Vous aimerez peut-être aussi
- K Nearest Neighbor Algorithm: Fundamentals and ApplicationsD'EverandK Nearest Neighbor Algorithm: Fundamentals and ApplicationsPas encore d'évaluation
- What Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDocument42 pagesWhat Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDineshkannan RaviPas encore d'évaluation
- Unit Iv Cluster Analysis What Is Clusteranalysis?Document24 pagesUnit Iv Cluster Analysis What Is Clusteranalysis?Hit ManPas encore d'évaluation
- M8 KlasteringDocument83 pagesM8 KlasteringTeofilus EvanPas encore d'évaluation
- 5 Algoritma KlasteringDocument85 pages5 Algoritma Klasteringicobes urPas encore d'évaluation
- ClusteringDocument80 pagesClusteringAatmaj SalunkePas encore d'évaluation
- Chapter 5Document43 pagesChapter 5Bikila SeketaPas encore d'évaluation
- Unit 4 - Data Warehousing and MiningDocument51 pagesUnit 4 - Data Warehousing and Miningà S ÀdhìkãríPas encore d'évaluation
- 06 Cluster AnalysisDocument34 pages06 Cluster Analysishawariya abelPas encore d'évaluation
- Custer Analysis: Prepared by Navin NinamaDocument20 pagesCuster Analysis: Prepared by Navin NinamaNishith LakhlaniPas encore d'évaluation
- Unsupervised Learning ModiDocument16 pagesUnsupervised Learning ModiSatishKakarlaPas encore d'évaluation
- Final ClusteringDocument21 pagesFinal ClusteringNEEL GHADIYAPas encore d'évaluation
- Partitioning MethodsDocument3 pagesPartitioning MethodsDiyar T Alzuhairi100% (1)
- GroupingDocument98 pagesGroupingAditya PatelPas encore d'évaluation
- Sathyabama Institute of Science and Technology SIT1301-Data Mining and WarehousingDocument22 pagesSathyabama Institute of Science and Technology SIT1301-Data Mining and WarehousingviktahjmPas encore d'évaluation
- ClusteringDocument104 pagesClusteringDev kartik AgarwalPas encore d'évaluation
- Data Mining: I Gede Mahendra DarmawigunaDocument25 pagesData Mining: I Gede Mahendra DarmawigunaBitboxkPas encore d'évaluation
- Unit Ii DMDocument82 pagesUnit Ii DMSuganthi D PSGRKCWPas encore d'évaluation
- CLIQUE and PROCLUSDocument13 pagesCLIQUE and PROCLUSTanya SharmaPas encore d'évaluation
- Clustering Algorithm: An Unsupervised Learning ApproachDocument23 pagesClustering Algorithm: An Unsupervised Learning ApproachSyedDabeerAliPas encore d'évaluation
- Clustering K Means AgnesDocument36 pagesClustering K Means AgnespreetamPas encore d'évaluation
- Data Mining-Partitioning MethodsDocument7 pagesData Mining-Partitioning MethodsRaj Endran100% (1)
- Cluster AnalysisDocument24 pagesCluster Analysissakshi sharmaPas encore d'évaluation
- ClusteringDocument7 pagesClusteringmarina.villanuevaPas encore d'évaluation
- DM Lecture 06Document32 pagesDM Lecture 06Sameer AhmadPas encore d'évaluation
- Object RecognitionDocument43 pagesObject RecognitionA JPas encore d'évaluation
- Chapter 4 PDFDocument89 pagesChapter 4 PDFAnirudh TripathiPas encore d'évaluation
- Unit 4Document4 pagesUnit 4adityapawar1865Pas encore d'évaluation
- Cluster Analysis ClusteringDocument6 pagesCluster Analysis Clustering17CSE97- VIKASHINI TPPas encore d'évaluation
- Data Mining CH - 5Document18 pagesData Mining CH - 5Hasset Tiss Abay GenjiPas encore d'évaluation
- 6.nsupervised Learning Clustering Lecture 7 Slides For4962Document37 pages6.nsupervised Learning Clustering Lecture 7 Slides For4962nimrashafiq604Pas encore d'évaluation
- DMW Unit-VDocument47 pagesDMW Unit-VRavindra PawarPas encore d'évaluation
- DM BS Lec8 ClusteringDocument48 pagesDM BS Lec8 ClusteringrubaPas encore d'évaluation
- What Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDocument9 pagesWhat Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsIrum FatimaPas encore d'évaluation
- Unsupervised Machine Learning TechniquesDocument24 pagesUnsupervised Machine Learning TechniquesABDULHAMIDPas encore d'évaluation
- Data Clustering With RDocument30 pagesData Clustering With Rwirapong chansanamPas encore d'évaluation
- 16 dm2 Dimred 2022 23Document49 pages16 dm2 Dimred 2022 23nimraPas encore d'évaluation
- ACFrOgCajrghX8QYes4eQZ0sdYkSYcgCfngE3 G40h28YsPxSNUI5pWUj1kIOR5d1d2nVkHBNqBJQVMMKTJ6lSwm5kuENTMySlduAvwhEcn-N5iutSBNaAaDhkol5Hv3mPmTl0q-ahwmr7GR 2cjDocument95 pagesACFrOgCajrghX8QYes4eQZ0sdYkSYcgCfngE3 G40h28YsPxSNUI5pWUj1kIOR5d1d2nVkHBNqBJQVMMKTJ6lSwm5kuENTMySlduAvwhEcn-N5iutSBNaAaDhkol5Hv3mPmTl0q-ahwmr7GR 2cjethanPas encore d'évaluation
- Unsupervised LearningDocument12 pagesUnsupervised LearningRevathi KalyanasundaramPas encore d'évaluation
- Data Mining Data Transformations: Gergely LukácsDocument51 pagesData Mining Data Transformations: Gergely LukácsBlazsPas encore d'évaluation
- W6 ClusteringDocument29 pagesW6 Clustering5599RAJNISH SINGHPas encore d'évaluation
- Unit 5Document31 pagesUnit 5minichelPas encore d'évaluation
- DMW Assignment 2Document4 pagesDMW Assignment 2mad worldPas encore d'évaluation
- IML Assignment 6 ReportDocument18 pagesIML Assignment 6 ReportHasya PatelPas encore d'évaluation
- Presentation: Operating System Concept CS-582Document13 pagesPresentation: Operating System Concept CS-582Mujtaba HassanPas encore d'évaluation
- Datamining - RevitedDocument8 pagesDatamining - RevitedBridget SmithPas encore d'évaluation
- DuongToGiangSon 517H0162 HW2 Nov-26Document17 pagesDuongToGiangSon 517H0162 HW2 Nov-26Son TranPas encore d'évaluation
- Data Mining Unit 3 Cluster Analysis: Types of ClustersDocument11 pagesData Mining Unit 3 Cluster Analysis: Types of ClustersrohanPas encore d'évaluation
- ClusteringDocument22 pagesClusteringUtkarsh SrivastavPas encore d'évaluation
- 10 Clus BasicDocument92 pages10 Clus BasicMike KuPas encore d'évaluation
- MachineLearning - Algorithms - TaggedDocument35 pagesMachineLearning - Algorithms - TaggedAnthony CorneauPas encore d'évaluation
- w6 ClusteringDocument29 pagesw6 ClusteringSrisha Prasad RathPas encore d'évaluation
- DM Chapter 5 (Clustering)Document40 pagesDM Chapter 5 (Clustering)world channelPas encore d'évaluation
- Comparison of Density-Based Clustering Algorithms: Mariam RehmanDocument5 pagesComparison of Density-Based Clustering Algorithms: Mariam RehmansuserPas encore d'évaluation
- Chapter 5 ClusteringDocument40 pagesChapter 5 ClusteringMohamedsultan AwolPas encore d'évaluation
- Technical Seminar On K-Means Clustering in Data Mining: Darshna Sharma 1HK18IS086 Guide: Prof. Priyanka KDocument22 pagesTechnical Seminar On K-Means Clustering in Data Mining: Darshna Sharma 1HK18IS086 Guide: Prof. Priyanka KDarshna SharmaPas encore d'évaluation
- Data Mining: Kabith Sivaprasad (BE/1234/2009) Rimjhim (BE/1134/2009) Utkarsh Ahuja (BE/1226/2009)Document32 pagesData Mining: Kabith Sivaprasad (BE/1234/2009) Rimjhim (BE/1134/2009) Utkarsh Ahuja (BE/1226/2009)Rule2Pas encore d'évaluation
- Machine Learning UnsupervisedDocument13 pagesMachine Learning UnsupervisedAbhinandan GhoshPas encore d'évaluation
- Supervised Learning 1 PDFDocument162 pagesSupervised Learning 1 PDFAlexanderPas encore d'évaluation
- CLARANSDocument19 pagesCLARANSAndreea Simona BadoiuPas encore d'évaluation
- Gujarat Technological UniversityDocument1 pageGujarat Technological Universityfeyayel988Pas encore d'évaluation
- 11 Most Common Machine Learning Algorithms Explained in A Nutshell by Soner Yıldırım Towards Data ScienceDocument16 pages11 Most Common Machine Learning Algorithms Explained in A Nutshell by Soner Yıldırım Towards Data ScienceDheeraj SonkhlaPas encore d'évaluation
- 2021 IWBF Classification Rules Version 202110 1Document108 pages2021 IWBF Classification Rules Version 202110 1Sebastian Alfaro AlarconPas encore d'évaluation
- MLT MCQDocument13 pagesMLT MCQSinduja BaskaranPas encore d'évaluation
- Pattern Recognition ApplicationDocument43 pagesPattern Recognition ApplicationKhaled OmarPas encore d'évaluation
- Apples, Reeds, Pairwise, Graph BasedDocument8 pagesApples, Reeds, Pairwise, Graph Basedsudhakarr1983100% (1)
- Lec7 KNN NTDocument42 pagesLec7 KNN NTJaveriaPas encore d'évaluation
- DMDW Case Study FinishedDocument28 pagesDMDW Case Study FinishedYOSEPH TEMESGEN ITANAPas encore d'évaluation
- ND White Paper - FaceReader Methodology ScreenDocument6 pagesND White Paper - FaceReader Methodology ScreenFabricio VincesPas encore d'évaluation
- Using Decision Trees in Order To Determine Intersection Design RulesDocument15 pagesUsing Decision Trees in Order To Determine Intersection Design RulesuykuykPas encore d'évaluation
- 125-Article Text-694-1-10-20210625Document25 pages125-Article Text-694-1-10-20210625Haikal LimansahPas encore d'évaluation
- Classification Through Machine Learning Technique: C4.5 Algorithm Based On Various EntropiesDocument8 pagesClassification Through Machine Learning Technique: C4.5 Algorithm Based On Various EntropiesMohamed Hechmi JERIDIPas encore d'évaluation
- Question Bank AnnDocument2 pagesQuestion Bank AnnSohini Ghosh100% (1)
- Business StatisticsDocument506 pagesBusiness StatisticsLokesh Baskaran100% (22)
- Clustering Documentation Python CodeDocument8 pagesClustering Documentation Python Codenehal gundrapallyPas encore d'évaluation
- Bird Species Classification Using Deep Learning Literature SurveyDocument27 pagesBird Species Classification Using Deep Learning Literature Surveyharshithays100% (2)
- Masquerade Attack DetectionDocument17 pagesMasquerade Attack Detectionwingwingxd61Pas encore d'évaluation
- LTE RF Conditions ClassificationDocument3 pagesLTE RF Conditions Classificationse7en_csPas encore d'évaluation
- CPC ProvisionalDocument433 pagesCPC ProvisionalhddkickPas encore d'évaluation
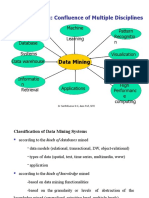
- 4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionDocument4 pages4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionLikith MallipeddiPas encore d'évaluation
- Sentiment AnalysisDocument198 pagesSentiment AnalysisSoonu Aravindan100% (1)
- Topic 5Document32 pagesTopic 5hmood966Pas encore d'évaluation
- AI&ML-FluidMech-Chapter ML Mendez 2020 LS OptDocument66 pagesAI&ML-FluidMech-Chapter ML Mendez 2020 LS OptlighthilljPas encore d'évaluation
- Sarkar, Dipayan. - Natarajan, Vijayalakshmi. - Ensemble Machine Learning Cookbook-Packt Publishing (2019)Document476 pagesSarkar, Dipayan. - Natarajan, Vijayalakshmi. - Ensemble Machine Learning Cookbook-Packt Publishing (2019)omegapoint077609100% (2)
- 1 The Bank Loan Approval Decision From Multiple PerspectivesDocument8 pages1 The Bank Loan Approval Decision From Multiple PerspectivesAtakelt HailuPas encore d'évaluation
- SPE-190812-MS - Status of Data-Driven Methods and Their Applications in Oil and Gas IndustryDocument18 pagesSPE-190812-MS - Status of Data-Driven Methods and Their Applications in Oil and Gas IndustryМарина МосоянPas encore d'évaluation
- A Multi-Temporal Approach in MaxEnt Modelling A New Frontier For Land Use Land Cover Change DetectionDocument33 pagesA Multi-Temporal Approach in MaxEnt Modelling A New Frontier For Land Use Land Cover Change DetectionHamzaPas encore d'évaluation
- Week 6 - Data Mining For BIDocument34 pagesWeek 6 - Data Mining For BIManzur AshrafPas encore d'évaluation
- PGDAS Brochure 5aug2022Document19 pagesPGDAS Brochure 5aug2022arindamsinharayPas encore d'évaluation
- A Practical Guide To Artificial Intelligence-Based Image Analysis in RadiologyDocument7 pagesA Practical Guide To Artificial Intelligence-Based Image Analysis in RadiologyGenePas encore d'évaluation