Vous aimerez peut-être aussi
- Sample Size For Surveys: Dr. Muna Hassan MustafaDocument32 pagesSample Size For Surveys: Dr. Muna Hassan MustafaMuna Hassan MustafaPas encore d'évaluation
- Sampling and Sampling DistributionDocument22 pagesSampling and Sampling DistributionMr Bhanushali100% (1)
- Week 12Document22 pagesWeek 12lilywhite786Pas encore d'évaluation
- Lecture 9 Sampling Techniques LectureDocument30 pagesLecture 9 Sampling Techniques Lectureephraimsmart11Pas encore d'évaluation
- Research Methods: Sampling & PopulationDocument48 pagesResearch Methods: Sampling & PopulationAli Imran LodhiPas encore d'évaluation
- Sample and Sampling TerminologyDocument49 pagesSample and Sampling Terminologyalone_01100% (1)
- Sampling & Sampling Distribution: by Asif HanifDocument25 pagesSampling & Sampling Distribution: by Asif Hanifsadia245Pas encore d'évaluation
- 6) BIOSTATISTICsDocument99 pages6) BIOSTATISTICsMadhulikaPas encore d'évaluation
- Sampling Designing and Data SourcesDocument19 pagesSampling Designing and Data SourcesJanaki Ramani LankapothuPas encore d'évaluation
- Sampling Process: Prof. (DR.) C.K.DashDocument43 pagesSampling Process: Prof. (DR.) C.K.DashSumit Kumar SharmaPas encore d'évaluation
- Business Data Analytics Students-07-Sampling PDFDocument50 pagesBusiness Data Analytics Students-07-Sampling PDFSiddharth KumarPas encore d'évaluation
- Research Methodology: DR Min Shan HtunDocument35 pagesResearch Methodology: DR Min Shan HtunPyae Khant PaingPas encore d'évaluation
- SamplingDocument28 pagesSamplingAshish SethiPas encore d'évaluation
- Sampling Designs in Operational Health Research: Dr. Syed Irfan AliDocument35 pagesSampling Designs in Operational Health Research: Dr. Syed Irfan AliDrAmit VermaPas encore d'évaluation
- SamplingDocument23 pagesSampling119936232141Pas encore d'évaluation
- Sampling Nursing ResearchDocument16 pagesSampling Nursing ResearchLawrence Rayappen100% (2)
- Research MethodologyDocument36 pagesResearch MethodologyJeca CodmPas encore d'évaluation
- Research Methods For Business & Management: Summer Semester - 2020/2021 Module Fourteen SamplingDocument27 pagesResearch Methods For Business & Management: Summer Semester - 2020/2021 Module Fourteen SamplingOmar HadePas encore d'évaluation
- Sample and PopulationDocument35 pagesSample and PopulationTantry SyamPas encore d'évaluation
- Introduction to BiostatisticsDocument60 pagesIntroduction to BiostatisticsKARTHIK SREEKUMARPas encore d'évaluation
- 02 ABE Review - Sampling TechniquesDocument41 pages02 ABE Review - Sampling TechniquesRio Banan IIPas encore d'évaluation
- 6) BIOSTATISTICsDocument99 pages6) BIOSTATISTICsMadhulikaPas encore d'évaluation
- Introduction To Sampling: Situo Liu Spry, Inc. 10/25/2013Document22 pagesIntroduction To Sampling: Situo Liu Spry, Inc. 10/25/2013ጀኔራል አሳምነው ፅጌPas encore d'évaluation
- PSYC 334 Session 9 SlidesDocument56 pagesPSYC 334 Session 9 SlidesFELIX ADDOPas encore d'évaluation
- Sampling TechniquesDocument15 pagesSampling TechniquesVikash BagriPas encore d'évaluation
- 2006 - Philosophy, Methodology and Action ResearchDocument43 pages2006 - Philosophy, Methodology and Action ResearchnurleennaPas encore d'évaluation
- Research Design, Sampling and Data Collection ToolsDocument40 pagesResearch Design, Sampling and Data Collection ToolsMoud KhalfaniPas encore d'évaluation
- Identifying the Different Random Sampling Techniques AutosavedDocument18 pagesIdentifying the Different Random Sampling Techniques AutosavedTatsuya KirigayaPas encore d'évaluation
- Target Population: Rely On Probability and Non ProbabilityDocument15 pagesTarget Population: Rely On Probability and Non ProbabilityNoufal Asif0% (1)
- Research Sampling TechniquesDocument28 pagesResearch Sampling TechniquesSerah JavaidPas encore d'évaluation
- Sample and Sampling TechniqueDocument39 pagesSample and Sampling TechniqueJayshree VasavaPas encore d'évaluation
- Sampling and Sampling DistributionDocument64 pagesSampling and Sampling DistributionNIKHIL PATTNAIKPas encore d'évaluation
- Unit IX Sampling: Sher Alam KhanDocument32 pagesUnit IX Sampling: Sher Alam KhanMUHAMMAD AHMEDPas encore d'évaluation
- Business Statistics - SamplingDocument18 pagesBusiness Statistics - SamplingMelaku WalelgnePas encore d'évaluation
- Bio StatisticsDocument72 pagesBio Statisticsmeherul hasanPas encore d'évaluation
- Sampling & Sampling MethodsDocument26 pagesSampling & Sampling MethodsNeeti MathurPas encore d'évaluation
- SAMPLING FUNDAMENTALSDocument41 pagesSAMPLING FUNDAMENTALSTanmay RajeshPas encore d'évaluation
- Quantitative Methods in ManagementDocument150 pagesQuantitative Methods in Managementsudheer gottetiPas encore d'évaluation
- Wk12 13 Describing Sample and Sampling ProcedureDocument36 pagesWk12 13 Describing Sample and Sampling Procedurejulianalexandra59Pas encore d'évaluation
- Data Management Plan Sampling DesignDocument30 pagesData Management Plan Sampling DesignDhruvil GosaliaPas encore d'évaluation
- Unit 3Document46 pagesUnit 3Khari haranPas encore d'évaluation
- Chapter 4 SAMPLING PDFDocument18 pagesChapter 4 SAMPLING PDFHabte DebelePas encore d'évaluation
- Chapter 2 Statistical Data and SamplingDocument8 pagesChapter 2 Statistical Data and SamplingKent Ivan Delpaz CamposPas encore d'évaluation
- MKTG 4110 Class 14Document5 pagesMKTG 4110 Class 14JSPas encore d'évaluation
- Session 5 Sampling DistributionDocument67 pagesSession 5 Sampling Distributiondipen246Pas encore d'évaluation
- 7 SamplingDocument27 pages7 SamplingHarsono Edwin PuspitaPas encore d'évaluation
- Population and Sample Statistics in 40 CharactersDocument2 pagesPopulation and Sample Statistics in 40 CharactersSummer DantePas encore d'évaluation
- Quantitative Research Design and Sampling MethodsDocument20 pagesQuantitative Research Design and Sampling MethodsMagnolia KhinePas encore d'évaluation
- Research METHODS 1Document33 pagesResearch METHODS 1EUNICE DARKOPas encore d'évaluation
- Research Process and samplingDocument27 pagesResearch Process and samplingrathore.s.singh88Pas encore d'évaluation
- Lecture 0317Document29 pagesLecture 0317Rahul BasnetPas encore d'évaluation
- Statistical Concepts and PrinciplesDocument37 pagesStatistical Concepts and PrinciplespaopaoPas encore d'évaluation
- Sample & Sampling MethodDocument55 pagesSample & Sampling MethodArafat RahmanPas encore d'évaluation
- SamplingDocument30 pagesSamplingShrutiPas encore d'évaluation
- Sampling 8.3.16Document40 pagesSampling 8.3.16Arham SheikhPas encore d'évaluation
- SamplingDocument14 pagesSamplingSir WebsterPas encore d'évaluation
- NCM 111a Notes - 2Document3 pagesNCM 111a Notes - 2Kimberly BucoyPas encore d'évaluation
- 9 Sample DesignDocument42 pages9 Sample Designcesar suarezPas encore d'évaluation
- Research Methods & MaterialsDocument78 pagesResearch Methods & MaterialsSintayehuPas encore d'évaluation
- UN PGA HandbookDocument65 pagesUN PGA HandbookIssey Mari TiongcoPas encore d'évaluation
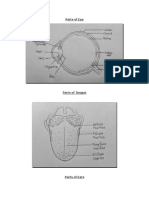
- Parts of EyeDocument2 pagesParts of EyeIssey Mari TiongcoPas encore d'évaluation
- Partnering Initiatives at Country LevelDocument2 pagesPartnering Initiatives at Country LevelIssey Mari TiongcoPas encore d'évaluation
- Learn About The Lhasa Apso:: A Home Study GuideDocument47 pagesLearn About The Lhasa Apso:: A Home Study GuideIssey Mari TiongcoPas encore d'évaluation
- Co CDocument25 pagesCo CIssey Mari TiongcoPas encore d'évaluation
- Research Format PreliminariesDocument1 pageResearch Format PreliminariesIssey Mari TiongcoPas encore d'évaluation
- Learn About The Lhasa Apso:: A Home Study GuideDocument47 pagesLearn About The Lhasa Apso:: A Home Study GuideIssey Mari TiongcoPas encore d'évaluation
- PNG Operational Plan ReportDocument53 pagesPNG Operational Plan ReportIssey Mari TiongcoPas encore d'évaluation
- PNG National Tuberculosis Management Protocol 2011Document46 pagesPNG National Tuberculosis Management Protocol 2011Issey Mari Tiongco100% (3)
- Civil Service Daily Time Record FormDocument2 pagesCivil Service Daily Time Record FormIssey Mari TiongcoPas encore d'évaluation
- PNG National Tuberculosis Management Protocol 2011Document46 pagesPNG National Tuberculosis Management Protocol 2011Issey Mari Tiongco100% (3)
- Brunton Transit ManualDocument15 pagesBrunton Transit ManualReynaldo CruzPas encore d'évaluation
- PNG National Tuberculosis Management Protocol 2011Document46 pagesPNG National Tuberculosis Management Protocol 2011Issey Mari Tiongco100% (3)
- Daily Time Record Form No. 48Document2 pagesDaily Time Record Form No. 48Issey Mari TiongcoPas encore d'évaluation
- Effectiveness of NGPDocument70 pagesEffectiveness of NGPIssey Mari TiongcoPas encore d'évaluation
- Advanced Statistics ReviewerDocument2 pagesAdvanced Statistics ReviewerAloy Dela CruzPas encore d'évaluation
- Philippines Aids 08Document7 pagesPhilippines Aids 08Issey Mari TiongcoPas encore d'évaluation
- PC ProjectDocument1 pagePC ProjectIssey Mari TiongcoPas encore d'évaluation
- 8 27 16 New Long Dealers PriceDocument4 pages8 27 16 New Long Dealers PriceIssey Mari TiongcoPas encore d'évaluation
- ReymillWindmill Sta Rosa NEDocument8 pagesReymillWindmill Sta Rosa NEIssey Mari TiongcoPas encore d'évaluation
- B&W 600 Series BrochureDocument17 pagesB&W 600 Series BrochureIssey Mari TiongcoPas encore d'évaluation
- Forms GSIS Auto Insurance Program PhilippinesDocument1 pageForms GSIS Auto Insurance Program PhilippinesIssey Mari TiongcoPas encore d'évaluation
- Instructions SALN PDFDocument2 pagesInstructions SALN PDFfastreturnPas encore d'évaluation
- Valenzuela City policy on TB referral system for Xpert MTB/RIF testingDocument2 pagesValenzuela City policy on TB referral system for Xpert MTB/RIF testingIssey Mari TiongcoPas encore d'évaluation
- TX SR333 All - Contents PDFDocument194 pagesTX SR333 All - Contents PDFIssey Mari TiongcoPas encore d'évaluation
- NMMA Type Accepted Components GuideDocument7 pagesNMMA Type Accepted Components GuideMuhamad ArifPas encore d'évaluation
- (Et) Bs Player Pro v2.71 Build 1081 Torrent (10Document5 pages(Et) Bs Player Pro v2.71 Build 1081 Torrent (10Ludeilson RodriguesPas encore d'évaluation
- E3.0 Sup Tras 24VDocument3 pagesE3.0 Sup Tras 24VAdrian Romero RomeroPas encore d'évaluation
- Procedimiento Caterpillar de Prueba de ReleDocument11 pagesProcedimiento Caterpillar de Prueba de ReleClaudio Jofre GordilloPas encore d'évaluation
- API Refining Catalogue PDFDocument16 pagesAPI Refining Catalogue PDFSathish KumarPas encore d'évaluation
- HTTrack mirroring errors of mrodrigueza websiteDocument2 pagesHTTrack mirroring errors of mrodrigueza websiteneptuno97Pas encore d'évaluation
- An Analysis of Transformer Failures, Part 1Document4 pagesAn Analysis of Transformer Failures, Part 1Miguel CanoPas encore d'évaluation
- Bphy Verilog HDLDocument11 pagesBphy Verilog HDLPronadeep BoraPas encore d'évaluation
- Metric Conversion GuideDocument36 pagesMetric Conversion GuideAmmar A. Ali100% (2)
- Deliverability Appraisal: Same Person As The Project Sponsor)Document7 pagesDeliverability Appraisal: Same Person As The Project Sponsor)Keeme100% (1)
- Asme Sec Ix IntroDocument24 pagesAsme Sec Ix IntroTim Joseph AlvaroPas encore d'évaluation
- ISC - Actualtests.cissp ISSAP.v2015!03!13.by - Adella.237qDocument68 pagesISC - Actualtests.cissp ISSAP.v2015!03!13.by - Adella.237qdeewanandPas encore d'évaluation
- Drive Lines, Differentials, and Power TrainsDocument44 pagesDrive Lines, Differentials, and Power TrainsAnonymous QiMB2lBCJLPas encore d'évaluation
- R&DProduct DevelopmentDocument14 pagesR&DProduct DevelopmentmufidanPas encore d'évaluation
- Analyzing Systems Using Data Dictionaries: Systems Analysis and Design Kendall and Kendall Fifth EditionDocument56 pagesAnalyzing Systems Using Data Dictionaries: Systems Analysis and Design Kendall and Kendall Fifth EditionDHRUVA100% (1)
- As 1528.2-2001 Tubes (Stainless Steel) and Tube Fittings For The Food Industry Screwed CouplingsDocument7 pagesAs 1528.2-2001 Tubes (Stainless Steel) and Tube Fittings For The Food Industry Screwed CouplingsSAI Global - APACPas encore d'évaluation
- HSN 0101Document130 pagesHSN 0101Jessica PerryPas encore d'évaluation
- Bs en 12350 6 2009 1pdfDocument14 pagesBs en 12350 6 2009 1pdfTIM100% (3)
- Application of Systematic ApproachesDocument2 pagesApplication of Systematic ApproachesSijo JoyPas encore d'évaluation
- SRS Document of Flipkart: IntroductionDocument33 pagesSRS Document of Flipkart: IntroductionSaurabh SinghPas encore d'évaluation
- VLAN Virtual LAN Benefits ConceptsDocument18 pagesVLAN Virtual LAN Benefits ConceptsRishabh ChoudharyPas encore d'évaluation
- XM 1800 S ManualDocument4 pagesXM 1800 S ManualbernardqwertyPas encore d'évaluation
- Set Commands JuniperDocument2 pagesSet Commands Juniperjamski1200Pas encore d'évaluation
- International CV Wiring Diagrams PDFDocument1 039 pagesInternational CV Wiring Diagrams PDFiskandarmustafa100% (1)
- Procedures for Atmospheric TestingDocument2 pagesProcedures for Atmospheric Testingivan20175029bPas encore d'évaluation
- Informatica Lookup GuideDocument4 pagesInformatica Lookup Guidesrikanth.atp5940Pas encore d'évaluation
- 00602-89661-001 Electronic Boost ControlDocument11 pages00602-89661-001 Electronic Boost ControlSupaTouring0% (1)
- Otis Elevator Emergency Phone ManualDocument28 pagesOtis Elevator Emergency Phone ManualBB Players100% (2)
- LED LG 40LF6350 Chasis LJ51HDocument93 pagesLED LG 40LF6350 Chasis LJ51HGiancarloRichardRivadeneyraMirandaPas encore d'évaluation
- CT TheoryDocument37 pagesCT TheoryShahid Ullah100% (1)