Vous aimerez peut-être aussi
- Esp ManualDocument12 pagesEsp Manualjaikolangaraparambil100% (3)
- FPGA System Design Course OverviewDocument30 pagesFPGA System Design Course OverviewKrishna Kumar100% (1)
- Approaches For Power Management Verification of SoC Having Dynamic Power and Voltage SwitchingDocument30 pagesApproaches For Power Management Verification of SoC Having Dynamic Power and Voltage SwitchingNageshwar ReddyPas encore d'évaluation
- Physical DesignDocument12 pagesPhysical DesignPallavi ChPas encore d'évaluation
- Lecture 1 3Document62 pagesLecture 1 3Sivakumar PothirajPas encore d'évaluation
- RTL2GDSFLOWDocument23 pagesRTL2GDSFLOWAbhishek Gupta0% (1)
- Lab2 DCDocument52 pagesLab2 DCRavi Krishna MalkaPas encore d'évaluation
- Spyglass CDCDocument2 pagesSpyglass CDCRahul SharmaPas encore d'évaluation
- VLSI Design - Verilog HDL IntroductionDocument30 pagesVLSI Design - Verilog HDL Introductionanand_duraiswamyPas encore d'évaluation
- Lecture 3 Power Distribution and Clock DesignDocument55 pagesLecture 3 Power Distribution and Clock DesignSiva RaoPas encore d'évaluation
- Unit 7Document54 pagesUnit 7Pavankumar GorpuniPas encore d'évaluation
- Power Reduction Through RTL Clock GatingDocument10 pagesPower Reduction Through RTL Clock GatingAishwarya TekkalakotaPas encore d'évaluation
- Verilog ReviewDocument78 pagesVerilog ReviewsubbuPas encore d'évaluation
- Synopsys ASIC Design Flow TutorialDocument18 pagesSynopsys ASIC Design Flow TutorialNishant Singh100% (1)
- RVfpga SlidesDocument113 pagesRVfpga SlidesSantosh LamaniPas encore d'évaluation
- Low Power Design of Digital SystemsDocument28 pagesLow Power Design of Digital SystemssuperECEPas encore d'évaluation
- Lec1 Setting Up For Redhawk 0Document32 pagesLec1 Setting Up For Redhawk 0siqi liu50% (2)
- SV For Verificaation LabManual v3.0Document22 pagesSV For Verificaation LabManual v3.0Pranav KhuranaPas encore d'évaluation
- Palladium Clocking in ICE/STB FlowDocument20 pagesPalladium Clocking in ICE/STB FlowNaveen TiwariPas encore d'évaluation
- Embedded System and Matlab SIMULINK PDFDocument31 pagesEmbedded System and Matlab SIMULINK PDFclaudiunicolaPas encore d'évaluation
- SENB8604-02 Systems Operation GlossaryDocument41 pagesSENB8604-02 Systems Operation GlossaryChristian BedoyaPas encore d'évaluation
- Systemverilog Advanced Verification Using Uvm: Engineer Explorer SeriesDocument52 pagesSystemverilog Advanced Verification Using Uvm: Engineer Explorer SeriesmadhukirPas encore d'évaluation
- RTL Design IntroductionDocument14 pagesRTL Design Introductionraju mudigondaPas encore d'évaluation
- VCLP Design Flow - Low Power Checks in Multi Voltage DesignsLow-powerDocument7 pagesVCLP Design Flow - Low Power Checks in Multi Voltage DesignsLow-powerAgnathavasiPas encore d'évaluation
- Vlsi Physical DesignDocument26 pagesVlsi Physical Designilias ahmed100% (1)
- Systems On Chip (SoC) - 01Document47 pagesSystems On Chip (SoC) - 01AlfiyanaPas encore d'évaluation
- Digital VLSI Design Lecture 3: Logic Synthesis: Semester A, 2018-19 Lecturer: Dr. Adam TemanDocument47 pagesDigital VLSI Design Lecture 3: Logic Synthesis: Semester A, 2018-19 Lecturer: Dr. Adam TemansrajecePas encore d'évaluation
- Advanced Asic Chip SynthesisDocument126 pagesAdvanced Asic Chip SynthesispravinPas encore d'évaluation
- SystemVerilog VeriflcationDocument68 pagesSystemVerilog VeriflcationMaharaj MmayaPas encore d'évaluation
- HVDC Thesis Mtech Iit Hyd PDFDocument77 pagesHVDC Thesis Mtech Iit Hyd PDFN R SHEKARPas encore d'évaluation
- VerilogDocument226 pagesVerilogNadeem AkramPas encore d'évaluation
- Vlsi Design Study Notes12Document37 pagesVlsi Design Study Notes12gpuonline100% (1)
- Low Power VLSI Design: Abdulla K PDocument30 pagesLow Power VLSI Design: Abdulla K PVijay KumarPas encore d'évaluation
- RTL Compiler ScriptDocument4 pagesRTL Compiler Scriptmuthukumar_eee3659Pas encore d'évaluation
- Lec 15 Multi VDDDocument17 pagesLec 15 Multi VDDvpsampathPas encore d'évaluation
- Features of PCIe Phy LayerDocument6 pagesFeatures of PCIe Phy Layerdipin555100% (1)
- Upf Tutorial InteropforumDocument83 pagesUpf Tutorial InteropforumSayandeep NagPas encore d'évaluation
- Low Power Vlsi Design: Assignment-1 G Abhishek Kumar Reddy, M Manoj VarmaDocument17 pagesLow Power Vlsi Design: Assignment-1 G Abhishek Kumar Reddy, M Manoj VarmamanojPas encore d'évaluation
- VLSI Design - EDA TOOLS PDFDocument83 pagesVLSI Design - EDA TOOLS PDFprathap_somaPas encore d'évaluation
- Building Better IP With RTL Architect NoC IP Physical Exploration by ArterisDocument30 pagesBuilding Better IP With RTL Architect NoC IP Physical Exploration by Arterisyang huPas encore d'évaluation
- VIP Development of SPI Controller For Open-Power Processor Based Fabless SoCDocument6 pagesVIP Development of SPI Controller For Open-Power Processor Based Fabless SoCInternational Journal of Innovative Science and Research TechnologyPas encore d'évaluation
- Study of VLSI Design Methodologies and Limitations Using CAD Tools For CMOS Technology PresentationDocument26 pagesStudy of VLSI Design Methodologies and Limitations Using CAD Tools For CMOS Technology PresentationRoshdy AbdelRassoulPas encore d'évaluation
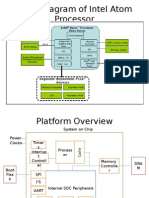
- Block Diagram of Intel Atom ProcessorDocument23 pagesBlock Diagram of Intel Atom Processorfestio94Pas encore d'évaluation
- Verilog HDL Introduction: TextbookDocument41 pagesVerilog HDL Introduction: TextbookAbhishek RanjanPas encore d'évaluation
- FPGA Applications in SpaceDocument5 pagesFPGA Applications in SpacePiyush JainPas encore d'évaluation
- Vivado Design FlowDocument38 pagesVivado Design FlowRamanathanPas encore d'évaluation
- Digital Design Flow OverviewDocument68 pagesDigital Design Flow OverviewAbhiPanchalPas encore d'évaluation
- Mindshare Intro To Pipe SpecDocument15 pagesMindshare Intro To Pipe SpecthecorePas encore d'évaluation
- Extraction and Simulation of Complex Silicon Interposer Structures GIT2012Document20 pagesExtraction and Simulation of Complex Silicon Interposer Structures GIT2012Văn CôngPas encore d'évaluation
- System Verilog TrainingDocument2 pagesSystem Verilog TrainingVlsi GuruPas encore d'évaluation
- Sub1 1 Theory IC Design Flow NguyenHungQuan 201309Document52 pagesSub1 1 Theory IC Design Flow NguyenHungQuan 201309Nguyễn Văn HảoPas encore d'évaluation
- Multilevel Power Estimation of VLSI Circuits Using Neural NetworksDocument63 pagesMultilevel Power Estimation of VLSI Circuits Using Neural NetworkskiwangogPas encore d'évaluation
- HWSW Co Design Unit-1notesDocument195 pagesHWSW Co Design Unit-1notesswapna revuriPas encore d'évaluation
- Low Power Vlsi Design1Document23 pagesLow Power Vlsi Design1Shruthi GourishettiPas encore d'évaluation
- Cmos TestingDocument22 pagesCmos TestingBharathi Muni100% (1)
- CDesignerDocument506 pagesCDesignerrajivsharma1610100% (2)
- BuchblockDocument103 pagesBuchblockRafiqul IslamPas encore d'évaluation
- Arithmetic Logic UnitDocument11 pagesArithmetic Logic UnitPrasanna Kumar VotarikariPas encore d'évaluation
- Parallel Architectures Parallel Architectures: Ever FasterDocument11 pagesParallel Architectures Parallel Architectures: Ever Fastermanishbhardwaj8131Pas encore d'évaluation
- Lecture - 16 Data Flow and Systolic Array ArchitecturesDocument15 pagesLecture - 16 Data Flow and Systolic Array ArchitecturesmohsinmanzoorPas encore d'évaluation
- Tips For OptimizeDocument4 pagesTips For Optimizemayank sharmaPas encore d'évaluation
- 74HC HCT04Document17 pages74HC HCT04Thomz AsadinawanPas encore d'évaluation
- Co AbstractDocument2 pagesCo AbstractYashwanthReddyPas encore d'évaluation
- CDM SheetDocument2 pagesCDM SheetYashwanthReddyPas encore d'évaluation
- UNIT2Document59 pagesUNIT2YashwanthReddyPas encore d'évaluation
- Introduction To Digital CommunicationsDocument12 pagesIntroduction To Digital CommunicationsYashwanthReddyPas encore d'évaluation
- Mwe Test-1 Notes Klusn PDFDocument45 pagesMwe Test-1 Notes Klusn PDFYashwanthReddyPas encore d'évaluation
- Ns Bo AnalysisDocument2 pagesNs Bo AnalysisYashwanthReddyPas encore d'évaluation
- Shanti GrossDocument4 pagesShanti GrossYashwanthReddyPas encore d'évaluation
- Gray To Binary Code Converter: P.V.Yaswanth (13004342) G.Sudheer Kumar (13004347) K.krithi Kumar (13004369)Document10 pagesGray To Binary Code Converter: P.V.Yaswanth (13004342) G.Sudheer Kumar (13004347) K.krithi Kumar (13004369)YashwanthReddy100% (1)
- How To Put Multiple ISO Files in One Bootable USB Disk - Create Multiboot USB DiskDocument12 pagesHow To Put Multiple ISO Files in One Bootable USB Disk - Create Multiboot USB DiskYashwanthReddyPas encore d'évaluation
- Project On Marriage BureauDocument1 pageProject On Marriage BureauYashwanthReddyPas encore d'évaluation
- Klu CCSP ResultsDocument351 pagesKlu CCSP ResultsYashwanthReddyPas encore d'évaluation
- Image Compression Using Discrete Cosine Transform: Team Members: P.V.YASWANTH (13004342) G.SUDHEER KUMAR (13004347)Document7 pagesImage Compression Using Discrete Cosine Transform: Team Members: P.V.YASWANTH (13004342) G.SUDHEER KUMAR (13004347)YashwanthReddyPas encore d'évaluation
- Engg College Ranking 2012Document6 pagesEngg College Ranking 2012shyam_ms2000Pas encore d'évaluation
- Linux Programming: Instructor Name: Mr. N. RajeshDocument22 pagesLinux Programming: Instructor Name: Mr. N. RajeshYashwanthReddyPas encore d'évaluation
- Implimentation and Analysis of Various Sorting TechniquesDocument30 pagesImplimentation and Analysis of Various Sorting TechniquesYashwanthReddyPas encore d'évaluation
- Emft PapersDocument30 pagesEmft PapersYashwanthReddyPas encore d'évaluation
- Recursive Sorting TechniqueDocument13 pagesRecursive Sorting TechniqueYashwanthReddyPas encore d'évaluation
- Rotating EM Field Crack Detection Railway TracksDocument1 pageRotating EM Field Crack Detection Railway TracksYashwanthReddyPas encore d'évaluation
- 60 35474 Feedback AmplifiersDocument55 pages60 35474 Feedback AmplifiersYashwanthReddyPas encore d'évaluation
- Basic InformationDocument1 pageBasic InformationYashwanthReddyPas encore d'évaluation
- HelloDocument1 pageHelloYashwanthReddyPas encore d'évaluation
- Buku 3-Remote SensingDocument75 pagesBuku 3-Remote SensingShine PurbaPas encore d'évaluation
- Crucible 416R Stainless Data SheetDocument2 pagesCrucible 416R Stainless Data SheetMrJohnGaltshrugsPas encore d'évaluation
- Dok TD Iri1 Ere - NewDocument32 pagesDok TD Iri1 Ere - NewirfanWPKPas encore d'évaluation
- EASWARI ENGINEERING COLLEGE PS7005 QUESTION BANKDocument5 pagesEASWARI ENGINEERING COLLEGE PS7005 QUESTION BANKMervin Rodrigo100% (1)
- Research PaperDocument5 pagesResearch Paper2692rimmiPas encore d'évaluation
- Robert Bosch Placement Paper 1 - Freshers ChociDocument11 pagesRobert Bosch Placement Paper 1 - Freshers ChocifresherschoicePas encore d'évaluation
- ExamDocument13 pagesExamHamed GhanbariPas encore d'évaluation
- Assignment 2 On Electromechanical InstrumentsDocument3 pagesAssignment 2 On Electromechanical InstrumentsSumit RaiPas encore d'évaluation
- EM InductionDocument10 pagesEM InductionSatyaki ChowdhuryPas encore d'évaluation
- Mini Project List For Sem III: 1. RC DifferentiatorDocument4 pagesMini Project List For Sem III: 1. RC DifferentiatorAnonymous VASS3z0wTHPas encore d'évaluation
- Nobel Lecture The Double HeterostructureDocument16 pagesNobel Lecture The Double Heterostructuremglez2012Pas encore d'évaluation
- Microwave ExperimentDocument10 pagesMicrowave ExperimentsachinPas encore d'évaluation
- Datasheet 42Document18 pagesDatasheet 42Roozbeh Bahmanyar100% (1)
- Trescientos Uno Flanger: Resistors Trim Pots Parts ListDocument1 pageTrescientos Uno Flanger: Resistors Trim Pots Parts ListYeremia OyaPas encore d'évaluation
- How To Test The High Voltage CapacitorDocument3 pagesHow To Test The High Voltage CapacitorShonPas encore d'évaluation
- REN Isl95338 DST 20190619Document51 pagesREN Isl95338 DST 20190619Charles PPas encore d'évaluation
- Manson Ep-925 Modifications: EP-925 and PALSTAR PS-30MDocument6 pagesManson Ep-925 Modifications: EP-925 and PALSTAR PS-30MLaurentiu IacobPas encore d'évaluation
- Shantou Huashan Electronic Devices Co.,Ltd.: CBO CEO EBO CES FE CE (Sat) BE (ON) TDocument2 pagesShantou Huashan Electronic Devices Co.,Ltd.: CBO CEO EBO CES FE CE (Sat) BE (ON) TRãŸàñe HãmãdouçhéPas encore d'évaluation
- Leroy Somer Alternator Datasheet LSA 47.2 - 4 PoleDocument12 pagesLeroy Somer Alternator Datasheet LSA 47.2 - 4 PoleJuan Pablo Zubieta Jemio100% (1)
- DIAC characteristics and applications in triac triggering circuitsDocument7 pagesDIAC characteristics and applications in triac triggering circuitsBaquiran John Paul BaquiranPas encore d'évaluation
- Kgd0h000dm-Application ProcessorDocument5 pagesKgd0h000dm-Application ProcessorMihimbiPas encore d'évaluation
- sm1600 GBDocument4 pagessm1600 GBTran Hong HiepPas encore d'évaluation
- 74HC HCT4066 NXPDocument27 pages74HC HCT4066 NXPprpabst8514Pas encore d'évaluation
- B2-50 SchematicDocument15 pagesB2-50 Schematicmuminpapa100% (1)
- Twido TWDLCAE40DRFDocument3 pagesTwido TWDLCAE40DRFCarlos Tito MoyaPas encore d'évaluation
- Materials Chemistry B: Journal ofDocument32 pagesMaterials Chemistry B: Journal ofpriyaPas encore d'évaluation
- HDB3 ReportDocument98 pagesHDB3 ReportCornel CaceamacPas encore d'évaluation