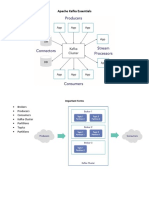
Vous aimerez peut-être aussi
- Real Time Analytics With Apache Kafka and Spark: Rahul JainDocument54 pagesReal Time Analytics With Apache Kafka and Spark: Rahul JainSudhanshoo SaxenaPas encore d'évaluation
- Unit 5Document109 pagesUnit 5Rajesh Kumar RakasulaPas encore d'évaluation
- 09 Programming Hadoop - Spark, R and PigDocument80 pages09 Programming Hadoop - Spark, R and PigNeeraj GargPas encore d'évaluation
- Bigdata NotesDocument26 pagesBigdata NotesAnil YarlagaddaPas encore d'évaluation
- Interview QuestionDocument24 pagesInterview QuestionAnil YarlagaddaPas encore d'évaluation
- Programming Environments On Sahasrat (Cray-Xc40 System)Document38 pagesProgramming Environments On Sahasrat (Cray-Xc40 System)dhruvbhagtaniPas encore d'évaluation
- Spark Vs Hadoop Features SparkDocument9 pagesSpark Vs Hadoop Features SparkconsaniaPas encore d'évaluation
- Distributed Database Systems: - Spark IDocument59 pagesDistributed Database Systems: - Spark IThomas AriyantoPas encore d'évaluation
- Sharp PcapDocument21 pagesSharp PcapTamir GalPas encore d'évaluation
- Apache Spark Ecosystem - Complete Spark Components Guide: 1. ObjectiveDocument11 pagesApache Spark Ecosystem - Complete Spark Components Guide: 1. Objectivedivya kolluriPas encore d'évaluation
- Cma CicdDocument44 pagesCma CicdSureka SwaminathanPas encore d'évaluation
- Spark in ProductionDocument34 pagesSpark in ProductionSridhar PlvPas encore d'évaluation
- Name: Wable Snehal Mahesh Subject:-Scala & Spark Div: - Mba Ii Roll No: - 57 Guidence Name: - Prof. Archana Suryawanshi - KadamDocument11 pagesName: Wable Snehal Mahesh Subject:-Scala & Spark Div: - Mba Ii Roll No: - 57 Guidence Name: - Prof. Archana Suryawanshi - KadamSnehal Mahesh WablePas encore d'évaluation
- 5 Spark Kafka Cassandra Slides PDFDocument20 pages5 Spark Kafka Cassandra Slides PDFusernameusernaPas encore d'évaluation
- Apache Spark: Data Science FoundationsDocument55 pagesApache Spark: Data Science FoundationsTRAPMUZIC HDTVPas encore d'évaluation
- 0 - Oracle Full & SQL TopicDocument168 pages0 - Oracle Full & SQL TopicDivili PadmavathiPas encore d'évaluation
- PySpark+Slides v1Document458 pagesPySpark+Slides v1ravikumar lankaPas encore d'évaluation
- Big Data Meets HPCDocument3 pagesBig Data Meets HPCPeterJohn32Pas encore d'évaluation
- Parallel Libraries and Parallel I/O: John UrbanicDocument45 pagesParallel Libraries and Parallel I/O: John UrbanicarjunPas encore d'évaluation
- What Is Spark?: History of Apache SparkDocument65 pagesWhat Is Spark?: History of Apache SparkApurvaPas encore d'évaluation
- PratyushDocument18 pagesPratyushNilesh NiralePas encore d'évaluation
- Kafka Patterns and Anti-PatternsDocument7 pagesKafka Patterns and Anti-PatternsRafael RegoPas encore d'évaluation
- Building A Replicated Logging System With Apache KafkaDocument2 pagesBuilding A Replicated Logging System With Apache KafkaLuana SantosPas encore d'évaluation
- Kafka: Big Data Huawei CourseDocument14 pagesKafka: Big Data Huawei CourseThiago SiqueiraPas encore d'évaluation
- Aula01.3bCe240Ce245Ce229CEDS84121c (Apache Spark)Document30 pagesAula01.3bCe240Ce245Ce229CEDS84121c (Apache Spark)Victor Tavares AlvarengaPas encore d'évaluation
- Getting Started With Apache Kafka in Python - Towards Data Science PDFDocument17 pagesGetting Started With Apache Kafka in Python - Towards Data Science PDFDeven MaliPas encore d'évaluation
- Speeding Up R With Multithreading, Task Merging, and Other TechniquesDocument30 pagesSpeeding Up R With Multithreading, Task Merging, and Other TechniquesAda YungPas encore d'évaluation
- Kafka SparkstreamingDocument75 pagesKafka SparkstreamingDastagiri SahebPas encore d'évaluation
- Spark Interview Questions and AnswersDocument31 pagesSpark Interview Questions and Answerssrinivas75k100% (1)
- Aksha Interview QuestionsDocument52 pagesAksha Interview QuestionsNadeem Khan100% (1)
- DocumentationDocument105 pagesDocumentationSumit Kumar AwkashPas encore d'évaluation
- 2021 09 24 Scalable-Monitoring-ToolsDocument49 pages2021 09 24 Scalable-Monitoring-ToolsleufmPas encore d'évaluation
- Acna18 Apache Karaf in The EnterpriseDocument35 pagesAcna18 Apache Karaf in The EnterpriseRonaldMartinezPas encore d'évaluation
- Extreme Replication - Performance Tuning Oracle GoldenGate by Bobby Curtis (UTOUG 2015 Fall Conference)Document60 pagesExtreme Replication - Performance Tuning Oracle GoldenGate by Bobby Curtis (UTOUG 2015 Fall Conference)ZULU490Pas encore d'évaluation
- Stream Processing Using KafkaDocument46 pagesStream Processing Using Kafka1himaniaroraPas encore d'évaluation
- MOSAIKSOAPDocument11 pagesMOSAIKSOAPanshulvyas23Pas encore d'évaluation
- Spark-RddDocument15 pagesSpark-RddK Anantha KrishnanPas encore d'évaluation
- File:///E:/Profwork/Dataengineer - Course/File/Literation/Data Pipelines With Oskari Saarenmaa Postgresql Amp Kafka PDFDocument3 pagesFile:///E:/Profwork/Dataengineer - Course/File/Literation/Data Pipelines With Oskari Saarenmaa Postgresql Amp Kafka PDFAchmad ArdiPas encore d'évaluation
- BDA LabCompendiumDocument6 pagesBDA LabCompendiumKiS MintPas encore d'évaluation
- KafkaDocument23 pagesKafkaPHƯƠNG THẢOPas encore d'évaluation
- Apache Spark Interview GuideDocument22 pagesApache Spark Interview GuideVenmo 61930% (1)
- Kafka StreamsDocument129 pagesKafka Streamsksg.developerPas encore d'évaluation
- Prasanth Kothuri, Danilo Piparo, Enric Tejedor Saavedra, Diogo Castro Cern It and Ep-SftDocument22 pagesPrasanth Kothuri, Danilo Piparo, Enric Tejedor Saavedra, Diogo Castro Cern It and Ep-SftAde RahmanPas encore d'évaluation
- Manual Stack To STamPSDocument8 pagesManual Stack To STamPSgwisnuPas encore d'évaluation
- Spark Overview: SecurityDocument4 pagesSpark Overview: SecuritygathorsfxPas encore d'évaluation
- Spark Kafkaintegration PDFDocument71 pagesSpark Kafkaintegration PDFehenry100% (1)
- Getting To Know Kafka: Ola Is The First Course in The Series of Courses Covering All The Aspects of KafkaDocument23 pagesGetting To Know Kafka: Ola Is The First Course in The Series of Courses Covering All The Aspects of KafkaMahesh VPPas encore d'évaluation
- Apache ZookeeperDocument31 pagesApache ZookeeperTripti SagarPas encore d'évaluation
- Netflix Kafka 150325105558 Conversion Gate01Document49 pagesNetflix Kafka 150325105558 Conversion Gate01VadlamaniKalyanPas encore d'évaluation
- Spark TraningDocument32 pagesSpark TraningMochaPas encore d'évaluation
- Bda Unit-4 PDFDocument63 pagesBda Unit-4 PDFHarryPas encore d'évaluation
- Kafka For BeginnersDocument77 pagesKafka For Beginnersspjb33Pas encore d'évaluation
- Nutch Tutorial Hadoop ArchitectureDocument20 pagesNutch Tutorial Hadoop ArchitectureLúa Pérez BarrosPas encore d'évaluation
- Apache KafkaDocument6 pagesApache KafkaJason GomezPas encore d'évaluation
- A Deep Dive Into Query Execution Engine of Spark SQLDocument88 pagesA Deep Dive Into Query Execution Engine of Spark SQLmaghnus100% (2)
- Cloudurable Kafka Tutorial v1 PDFDocument79 pagesCloudurable Kafka Tutorial v1 PDFakash bPas encore d'évaluation
- Pcap LibDocument4 pagesPcap LibB20DCAT088 Lưu Văn HưngPas encore d'évaluation
- Accelerating Electronic Trading: Mellanox Adapter CardsDocument2 pagesAccelerating Electronic Trading: Mellanox Adapter CardsOzioma IhekwoabaPas encore d'évaluation
- Architecting Petabyte-Scale Analytics by Scaling Out Postgres On Azure With CitusDocument32 pagesArchitecting Petabyte-Scale Analytics by Scaling Out Postgres On Azure With CitusOzioma IhekwoabaPas encore d'évaluation
- What's New in Spring Cloud?: Oleg Zhurakousky Olga Maciaszek-SharmaDocument36 pagesWhat's New in Spring Cloud?: Oleg Zhurakousky Olga Maciaszek-SharmaOzioma IhekwoabaPas encore d'évaluation
- Improving Manufacturing Performance With Big Data: Architect's Guide and Reference Architecture IntroductionDocument23 pagesImproving Manufacturing Performance With Big Data: Architect's Guide and Reference Architecture IntroductionOzioma IhekwoabaPas encore d'évaluation
- Vignesh Sukumar SVCC 2012Document25 pagesVignesh Sukumar SVCC 2012Ozioma IhekwoabaPas encore d'évaluation
- Sample SLA Templates PDFDocument14 pagesSample SLA Templates PDFOzioma Ihekwoaba100% (2)
- Defining The Big Data Architecture FrameworkDocument55 pagesDefining The Big Data Architecture FrameworkOzioma IhekwoabaPas encore d'évaluation
- Scaling Up Genomic Analysis With ADAMDocument23 pagesScaling Up Genomic Analysis With ADAMOzioma IhekwoabaPas encore d'évaluation
- Paper 4-Churn Prediction in Telecommunication PDFDocument3 pagesPaper 4-Churn Prediction in Telecommunication PDFOzioma IhekwoabaPas encore d'évaluation
- Telecom Billing PDFDocument33 pagesTelecom Billing PDFOzioma IhekwoabaPas encore d'évaluation
- Visualizing Big Data in The Browser Using Spark: Hossein Falaki @mhfalaki Spark Summit East - March 18, 2015Document17 pagesVisualizing Big Data in The Browser Using Spark: Hossein Falaki @mhfalaki Spark Summit East - March 18, 2015Ozioma IhekwoabaPas encore d'évaluation
- A Case Study Report On Churn Analysis: Submitted To Mr. Sanjay Rao Founder, Axion Connect Presented by Amit KumarDocument8 pagesA Case Study Report On Churn Analysis: Submitted To Mr. Sanjay Rao Founder, Axion Connect Presented by Amit KumarOzioma IhekwoabaPas encore d'évaluation
- Horton Works Sparko DBC Driver User GuideDocument87 pagesHorton Works Sparko DBC Driver User GuideOzioma IhekwoabaPas encore d'évaluation
- Higher Education Qualifications BCS Level 4 Certificate in IT October 2009 Examiners' Report Information SystemsDocument9 pagesHigher Education Qualifications BCS Level 4 Certificate in IT October 2009 Examiners' Report Information SystemsOzioma IhekwoabaPas encore d'évaluation
- Se22 - 20110124 UML1Document28 pagesSe22 - 20110124 UML1Ozioma IhekwoabaPas encore d'évaluation
- Core AppDocument680 pagesCore Appvijay AkkaladeviPas encore d'évaluation
- Prashant (1) .Shrivastava Resume (System Admin)Document2 pagesPrashant (1) .Shrivastava Resume (System Admin)Sapna MathurPas encore d'évaluation
- Csol 580 Week 7Document8 pagesCsol 580 Week 7api-487513274Pas encore d'évaluation
- A 6 R 4Document2 pagesA 6 R 4Ghanshyam SharmaPas encore d'évaluation
- Vulnerability Assessment - MundyDavidDocument3 pagesVulnerability Assessment - MundyDavidDavid MundyPas encore d'évaluation
- Ludwig ResumeDocument1 pageLudwig Resumeapi-239918830Pas encore d'évaluation
- Alphabet Hats BLOGDocument27 pagesAlphabet Hats BLOGใน นา มี ปูPas encore d'évaluation
- AutoCad 2000 Command List - 300 ComandosDocument6 pagesAutoCad 2000 Command List - 300 Comandosdossantos1975100% (2)
- Module 5Document51 pagesModule 5Reshma SindhuPas encore d'évaluation
- X Virtual ServerDocument8 pagesX Virtual ServerAnitosh SahaPas encore d'évaluation
- KMS, Artificial Intelligence, & The Economist 20150509Document47 pagesKMS, Artificial Intelligence, & The Economist 20150509the1uploaderPas encore d'évaluation
- Ingo Zinner IT Internal Audit SupervisorDocument3 pagesIngo Zinner IT Internal Audit Supervisoringozinner100% (1)
- Extracting Data From Hyperion EssbaseDocument14 pagesExtracting Data From Hyperion EssbaseWichaiWongchariyakulPas encore d'évaluation
- An Introduction To The BIOS: in This GuideDocument3 pagesAn Introduction To The BIOS: in This GuideAnilPas encore d'évaluation
- Hardware-Software Design of Embedded SystemsDocument69 pagesHardware-Software Design of Embedded SystemsOnur FilizoğluPas encore d'évaluation
- Rufus - Create Bootable USB Drives The Easy WayDocument6 pagesRufus - Create Bootable USB Drives The Easy WayÑiechztQS20% (5)
- Error Control Coding Fundamentals and Applications by Shu Lin PDFDocument2 pagesError Control Coding Fundamentals and Applications by Shu Lin PDFMaggie0% (1)
- DB Firewall LabsDocument58 pagesDB Firewall Labsnt29Pas encore d'évaluation
- Installation InstructionsDocument3 pagesInstallation InstructionsThiago100% (1)
- Strategic Outsourcing: Dr. S. K. MajumdarDocument30 pagesStrategic Outsourcing: Dr. S. K. MajumdarArun Kumar T KPas encore d'évaluation
- Cyber Boot Camp - Day 05 - Cyber Security FrameworkDocument3 pagesCyber Boot Camp - Day 05 - Cyber Security FrameworkAnna Margarita de VegaPas encore d'évaluation
- There Were 16 Aptitude Questions Given For 20 MinutesDocument13 pagesThere Were 16 Aptitude Questions Given For 20 MinutesjabirkkPas encore d'évaluation
- Dress RoomDocument3 pagesDress RoomNicolas SolisPas encore d'évaluation
- License Agreement PDFDocument2 pagesLicense Agreement PDFNigov ChigovPas encore d'évaluation
- 828D DA 1015 en en-USDocument1 232 pages828D DA 1015 en en-USДаниил ТиуновPas encore d'évaluation
- Zünd Cut Center: Digital Cutting WorkflowDocument6 pagesZünd Cut Center: Digital Cutting WorkflowMirjana EricPas encore d'évaluation
- Logix 5000 Controlers I/O & Tag DataDocument76 pagesLogix 5000 Controlers I/O & Tag Datafrancois lecreuxPas encore d'évaluation
- Window View Port Mapping Computer GraphicsDocument18 pagesWindow View Port Mapping Computer GraphicsNadisha Fathima100% (1)
- GCSE Computing OCR-OnlineDocument161 pagesGCSE Computing OCR-OnlineAum Patel100% (2)
- ApogeeX 2.5.0 InstallGuideDocument200 pagesApogeeX 2.5.0 InstallGuidegeorgemathew111Pas encore d'évaluation