Vous aimerez peut-être aussi
- Complete Business Statistics: by Amir D. Aczel & Jayavel Sounderpandian 6 EditionDocument74 pagesComplete Business Statistics: by Amir D. Aczel & Jayavel Sounderpandian 6 EditionRao P SatyanarayanaPas encore d'évaluation
- Complete Business Statistics: Introduction and Descriptive Statistics Introduction and Descriptive StatisticsDocument79 pagesComplete Business Statistics: Introduction and Descriptive Statistics Introduction and Descriptive StatisticsNassir CeellaabePas encore d'évaluation
- GCSE Mathematics Numerical Crosswords Foundation Written for the GCSE 9-1 CourseD'EverandGCSE Mathematics Numerical Crosswords Foundation Written for the GCSE 9-1 CoursePas encore d'évaluation
- Presentation 3Document37 pagesPresentation 3Swaroop Ranjan Baghar100% (1)
- GCSE Maths Revision: Cheeky Revision ShortcutsD'EverandGCSE Maths Revision: Cheeky Revision ShortcutsÉvaluation : 3.5 sur 5 étoiles3.5/5 (2)
- Statstical MethodDocument60 pagesStatstical MethodYosefPas encore d'évaluation
- Quantitative Methods For Decision Making: Dr. AkhterDocument100 pagesQuantitative Methods For Decision Making: Dr. AkhterZaheer AslamPas encore d'évaluation
- Lecture-2 Descriptive Statistics-Box Plot Descriptive MeasuresDocument47 pagesLecture-2 Descriptive Statistics-Box Plot Descriptive MeasuresOmar SibghatPas encore d'évaluation
- Complete Business Statistics: Introduction and Descriptive Statistics Introduction and Descriptive StatisticsDocument79 pagesComplete Business Statistics: Introduction and Descriptive Statistics Introduction and Descriptive StatisticsLan PhanPas encore d'évaluation
- STI - 03 - Data Presentation & ParameterDocument47 pagesSTI - 03 - Data Presentation & ParameterMuhamad Abi HaykalPas encore d'évaluation
- Numerical Descriptive Measures 1Document39 pagesNumerical Descriptive Measures 1Dolores AbanganPas encore d'évaluation
- Lecture 1: Introduction: Statistics Is Concerned WithDocument45 pagesLecture 1: Introduction: Statistics Is Concerned WithWei CongPas encore d'évaluation
- Decision ScienceDocument523 pagesDecision ScienceVidhu Vasav GillPas encore d'évaluation
- Statistics For Managers Using Microsoft Excel: 4 EditionDocument54 pagesStatistics For Managers Using Microsoft Excel: 4 EditionIrving Adrian SantosoPas encore d'évaluation
- ECON1203/ECON2292 Business and Economic Statistics: Week 2Document10 pagesECON1203/ECON2292 Business and Economic Statistics: Week 2Jason PanPas encore d'évaluation
- Chap 001Document50 pagesChap 001Evan AdrielPas encore d'évaluation
- Basic 1Document60 pagesBasic 1Rajesh DwivediPas encore d'évaluation
- Ken Black QA ch03Document61 pagesKen Black QA ch03Rushabh Vora0% (1)
- Describing, Exploring, and Comparing DataDocument61 pagesDescribing, Exploring, and Comparing DataLizette Leah Ching100% (1)
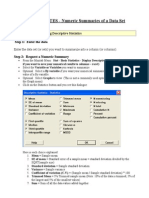
- Minitab HELP NOTES - Numeric Summaries of A Data Set: Step 1: Enter The DataDocument4 pagesMinitab HELP NOTES - Numeric Summaries of A Data Set: Step 1: Enter The DataBilly AnugrahPas encore d'évaluation
- Robust Measures NotesDocument8 pagesRobust Measures Notesfahad tajimPas encore d'évaluation
- Statistics - Describing Data NumericalDocument56 pagesStatistics - Describing Data NumericalDr Rushen SinghPas encore d'évaluation
- Quartiles DJDocument13 pagesQuartiles DJHenry TeepohPas encore d'évaluation
- Measusres of LocationsDocument52 pagesMeasusres of LocationsSubashDahalPas encore d'évaluation
- BMS1024 Topic2Document53 pagesBMS1024 Topic2Minxuan LimPas encore d'évaluation
- RegressionDocument49 pagesRegressionSahauddin ShaPas encore d'évaluation
- Measures of Central TendencyDocument65 pagesMeasures of Central Tendencyspandan_mohantyPas encore d'évaluation
- Chap 001Document34 pagesChap 001sarasPas encore d'évaluation
- Discriptive StatisticsDocument50 pagesDiscriptive StatisticsSwathi JanardhanPas encore d'évaluation
- STAT110 Spring 2017 2018part3Document33 pagesSTAT110 Spring 2017 2018part3Ahmmad W. MahmoodPas encore d'évaluation
- Descriptive Statistics: Numerical Descriptive Statistics: Numerical Methods Methods Methods MethodsDocument52 pagesDescriptive Statistics: Numerical Descriptive Statistics: Numerical Methods Methods Methods Methodsarshiya_21Pas encore d'évaluation
- Statistics 1 - NotesDocument22 pagesStatistics 1 - Notesryanb97Pas encore d'évaluation
- Lecture-1 IntroductionDocument47 pagesLecture-1 IntroductionMoiz AntariaPas encore d'évaluation
- IntroductionDocument37 pagesIntroductionzinmarPas encore d'évaluation
- Quartile Details ModifiedDocument4 pagesQuartile Details ModifiedChandrabali SahaPas encore d'évaluation
- Descriptive Stat 3Document62 pagesDescriptive Stat 3Yen De Guzman PeñarandaPas encore d'évaluation
- Standard ScoresDocument46 pagesStandard ScoresRochelle D. Tuddao-Lim100% (1)
- 1 - Descriptive Statistics Data: Frequency DistributionDocument57 pages1 - Descriptive Statistics Data: Frequency DistributionspecialityPas encore d'évaluation
- Mt271 Statistics For Non-Majors (3 Units) : Lecture 2: Graphic Presentation of DataDocument15 pagesMt271 Statistics For Non-Majors (3 Units) : Lecture 2: Graphic Presentation of DataLotead JohnPas encore d'évaluation
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarPas encore d'évaluation
- Quartile & DeviationDocument31 pagesQuartile & DeviationM Pavan KumarPas encore d'évaluation
- Topic 4 - Measures of Spread PDFDocument14 pagesTopic 4 - Measures of Spread PDFDrew ChambersPas encore d'évaluation
- Chapter 3 QMT 554-Jul10Document59 pagesChapter 3 QMT 554-Jul10Umi Afiqah Amalin AzhishamPas encore d'évaluation
- Statistic Sample Question IiswbmDocument15 pagesStatistic Sample Question IiswbmMudasarSPas encore d'évaluation
- Bus173 Chap03Document42 pagesBus173 Chap03KaziRafiPas encore d'évaluation
- Chapter 2Document61 pagesChapter 2hemant023Pas encore d'évaluation
- Probability and Stochastic Process-5Document19 pagesProbability and Stochastic Process-5Neha NadeemPas encore d'évaluation
- By: David NegrelliDocument27 pagesBy: David NegrelliBliss ManPas encore d'évaluation
- Business Statistics: Methods For Describing Sets of DataDocument103 pagesBusiness Statistics: Methods For Describing Sets of DataDrake AdamPas encore d'évaluation
- Standard and Quartile DeviationDocument7 pagesStandard and Quartile DeviationGemine Ailna Panganiban NuevoPas encore d'évaluation
- S1181 U03 NotesDocument5 pagesS1181 U03 NotesLoganHarperPas encore d'évaluation
- Principle of Biostatistic Marcello Pagano Principle & Method Richard A Jhonson & Gouri K. BhattacharyyaDocument45 pagesPrinciple of Biostatistic Marcello Pagano Principle & Method Richard A Jhonson & Gouri K. BhattacharyyaArdena Maulidia HamdaniPas encore d'évaluation
- Chapter 4 Demand EstimationDocument8 pagesChapter 4 Demand Estimationmyra0% (1)
- Introductory of Statistics - Chapter 3Document7 pagesIntroductory of Statistics - Chapter 3Riezel PepitoPas encore d'évaluation
- Numerical Descriptive MeasuresDocument63 pagesNumerical Descriptive MeasuresSantosh SrikarPas encore d'évaluation
- Basic StatisticsDocument73 pagesBasic Statisticsartee_aggrawal4312100% (2)
- Managerial and Statistical Questions: Virtually All of The Statistics Cited Here Are Gleaned From Studies or SurveysDocument9 pagesManagerial and Statistical Questions: Virtually All of The Statistics Cited Here Are Gleaned From Studies or SurveysSalil AmbekarPas encore d'évaluation
- Lecture 1 PDFDocument55 pagesLecture 1 PDFHà Anh Minh LêPas encore d'évaluation
- Current Affairs Guidelines-2017-18Document2 pagesCurrent Affairs Guidelines-2017-18Rohit KishorePas encore d'évaluation
- Christ University Course Pack For MAIS CourseDocument71 pagesChrist University Course Pack For MAIS CourseRohit KishorePas encore d'évaluation
- Foreign Policy of India V N Khanna PDFDocument192 pagesForeign Policy of India V N Khanna PDFRohit Kishore100% (1)
- Australia Provides 19 New Patrol Boats To Pacific Island Region To Help Combat Transnational CrimesDocument2 pagesAustralia Provides 19 New Patrol Boats To Pacific Island Region To Help Combat Transnational CrimesRohit KishorePas encore d'évaluation
- WorldcommDocument6 pagesWorldcommRohit KishorePas encore d'évaluation
- WorldcommDocument6 pagesWorldcommRohit KishorePas encore d'évaluation
- Transforming CountriesDocument6 pagesTransforming CountriesRohit KishorePas encore d'évaluation
- DISEC Terrorism Study GuideDocument29 pagesDISEC Terrorism Study GuideRohit KishorePas encore d'évaluation
- Resolution 9.9: The General Assembly First CommitteeDocument2 pagesResolution 9.9: The General Assembly First CommitteeRohit KishorePas encore d'évaluation
- Notewa Sessoinwa 1-2Document7 pagesNotewa Sessoinwa 1-2Rohit KishorePas encore d'évaluation
- Collated BetaDocument17 pagesCollated BetaRohit KishorePas encore d'évaluation
- Top 50 Global Market Research Co.Document2 pagesTop 50 Global Market Research Co.Rohit KishorePas encore d'évaluation
- IMC Case Analysis Gillette Dry Idea (A)Document14 pagesIMC Case Analysis Gillette Dry Idea (A)mahtaabkPas encore d'évaluation
- Something SomethingDocument2 pagesSomething SomethingRohit KishorePas encore d'évaluation
- ReturnofthePride CaseStudyDocument8 pagesReturnofthePride CaseStudyRohit KishorePas encore d'évaluation
- BRM - Session 1 and 2Document5 pagesBRM - Session 1 and 2Rohit KishorePas encore d'évaluation
- Usage of Smartphone: Literature ReviewDocument6 pagesUsage of Smartphone: Literature ReviewRohit KishorePas encore d'évaluation
- SharmaJi's LifeDocument3 pagesSharmaJi's LifeRohit KishorePas encore d'évaluation
- IIIE Paper ModifiedDocument7 pagesIIIE Paper ModifiedRohit KishorePas encore d'évaluation
- Privacy-Enhancing Technologies For The Internet: Ian Goldberg David Wagner Eric BrewerDocument7 pagesPrivacy-Enhancing Technologies For The Internet: Ian Goldberg David Wagner Eric BrewerRohit KishorePas encore d'évaluation
- HW 2Document1 pageHW 2Rohit KishorePas encore d'évaluation
- Background of The StudyDocument14 pagesBackground of The StudyJessieJameEOculamPas encore d'évaluation
- PhenolDocument7 pagesPhenolMartin FuenzalidaPas encore d'évaluation
- IELTS VocabularyDocument28 pagesIELTS VocabularyHanaPas encore d'évaluation
- Agricultural Statistics at Glance2014Document482 pagesAgricultural Statistics at Glance2014hayer13Pas encore d'évaluation
- Serambi Engineering PaperDocument18 pagesSerambi Engineering PaperUcok DedyPas encore d'évaluation
- Calculation of Discharge Coefficient in Complex Opening (Laminar Flow)Document7 pagesCalculation of Discharge Coefficient in Complex Opening (Laminar Flow)AbdulPas encore d'évaluation
- Tests For The Ratio of Two Poisson RatesDocument15 pagesTests For The Ratio of Two Poisson RatesscjofyWFawlroa2r06YFVabfbajPas encore d'évaluation
- Exercises in Engineering StatisticsDocument34 pagesExercises in Engineering StatisticsCristina CojoceaPas encore d'évaluation
- UNIT II Probability SolutionsDocument21 pagesUNIT II Probability SolutionsJohnnyPas encore d'évaluation
- Session 1 Forecasting: Advanced Management AccountingDocument40 pagesSession 1 Forecasting: Advanced Management AccountingmrhuggalumpsPas encore d'évaluation
- Algebra I PracticeDocument83 pagesAlgebra I PracticezorthogPas encore d'évaluation
- FDP On Applied Econometrics PresentationDocument17 pagesFDP On Applied Econometrics PresentationDrDeepti JiPas encore d'évaluation
- An Introduction To ROC AnalysisDocument14 pagesAn Introduction To ROC AnalysisTrần Anh Tú100% (1)
- Articulo TopografiaDocument13 pagesArticulo TopografiaDenilson Max Lozano ColquehuancaPas encore d'évaluation
- SYLLABUS - Old - University of Kalyani B.A. Hons. Geography PDFDocument17 pagesSYLLABUS - Old - University of Kalyani B.A. Hons. Geography PDFJISHNU SARPas encore d'évaluation
- ME GATE 2017 Set I Key SolutionDocument25 pagesME GATE 2017 Set I Key SolutionBeesam Ramesh KumarPas encore d'évaluation
- Conducting Investigatory ProjectDocument26 pagesConducting Investigatory ProjectHannah Gaile FrandoPas encore d'évaluation
- Investor Sentiment Aligned: A Powerful Predictor of Stock ReturnsDocument50 pagesInvestor Sentiment Aligned: A Powerful Predictor of Stock ReturnsTu Anh PhamPas encore d'évaluation
- A New Approach For Application of Rock Mass ClassificationDocument15 pagesA New Approach For Application of Rock Mass ClassificationBrian ConnerPas encore d'évaluation
- Multiple Choice Quiz ForecastingDocument3 pagesMultiple Choice Quiz Forecastingعمر ثابتPas encore d'évaluation
- Introduction To Kernel SmoothingDocument24 pagesIntroduction To Kernel SmoothingwillrentPas encore d'évaluation
- Astm E73Document5 pagesAstm E73Lupita RamirezPas encore d'évaluation
- Classification: Naïve Bayes' Classifier: Lecture #8Document51 pagesClassification: Naïve Bayes' Classifier: Lecture #8Praneeth KadiyamPas encore d'évaluation
- D 6767 - 02Document6 pagesD 6767 - 02luis-12Pas encore d'évaluation
- Peyton-Manning Dataset Fbprophet Daily Australia Temperature Dataset Beijing PM2.5 DatasetDocument2 pagesPeyton-Manning Dataset Fbprophet Daily Australia Temperature Dataset Beijing PM2.5 Datasetsiper34606Pas encore d'évaluation
- Time Series - Eviews GuidelinesDocument36 pagesTime Series - Eviews GuidelinesTanuj AroraPas encore d'évaluation
- Nozzle 2017Document3 pagesNozzle 2017Naph Mushi0% (1)
- Tugas Kelompok 6 PDFDocument10 pagesTugas Kelompok 6 PDFsongjihyo16111994Pas encore d'évaluation
- Introduction To Measurement Uncertainty and Propagation of ErrorDocument2 pagesIntroduction To Measurement Uncertainty and Propagation of ErrorGregbr62Pas encore d'évaluation
- June 2014 (IAL) QP - S2 EdexcelDocument12 pagesJune 2014 (IAL) QP - S2 EdexcelSyed FahimPas encore d'évaluation