Vous aimerez peut-être aussi
- Variables: By: Karen Cahigas Kenneth Vincent OcanaDocument11 pagesVariables: By: Karen Cahigas Kenneth Vincent Ocanakevin12lasalPas encore d'évaluation
- Research Methods Causality Experiments DesignsDocument17 pagesResearch Methods Causality Experiments DesignsAnushree GhoshPas encore d'évaluation
- Experimental ResearchDocument22 pagesExperimental ResearchCuteepie Sucheta MondalPas encore d'évaluation
- Experimental Design: Tarun KushwahaDocument32 pagesExperimental Design: Tarun Kushwahadeepakarora201188Pas encore d'évaluation
- 9 ExperimentalDesignsDocument48 pages9 ExperimentalDesignsRizaPas encore d'évaluation
- Dersnot 2400 1616143252Document25 pagesDersnot 2400 1616143252aliPas encore d'évaluation
- Research Methods ObservationDocument24 pagesResearch Methods Observationnoorulhadi99Pas encore d'évaluation
- How Teachers Spend Time in the ClassroomDocument13 pagesHow Teachers Spend Time in the ClassroomShazia HamidPas encore d'évaluation
- BRM chp04Document16 pagesBRM chp04Rajashekhar B BeedimaniPas encore d'évaluation
- EXPERIMENTAL RESEARCH PROCEDUREDocument21 pagesEXPERIMENTAL RESEARCH PROCEDUREKureshiPas encore d'évaluation
- Experimental DesignsDocument73 pagesExperimental DesignsAman HussainPas encore d'évaluation
- Lecture 5. Experimental Research DesignsDocument23 pagesLecture 5. Experimental Research DesignsZeeshan AkhtarPas encore d'évaluation
- 497 ExperimentsDocument42 pages497 ExperimentsJesse SandersPas encore d'évaluation
- First Semester - MidtermsDocument28 pagesFirst Semester - MidtermsAshtey RamosPas encore d'évaluation
- Causal Studies: Types of Explanatory ResearchDocument18 pagesCausal Studies: Types of Explanatory ResearchhrishikeshPas encore d'évaluation
- The Scientific Method-1Document2 pagesThe Scientific Method-1hagaratiia520Pas encore d'évaluation
- GCSE Psychology Research Methods - Key VariablesDocument21 pagesGCSE Psychology Research Methods - Key VariablesHelena ZhangPas encore d'évaluation
- Causal ResearchDocument23 pagesCausal ResearchVardaan BhaikPas encore d'évaluation
- The 7 Steps of Well-Planned ExperimentsDocument29 pagesThe 7 Steps of Well-Planned ExperimentsVJ DecanoPas encore d'évaluation
- Overview of Different Types of ValuesDocument25 pagesOverview of Different Types of ValuesMaaz KhanPas encore d'évaluation
- Lecture 1 PSY101L, Theoretical Concepts of ExperimentDocument12 pagesLecture 1 PSY101L, Theoretical Concepts of ExperimentGOLAM SARWAR KABIR 1711694630Pas encore d'évaluation
- PSY 101L Psychological Experiment GuideDocument12 pagesPSY 101L Psychological Experiment GuideAsrafia Mim 1813026630Pas encore d'évaluation
- Experimental Design Lec 1Document27 pagesExperimental Design Lec 1Sara HussienPas encore d'évaluation
- A Classification of Experimental DesignsDocument15 pagesA Classification of Experimental Designssony21100% (1)
- Research 6Document10 pagesResearch 6Khalid JulkanainPas encore d'évaluation
- Lec 9Document22 pagesLec 9Nada ElDeebPas encore d'évaluation
- ThesisDocument29 pagesThesisJoharPas encore d'évaluation
- Experimental Research: A. Pre-Experimental DesignsDocument3 pagesExperimental Research: A. Pre-Experimental Designssherla TorioPas encore d'évaluation
- 8604 Unit 4 Revised Experimental Research 1Document22 pages8604 Unit 4 Revised Experimental Research 1amirkhan30bjrPas encore d'évaluation
- Summary ExperimentsDocument3 pagesSummary ExperimentsHeba MahmoudPas encore d'évaluation
- Principles of Experimental Design: Nur Syaliza Hanim Che Yusof Sta340Document10 pagesPrinciples of Experimental Design: Nur Syaliza Hanim Che Yusof Sta340Nur ShuhadaPas encore d'évaluation
- Experimental Study DesignDocument49 pagesExperimental Study DesignAyeshaPas encore d'évaluation
- Construct Validation of The Student Academic Burnout Scale: Adonis P. DavidDocument22 pagesConstruct Validation of The Student Academic Burnout Scale: Adonis P. Davidpemea2008Pas encore d'évaluation
- Assignment 1 (B) - Causal Research DesignDocument3 pagesAssignment 1 (B) - Causal Research DesignMd AsgharPas encore d'évaluation
- Experimental Design and ValidityDocument2 pagesExperimental Design and Validitygai3my4483Pas encore d'évaluation
- Experimental Design GuideDocument28 pagesExperimental Design GuideK.Kiran KumarPas encore d'évaluation
- Kathy Mae F. Daclan (Experimental Design Final)Document7 pagesKathy Mae F. Daclan (Experimental Design Final)YHTAK1792Pas encore d'évaluation
- Visual Inspection 02-08-2019Document63 pagesVisual Inspection 02-08-2019Amit Mishra100% (2)
- Document 62Document2 pagesDocument 62Aaron James QuijanoPas encore d'évaluation
- DT PDFDocument20 pagesDT PDFmanoPas encore d'évaluation
- Experimental ResearchDocument74 pagesExperimental Researchitishaagrawal41Pas encore d'évaluation
- Experimental DesignDocument155 pagesExperimental DesignAsyifa ApsariPas encore d'évaluation
- Reviewer ExppsychDocument3 pagesReviewer ExppsychYoru BuffPas encore d'évaluation
- Research-Quantitative Research DesignDocument47 pagesResearch-Quantitative Research DesignNi OrPas encore d'évaluation
- Experimental Research DesignDocument29 pagesExperimental Research DesignSiddharth BhargavaPas encore d'évaluation
- 6 Experimental Design Lectrue - 24.9.2022 PDFDocument46 pages6 Experimental Design Lectrue - 24.9.2022 PDFSahethi100% (1)
- Experimental Research Design TypesDocument19 pagesExperimental Research Design Typesanshu2k6Pas encore d'évaluation
- Experimental ResearchDocument17 pagesExperimental ResearchAl Patrick ChavitPas encore d'évaluation
- Research Chapter 1Document13 pagesResearch Chapter 1PASCUA, Louisse I.Pas encore d'évaluation
- Mixed Dentition Occlusion and AnalysisDocument45 pagesMixed Dentition Occlusion and AnalysisM Atif SiddiquiPas encore d'évaluation
- Group 1Document51 pagesGroup 1AbdulAhadPas encore d'évaluation
- Experimental PsychologyDocument3 pagesExperimental PsychologykylamadelcPas encore d'évaluation
- Experimental Research DesignDocument39 pagesExperimental Research DesignMunawar BilalPas encore d'évaluation
- Analytics 2Document15 pagesAnalytics 2Ankit BhattPas encore d'évaluation
- Chapter 08 - Experimental DesignsDocument24 pagesChapter 08 - Experimental DesignsNelsenSAPas encore d'évaluation
- Experimental MethodDocument3 pagesExperimental MethodRinimPas encore d'évaluation
- 497 ExperimentsDocument42 pages497 ExperimentsCyn SyjucoPas encore d'évaluation
- Bloc 3 Causal Designs: 1. Concomitant VariationDocument18 pagesBloc 3 Causal Designs: 1. Concomitant VariationNúria Ventura CallPas encore d'évaluation
- Experimentation ChapterDocument4 pagesExperimentation Chapteraashika shresthaPas encore d'évaluation
- BlackberryDocument6 pagesBlackberryneer4scridPas encore d'évaluation
- MF-Equity Presentation Q2 2011Document17 pagesMF-Equity Presentation Q2 2011rahulPas encore d'évaluation
- MRP - Final ReportDocument127 pagesMRP - Final ReportrahulPas encore d'évaluation
- Structured Query LanguageDocument45 pagesStructured Query LanguagerahulPas encore d'évaluation
- Structured DevelopmentDocument43 pagesStructured DevelopmentrahulPas encore d'évaluation
- Access Database Objects: IBS, Chennai II IT Workshop On MS Access October 3-6, 2008 #Document36 pagesAccess Database Objects: IBS, Chennai II IT Workshop On MS Access October 3-6, 2008 #rahulPas encore d'évaluation
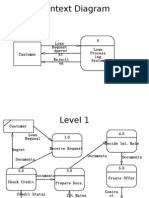
- Context Diagram: Loan Request Approv Al Rejecti On 0Document4 pagesContext Diagram: Loan Request Approv Al Rejecti On 0rahulPas encore d'évaluation
- Database Design: - Tables - Constraints - Relationships - QueriesDocument9 pagesDatabase Design: - Tables - Constraints - Relationships - QueriesrahulPas encore d'évaluation
- Database Management System - ClassroomDocument39 pagesDatabase Management System - ClassroomrahulPas encore d'évaluation
- Icfai: Information Systems DevelopmentDocument20 pagesIcfai: Information Systems DevelopmentrahulPas encore d'évaluation
- Icfai: Enterprise-Wide Information SystemsDocument45 pagesIcfai: Enterprise-Wide Information SystemsrahulPas encore d'évaluation
- The Dream Every Company Wants To BeDocument16 pagesThe Dream Every Company Wants To BerahulPas encore d'évaluation
- Book AcquisitionDocument12 pagesBook AcquisitionrahulPas encore d'évaluation
- NormalisationDocument18 pagesNormalisationrahul0% (1)
- 6 SigmaDocument27 pages6 SigmarahulPas encore d'évaluation
- Research DesignDocument35 pagesResearch DesignrahulPas encore d'évaluation
- Process QuizDocument32 pagesProcess QuizrahulPas encore d'évaluation
- Dbms 6 Er ModelingDocument91 pagesDbms 6 Er ModelingrahulPas encore d'évaluation
- Class Factor AnalysisDocument21 pagesClass Factor AnalysisrahulPas encore d'évaluation
- Peter DruckerDocument63 pagesPeter DruckerrahulPas encore d'évaluation
- Supply Chain ManagementDocument19 pagesSupply Chain ManagementrahulPas encore d'évaluation
- DFD Common MistakeDocument14 pagesDFD Common Mistakerahul100% (2)
- Multivariate Analysis: Are Some of The Variables Dependent On Others?Document16 pagesMultivariate Analysis: Are Some of The Variables Dependent On Others?rahul100% (1)
- Multivariate AnalysisDocument34 pagesMultivariate AnalysisrahulPas encore d'évaluation
- Ant AnalysisDocument18 pagesAnt AnalysisrahulPas encore d'évaluation
- Measurenent ScalesDocument52 pagesMeasurenent ScalesrahulPas encore d'évaluation
- Ant AnalysisDocument18 pagesAnt AnalysisrahulPas encore d'évaluation
- Why Study Research 1Document41 pagesWhy Study Research 1rahulPas encore d'évaluation
- Attitude Measurementfinal1Document45 pagesAttitude Measurementfinal1rahulPas encore d'évaluation
- Why Study Resarch 2Document35 pagesWhy Study Resarch 2rahulPas encore d'évaluation
- General Education - 150 ItemsDocument9 pagesGeneral Education - 150 ItemsJeah CañoneraPas encore d'évaluation
- Outline Biology IADocument3 pagesOutline Biology IAraghad67% (3)
- Design of Experiments - ToolDocument17 pagesDesign of Experiments - ToolmuneerppPas encore d'évaluation
- Designing Experiments An OverviewDocument6 pagesDesigning Experiments An OverviewNagarajan.NPas encore d'évaluation
- IRM Experimental Research NewDocument4 pagesIRM Experimental Research Newarum26elshaf100% (1)
- Whole Plant Transpiration LabDocument4 pagesWhole Plant Transpiration LabYakini LeePas encore d'évaluation
- Statistics at KU LeuvenDocument8 pagesStatistics at KU LeuventrysutrisnaPas encore d'évaluation
- III Q3 EXAM Answer KeyDocument2 pagesIII Q3 EXAM Answer KeyMa. Angelica BautistaPas encore d'évaluation
- Meaning and Scope of Marketing ResearchDocument19 pagesMeaning and Scope of Marketing ResearchNardsdel RiveraPas encore d'évaluation
- Research Design DecisionsDocument36 pagesResearch Design DecisionsLeannePas encore d'évaluation
- Simulated ExamDocument17 pagesSimulated ExamDr-Mohammed FaridPas encore d'évaluation
- M.E. MSMDocument34 pagesM.E. MSMVignesh KivickyPas encore d'évaluation
- Test Bank For Essentials of Biology 6th Edition Sylvia Mader Michael WindelspechtDocument39 pagesTest Bank For Essentials of Biology 6th Edition Sylvia Mader Michael Windelspechtazurawinifredupaa8mPas encore d'évaluation
- 6chapter-6 (Nested and Split Plot Design) - 1Document46 pages6chapter-6 (Nested and Split Plot Design) - 1gebremaryamzeleke081Pas encore d'évaluation
- Eight Keys to Successful Designed ExperimentsDocument10 pagesEight Keys to Successful Designed ExperimentsMiguel ChPas encore d'évaluation
- Chapter 5 Causation and Experimental DesignDocument30 pagesChapter 5 Causation and Experimental Designshanks263Pas encore d'évaluation
- Experimental Design, Response Surface Analysis, and OptimizationDocument24 pagesExperimental Design, Response Surface Analysis, and OptimizationMukul RaghavPas encore d'évaluation
- Investigatory Project by Erika Sheane Estera and Jomel MaromaDocument21 pagesInvestigatory Project by Erika Sheane Estera and Jomel MaromaI-Ruby707997% (59)
- A Practical Guide To Conjoint AnalysisDocument8 pagesA Practical Guide To Conjoint AnalysisPablo Andres Bozinovic ManriquezPas encore d'évaluation
- Puzzles: Sudoku, Kakuro, Akari and More..Document2 pagesPuzzles: Sudoku, Kakuro, Akari and More..api-3843571Pas encore d'évaluation
- 1-Factorial Experiments PDFDocument14 pages1-Factorial Experiments PDFVikki NandeshwarPas encore d'évaluation
- Optimization of Lignin Extraction from Moroccan Sugarcane BagasseDocument7 pagesOptimization of Lignin Extraction from Moroccan Sugarcane BagasseAli IrtazaPas encore d'évaluation
- 1) Qinthara 2) Fanisa 3) RoidatunDocument12 pages1) Qinthara 2) Fanisa 3) RoidatunDesi PuspitasariPas encore d'évaluation
- Experimental Research DesignsDocument36 pagesExperimental Research DesignsYosephine Susie Saraswati100% (2)
- Cohort Studies: Design, Analysis, and ReportingDocument7 pagesCohort Studies: Design, Analysis, and Reportingari aulia rahman hakimPas encore d'évaluation
- Module 4 Designs A Research Used in Daily LifeDocument15 pagesModule 4 Designs A Research Used in Daily Lifenicss bonaobraPas encore d'évaluation
- Experimental DesignsDocument12 pagesExperimental DesignsAllana Ruth P. AbudaPas encore d'évaluation
- Printable Sudoku High Five, July 5Document1 pagePrintable Sudoku High Five, July 5News-PressPas encore d'évaluation
- Optimization of Concrete Mix with Glass Fiber and TiO2 NanoparticlesDocument31 pagesOptimization of Concrete Mix with Glass Fiber and TiO2 Nanoparticlesmanny ansariPas encore d'évaluation
- Ed 504903Document14 pagesEd 504903devon2610Pas encore d'évaluation