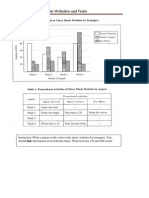
Vous aimerez peut-être aussi
- Concepts and Techniques: - Chapter 10Document97 pagesConcepts and Techniques: - Chapter 10sebpkyPas encore d'évaluation
- 10clustering - Han and KamberDocument93 pages10clustering - Han and KambersukruthPas encore d'évaluation
- Clustering For Big Data AnalyticsDocument28 pagesClustering For Big Data AnalyticshakonaPas encore d'évaluation
- Data Mining ClusteringDocument76 pagesData Mining ClusteringAnjali Asha JacobPas encore d'évaluation
- Cluster Analysis Methods for Data InsightsDocument53 pagesCluster Analysis Methods for Data InsightsMaha LakshmiPas encore d'évaluation
- Concepts and Techniques: Data MiningDocument101 pagesConcepts and Techniques: Data MiningJiyual MustiPas encore d'évaluation
- Concepts and Techniques: Data MiningDocument43 pagesConcepts and Techniques: Data MiningEsraa SamirPas encore d'évaluation
- Concepts and Techniques: Data MiningDocument27 pagesConcepts and Techniques: Data MiningAdamZain788Pas encore d'évaluation
- Concepts and Techniques: Data MiningDocument101 pagesConcepts and Techniques: Data MiningRizky RamadhanPas encore d'évaluation
- Concepts and Techniques: Data MiningDocument50 pagesConcepts and Techniques: Data MiningHasibur Rahman PoragPas encore d'évaluation
- DM BS Lec8 ClusteringDocument48 pagesDM BS Lec8 ClusteringrubaPas encore d'évaluation
- DM Lecture 06Document32 pagesDM Lecture 06Sameer AhmadPas encore d'évaluation
- Data Mining Clustering AlgorithmsDocument83 pagesData Mining Clustering AlgorithmsTeofilus EvanPas encore d'évaluation
- Clustering in AIDocument16 pagesClustering in AIRam KushwahaPas encore d'évaluation
- 06 Cluster AnalysisDocument34 pages06 Cluster Analysishawariya abelPas encore d'évaluation
- 5 Algoritma KlasteringDocument85 pages5 Algoritma Klasteringicobes urPas encore d'évaluation
- Unit 5_Cluster analysisDocument14 pagesUnit 5_Cluster analysiseskpg066Pas encore d'évaluation
- Cluster Analysis ClusteringDocument6 pagesCluster Analysis Clustering17CSE97- VIKASHINI TPPas encore d'évaluation
- Data MiningDocument98 pagesData MiningJijeesh BaburajanPas encore d'évaluation
- Custer Analysis: Prepared by Navin NinamaDocument20 pagesCuster Analysis: Prepared by Navin NinamaNishith LakhlaniPas encore d'évaluation
- Data Mining-Partitioning MethodsDocument7 pagesData Mining-Partitioning MethodsRaj Endran100% (1)
- Partitioning MethodsDocument3 pagesPartitioning MethodsDiyar T Alzuhairi100% (1)
- Unit 5 - Cluster AnalysisDocument14 pagesUnit 5 - Cluster AnalysisAnand Kumar BhagatPas encore d'évaluation
- ClusteringDocument104 pagesClusteringDev kartik AgarwalPas encore d'évaluation
- Data Mining Unit-IvDocument34 pagesData Mining Unit-Ivlokeshappalaneni9Pas encore d'évaluation
- GroupingDocument98 pagesGroupingAditya PatelPas encore d'évaluation
- Cluster Analysis: Dr. Bernard Chen Ph.D. Assistant ProfessorDocument43 pagesCluster Analysis: Dr. Bernard Chen Ph.D. Assistant Professorrajeshkumar_nicePas encore d'évaluation
- Data Mining: I Gede Mahendra DarmawigunaDocument25 pagesData Mining: I Gede Mahendra DarmawigunaBitboxkPas encore d'évaluation
- Unit IV Cluster AnalysisDocument7 pagesUnit IV Cluster AnalysisAjit RautPas encore d'évaluation
- What Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDocument42 pagesWhat Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDineshkannan RaviPas encore d'évaluation
- Data Mining-Model Based ClusteringDocument8 pagesData Mining-Model Based ClusteringRaj EndranPas encore d'évaluation
- Machine Learning and Data Science LaboratoryDocument2 pagesMachine Learning and Data Science LaboratoryVaishnavi GuravPas encore d'évaluation
- Datawarehousing and Data MiningDocument119 pagesDatawarehousing and Data MininglakshmiraghujashuPas encore d'évaluation
- Unsupervised LearningDocument83 pagesUnsupervised LearningTanush MohindraPas encore d'évaluation
- 4 ClusteringDocument9 pages4 ClusteringBibek NeupanePas encore d'évaluation
- DMDW Qa-5Document7 pagesDMDW Qa-5hashitapusapati012Pas encore d'évaluation
- Data Mining: ClusteringDocument46 pagesData Mining: ClusteringshwetadhatterwalPas encore d'évaluation
- Ambo University: Inistitute of TechnologyDocument15 pagesAmbo University: Inistitute of TechnologyabayPas encore d'évaluation
- ClusteringDocument80 pagesClusteringAatmaj SalunkePas encore d'évaluation
- ClusteringDocument22 pagesClusteringUtkarsh SrivastavPas encore d'évaluation
- Attack Detection by Clustering and Classification Approach: Ms. Priyanka J. Pathak, Asst. Prof. Snehlata S. DongreDocument4 pagesAttack Detection by Clustering and Classification Approach: Ms. Priyanka J. Pathak, Asst. Prof. Snehlata S. DongreIjarcsee JournalPas encore d'évaluation
- A Novel Approach For Data Clustering Using Improved K-Means Algorithm PDFDocument6 pagesA Novel Approach For Data Clustering Using Improved K-Means Algorithm PDFNinad SamelPas encore d'évaluation
- JETIR1809788Document4 pagesJETIR1809788Agusti Frananda Alfonsus NaibahoPas encore d'évaluation
- A Parallel Study On Clustering Algorithms in Data MiningDocument7 pagesA Parallel Study On Clustering Algorithms in Data MiningAnu IshwaryaPas encore d'évaluation
- Analysis&Comparisonof Efficient TechniquesofDocument5 pagesAnalysis&Comparisonof Efficient TechniquesofasthaPas encore d'évaluation
- Cluster Analysis Methods for Data MiningDocument19 pagesCluster Analysis Methods for Data MiningManikandan MPas encore d'évaluation
- Unit 4Document4 pagesUnit 4adityapawar1865Pas encore d'évaluation
- Clustering K Means AgnesDocument36 pagesClustering K Means AgnespreetamPas encore d'évaluation
- K Nearest Neighbor Algorithm: Fundamentals and ApplicationsD'EverandK Nearest Neighbor Algorithm: Fundamentals and ApplicationsPas encore d'évaluation
- ClusteringDocument26 pagesClusteringExpoMed ExpoMedPas encore d'évaluation
- JNU Project Design with K-Means ClusteringDocument26 pagesJNU Project Design with K-Means ClusteringFaizan Shaikh100% (1)
- 10 Marks QuestionsDocument19 pages10 Marks QuestionsAnupriya VeerasamyPas encore d'évaluation
- A Comparative Study of K-Means, K-Medoid and Enhanced K-Medoid AlgorithmsDocument4 pagesA Comparative Study of K-Means, K-Medoid and Enhanced K-Medoid AlgorithmsIJAFRCPas encore d'évaluation
- Pam Clustering Technique ExplainedDocument11 pagesPam Clustering Technique ExplainedsamakshPas encore d'évaluation
- Gautam A. KudaleDocument6 pagesGautam A. KudaleHellbuster45Pas encore d'évaluation
- An Efficient Enhanced K-Means Clustering AlgorithmDocument8 pagesAn Efficient Enhanced K-Means Clustering Algorithmahmed_fahim98Pas encore d'évaluation
- Recursive Hierarchical Clustering AlgorithmDocument7 pagesRecursive Hierarchical Clustering Algorithmreader29Pas encore d'évaluation
- K Means ClusteringDocument6 pagesK Means ClusteringAlina Corina BalaPas encore d'évaluation
- Big DataDocument7 pagesBig DataSevendipity SciencePas encore d'évaluation
- MUET Argumentative Essay Topics and Points OutlineDocument12 pagesMUET Argumentative Essay Topics and Points OutlineJessie Richard95% (20)
- Jadual Waktu 2 Pismp B&K (DC 4) : Ahad Isnin Selasa Rabu KhamisDocument1 pageJadual Waktu 2 Pismp B&K (DC 4) : Ahad Isnin Selasa Rabu KhamisLS LimPas encore d'évaluation
- Sample EssayDocument16 pagesSample EssayMike KuPas encore d'évaluation
- Argumentative Essay Topics IncludeDocument2 pagesArgumentative Essay Topics IncludeMike KuPas encore d'évaluation
- Brainstorming: Getting Ideas Before You WriteDocument8 pagesBrainstorming: Getting Ideas Before You WriteMike KuPas encore d'évaluation
- BMT - Bukan Rutin MuruganDocument15 pagesBMT - Bukan Rutin MuruganMike KuPas encore d'évaluation
- Elc SportDocument1 pageElc SportMike KuPas encore d'évaluation
- DatingAbuse101Presentation 11Document16 pagesDatingAbuse101Presentation 11Mike KuPas encore d'évaluation
- Mesa Teen Dating Violence65466Document32 pagesMesa Teen Dating Violence65466Mike KuPas encore d'évaluation
- BMT Non-Routine ChongDocument13 pagesBMT Non-Routine ChongMike KuPas encore d'évaluation
- Ela-Sem Holiday ProjectDocument1 pageEla-Sem Holiday ProjectMike KuPas encore d'évaluation
- Pass Year Questions (MT) - Part 2Document3 pagesPass Year Questions (MT) - Part 2Mike KuPas encore d'évaluation
- Directory: Contents PagesDocument3 pagesDirectory: Contents PagesMike KuPas encore d'évaluation
- Topic Sentence. MI-SDDocument13 pagesTopic Sentence. MI-SDSushan TanPas encore d'évaluation
- Contoh TeselasiDocument15 pagesContoh TeselasiElaine YingPas encore d'évaluation
- Contoh PosterDocument2 pagesContoh PosterMike KuPas encore d'évaluation
- Yes No Questions-1Document13 pagesYes No Questions-1Mike KuPas encore d'évaluation
- Practice 22 - He Never Came Back - CheckedDocument2 pagesPractice 22 - He Never Came Back - CheckedMike KuPas encore d'évaluation
- Yes No Questions-1Document13 pagesYes No Questions-1Mike KuPas encore d'évaluation
- 2010 Mid Year Teenagers Websites Answer Key 1Document2 pages2010 Mid Year Teenagers Websites Answer Key 1Mike KuPas encore d'évaluation
- CV MATTA 4D Bali FBDocument1 pageCV MATTA 4D Bali FBMike KuPas encore d'évaluation
- Natural Disasters-Research ProjectDocument26 pagesNatural Disasters-Research ProjectMike KuPas encore d'évaluation
- Matrix Multiplication: Hyun Lee, Eun Kim, Jedd HakimiDocument47 pagesMatrix Multiplication: Hyun Lee, Eun Kim, Jedd HakimiMike KuPas encore d'évaluation
- Complaints LetterDocument3 pagesComplaints LetterMike Ku100% (1)
- 2010 Mid Year Teenagers Websites Answer Key 1Document2 pages2010 Mid Year Teenagers Websites Answer Key 1Mike KuPas encore d'évaluation
- Tess of the Durbervilles Book Report SummaryDocument6 pagesTess of the Durbervilles Book Report SummaryMike KuPas encore d'évaluation
- Analyzing Poetic Devices in Sylvia Chidi's "A Bad or a Good TeacherDocument3 pagesAnalyzing Poetic Devices in Sylvia Chidi's "A Bad or a Good TeacherMike KuPas encore d'évaluation
- List of AS... AS Similes: Simile Meaning CommentDocument3 pagesList of AS... AS Similes: Simile Meaning CommentMike KuPas encore d'évaluation
- Candidate A: Instructions To Candidates: Task A: Individual PresentationDocument8 pagesCandidate A: Instructions To Candidates: Task A: Individual Presentationwan333Pas encore d'évaluation
- Penomoran Bantex - K64&COMPDocument8 pagesPenomoran Bantex - K64&COMPVigour Rizko MurdynePas encore d'évaluation
- Saes H 201Document9 pagesSaes H 201heartbreakkid132Pas encore d'évaluation
- Influence of Oxygen in Copper - 2010Document1 pageInfluence of Oxygen in Copper - 2010brunoPas encore d'évaluation
- Plenaristas León 2022xDocument6 pagesPlenaristas León 2022xGloria MontielPas encore d'évaluation
- Brochure Troysperse+CD1+Brochure+ (TB0112)Document8 pagesBrochure Troysperse+CD1+Brochure+ (TB0112)mario3312Pas encore d'évaluation
- VLSI Physical Design: From Graph Partitioning To Timing ClosureDocument30 pagesVLSI Physical Design: From Graph Partitioning To Timing Closurenagabhairu anushaPas encore d'évaluation
- CROCI Focus Intellectual CapitalDocument35 pagesCROCI Focus Intellectual CapitalcarminatPas encore d'évaluation
- Mock PPT 2023 TietDocument22 pagesMock PPT 2023 Tiettsai42zigPas encore d'évaluation
- Analysis of Piled Raft of Shanghai Tower in Shanghai by The Program ELPLADocument18 pagesAnalysis of Piled Raft of Shanghai Tower in Shanghai by The Program ELPLAAmey DeshmukhPas encore d'évaluation
- Electromagnetic Braking SystemDocument14 pagesElectromagnetic Braking SystemTanvi50% (2)
- Abiding LonelinessDocument9 pagesAbiding Lonelinessgrupodelectura04Pas encore d'évaluation
- CTM Catalogue 2015-2016Document100 pagesCTM Catalogue 2015-2016Anonymous dXcoknUPas encore d'évaluation
- Shop SupervisionDocument38 pagesShop SupervisionSakura Yuno Gozai80% (5)
- DrdoDocument2 pagesDrdoAvneet SinghPas encore d'évaluation
- Crafting and Executing StrategyDocument33 pagesCrafting and Executing Strategyamoore2505Pas encore d'évaluation
- Lecture 6Document16 pagesLecture 6Dina Saad EskanderePas encore d'évaluation
- Chemistry 101 - The Complete Notes - Joliet Junior College (PDFDrive)Document226 pagesChemistry 101 - The Complete Notes - Joliet Junior College (PDFDrive)Kabwela MwapePas encore d'évaluation
- HWXX 6516DS1 VTM PDFDocument1 pageHWXX 6516DS1 VTM PDFDmitriiSpiridonovPas encore d'évaluation
- Lab Report 1Document8 pagesLab Report 1Hammad SattiPas encore d'évaluation
- Small Healthcare Organization: National Accreditation Board For Hospitals & Healthcare Providers (Nabh)Document20 pagesSmall Healthcare Organization: National Accreditation Board For Hospitals & Healthcare Providers (Nabh)Dipti PatilPas encore d'évaluation
- Technology and Livelihood Education: Agri - Fishery Arts (Agricultural Crops Production) Marketing Agricultural ProductsDocument14 pagesTechnology and Livelihood Education: Agri - Fishery Arts (Agricultural Crops Production) Marketing Agricultural Productslana del rey100% (1)
- U-PJT WASHER-MD SimpleUX WEB SSEC-01 EU EnglishDocument76 pagesU-PJT WASHER-MD SimpleUX WEB SSEC-01 EU EnglishszerenguettiPas encore d'évaluation
- Documentation For UStarDocument26 pagesDocumentation For UStarthunder77Pas encore d'évaluation
- Brake System PDFDocument9 pagesBrake System PDFdiego diaz100% (1)
- QUIZ 2 BUMA 20013 - Operations Management TQMDocument5 pagesQUIZ 2 BUMA 20013 - Operations Management TQMSlap SharePas encore d'évaluation
- Science-6 - Q4 - W8-DLL - Mar 10Document2 pagesScience-6 - Q4 - W8-DLL - Mar 10cristina quiambaoPas encore d'évaluation
- Scan & Pay Jio BillDocument22 pagesScan & Pay Jio BillsumeetPas encore d'évaluation
- Astm A105, A105mDocument5 pagesAstm A105, A105mMike Dukas0% (1)
- Teodorico M. Collano, JR.: ENRM 223 StudentDocument5 pagesTeodorico M. Collano, JR.: ENRM 223 StudentJepoyCollanoPas encore d'évaluation
- Column and Thin Layer ChromatographyDocument5 pagesColumn and Thin Layer Chromatographymarilujane80% (5)