BC-MGT 269Anonymous lGWT2FK7ko0% (1)
- The Capacity of The Noisy Quantum ChannelDocument19 pagesThe Capacity of The Noisy Quantum ChannelElisabeth OrtegaPas encore d'évaluation
- Imperial Combination Code 1913Document286 pagesImperial Combination Code 1913Max PowerPas encore d'évaluation
- Multimedia Concept & Topics: Prof. R. M. FaroukDocument22 pagesMultimedia Concept & Topics: Prof. R. M. FaroukKhaled HeshamPas encore d'évaluation
- ABM-A - Caole, Aron Joel - Oral CommunicationDocument2 pagesABM-A - Caole, Aron Joel - Oral CommunicationAron Joel CaolePas encore d'évaluation
- Senior 12 Entrepreneurship Q3 M7 For PrintingDocument27 pagesSenior 12 Entrepreneurship Q3 M7 For PrintingJulie Ann D. GaboPas encore d'évaluation
- 3F7 - FTR - Improving Arithmetic CodesDocument12 pages3F7 - FTR - Improving Arithmetic CodesperhackerPas encore d'évaluation
- Delta Encoding in Data CompressionDocument18 pagesDelta Encoding in Data CompressionNisha MenonPas encore d'évaluation
- IT6003-Multi Media Compression TechniquesDocument10 pagesIT6003-Multi Media Compression TechniquesPK JawaharPas encore d'évaluation
- Unit I:: Functions, Nature and Process of CommunicationDocument15 pagesUnit I:: Functions, Nature and Process of CommunicationRhydon DeroquePas encore d'évaluation
- Python GTK 3 TutorialDocument131 pagesPython GTK 3 TutorialEliaspirantePas encore d'évaluation
- MIT6 02F12 Chap02Document12 pagesMIT6 02F12 Chap02gautruc408Pas encore d'évaluation
- Written Communication - QuizDocument2 pagesWritten Communication - QuizmatharajeshPas encore d'évaluation
- EE 376A: Information Theory: Lecture NotesDocument75 pagesEE 376A: Information Theory: Lecture Notesgautham gadiyaramPas encore d'évaluation
- DC Lab RecordDocument16 pagesDC Lab RecordSowmya ChowdaryPas encore d'évaluation
- Module 3A-Principles of CommunicationDocument7 pagesModule 3A-Principles of Communicationmayank.23bce10033Pas encore d'évaluation
- EC401 M1-Information Theory & Coding-Ktustudents - in PDFDocument50 pagesEC401 M1-Information Theory & Coding-Ktustudents - in PDFPradeep Kumar SainiPas encore d'évaluation
- UV17H User ManualDocument52 pagesUV17H User ManualElsonBPas encore d'évaluation
- Miller 1951 LanguageDocument323 pagesMiller 1951 LanguageFarida MaftukhaPas encore d'évaluation
- FMOB Term PaperDocument20 pagesFMOB Term PaperBhavya NawalakhaPas encore d'évaluation
- 5-LZW CodingDocument2 pages5-LZW Codingvits knrPas encore d'évaluation
- Digital Transmission and Line Coding Techs.Document32 pagesDigital Transmission and Line Coding Techs.mgoyal_28Pas encore d'évaluation
- GPCom Lesson 1 CommunicationDocument6 pagesGPCom Lesson 1 CommunicationNoelle Faye MendozaPas encore d'évaluation