Vous aimerez peut-être aussi
- DWDM Notes/Unit 1Document31 pagesDWDM Notes/Unit 1Thams ThamaraiPas encore d'évaluation
- Question BankDocument16 pagesQuestion BankHAnsianPas encore d'évaluation
- Newspaper Agency System DocumentationDocument29 pagesNewspaper Agency System Documentationshrankhlasingh0% (1)
- Text Editor (Synopsis)Document8 pagesText Editor (Synopsis)sanjaykumarguptaa100% (1)
- Intelligent AttendanceDocument14 pagesIntelligent Attendanceram krishnaPas encore d'évaluation
- PPL Unit-1Document19 pagesPPL Unit-1Vishnu Pujari100% (1)
- Joomla PPTDocument30 pagesJoomla PPTarijitsinha99Pas encore d'évaluation
- The Barrelfish Operating System: MultiKernel For MulticoresDocument14 pagesThe Barrelfish Operating System: MultiKernel For MulticoresAiniAbalPas encore d'évaluation
- What Is Project SynopsisDocument3 pagesWhat Is Project SynopsisKumar AbhishekPas encore d'évaluation
- Cs2032 Data Warehousing and Data Mining Notes (Unit III) .PDF - Www.chennaiuniversity - Net.notesDocument54 pagesCs2032 Data Warehousing and Data Mining Notes (Unit III) .PDF - Www.chennaiuniversity - Net.notesUjjWal MahAjanPas encore d'évaluation
- Question Bank OomdDocument3 pagesQuestion Bank OomdRanjitha Manjunath100% (1)
- Aim & Algorithm Program Results Viva-Voce Record Total 20 40 20 10 10 100Document5 pagesAim & Algorithm Program Results Viva-Voce Record Total 20 40 20 10 10 100VINOD D50% (4)
- Bus ReservationDocument18 pagesBus ReservationDheeraj Babu100% (3)
- Library Management System ReportDocument13 pagesLibrary Management System ReportAshiwani N100% (1)
- Data Structure Using C: Proposal On Phone Directory Application Using Doubly-Linked ListDocument5 pagesData Structure Using C: Proposal On Phone Directory Application Using Doubly-Linked Listgirish desaiPas encore d'évaluation
- U4 - The Shell's Interpretive Cycle - 37 - 18-11-20Document3 pagesU4 - The Shell's Interpretive Cycle - 37 - 18-11-20Shantanu AgnihotriPas encore d'évaluation
- NETWORKING BCA WBUT 5th SEM NOTESDocument135 pagesNETWORKING BCA WBUT 5th SEM NOTESapi-1958925986% (22)
- Spos Lab ManualDocument41 pagesSpos Lab ManualAlbert Einstein100% (1)
- Intelligent Disk SubsystemsDocument69 pagesIntelligent Disk SubsystemsjohnPas encore d'évaluation
- Study of Unix CommandsDocument22 pagesStudy of Unix CommandsChetana KestikarPas encore d'évaluation
- Model patterns and frameworks with UML diagramsDocument12 pagesModel patterns and frameworks with UML diagramstrnithiPas encore d'évaluation
- BookstoreDocument9 pagesBookstoreAbhishek MudaliarPas encore d'évaluation
- Cloud Computing Lab Manual 1Document25 pagesCloud Computing Lab Manual 1OMSAINATH MPONLINE100% (1)
- FS Lab Mini Project Placement StatisticsDocument44 pagesFS Lab Mini Project Placement StatisticsTripti kumariPas encore d'évaluation
- Web Technology Lab ManualDocument33 pagesWeb Technology Lab ManualGeetha Parthiban100% (2)
- Case Study of Various Routing AlgorithmDocument25 pagesCase Study of Various Routing AlgorithmVijendra SolankiPas encore d'évaluation
- Practical-1 Aim: - Study and Usage of Openproj or Similar Software To Draft A Project Plan. IntroductionDocument39 pagesPractical-1 Aim: - Study and Usage of Openproj or Similar Software To Draft A Project Plan. IntroductionNikhil Chaubey100% (1)
- UML CLASS DIAGRAMS AND DOMAIN MODELSDocument96 pagesUML CLASS DIAGRAMS AND DOMAIN MODELSLAVANYA KARTHIKEYANPas encore d'évaluation
- IoT Access TechnologiesDocument15 pagesIoT Access TechnologiesashPas encore d'évaluation
- 2.OS Question Bank-2018 SvitDocument22 pages2.OS Question Bank-2018 SvitM.A raja100% (1)
- Operating System Lab - ManualDocument70 pagesOperating System Lab - ManualKumar ArikrishnanPas encore d'évaluation
- Data Mining-Constraint Based Cluster AnalysisDocument4 pagesData Mining-Constraint Based Cluster AnalysisRaj Endran100% (1)
- JNTU B.tech Computer Networks Lab Manual All ProgramsDocument53 pagesJNTU B.tech Computer Networks Lab Manual All ProgramsMaddali Sainadh100% (3)
- Gudlavalleru Engineering College Gudlavalleru Department of Computer Science and Engineering DBMS Lab Manual For Students II B.Tech II Sem R-10Document48 pagesGudlavalleru Engineering College Gudlavalleru Department of Computer Science and Engineering DBMS Lab Manual For Students II B.Tech II Sem R-10Akshay ChavanPas encore d'évaluation
- Unix File Attributes AND PermissionDocument13 pagesUnix File Attributes AND PermissionYashavanth TrPas encore d'évaluation
- Apache Cassandra ReportDocument20 pagesApache Cassandra ReportChaithu GowdruPas encore d'évaluation
- Viden Io SRM University Notes Fourth Semester Vacation Tracking SystemDocument20 pagesViden Io SRM University Notes Fourth Semester Vacation Tracking SystemJagannathan MjPas encore d'évaluation
- Deepthi Webclustering ReportDocument38 pagesDeepthi Webclustering ReportRijy Lorance100% (1)
- SRS Documentation For Railway Reservation SystemDocument29 pagesSRS Documentation For Railway Reservation SystemKanisha Angie100% (1)
- IV-cse DM Viva QuestionsDocument10 pagesIV-cse DM Viva QuestionsImtiyaz AliPas encore d'évaluation
- Tutorial On Network Simulator (NS2)Document24 pagesTutorial On Network Simulator (NS2)RakhmadhanyPrimanandaPas encore d'évaluation
- Dbms Lab Manual RGPVDocument38 pagesDbms Lab Manual RGPVcsedepartmentsistecr100% (3)
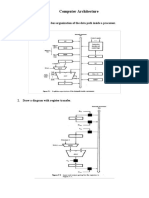
- Computer Architecture: 1. Draw A Diagram Single Bus Organization of The Data Path Inside A ProcessorDocument8 pagesComputer Architecture: 1. Draw A Diagram Single Bus Organization of The Data Path Inside A Processormd sayemPas encore d'évaluation
- AWT Viva PDFDocument11 pagesAWT Viva PDFtirgulPas encore d'évaluation
- Railway Ticket Reservation System Project ReportDocument9 pagesRailway Ticket Reservation System Project Reportb2uty77_593619754Pas encore d'évaluation
- OGSADocument164 pagesOGSAJagadeesanSrinivasanPas encore d'évaluation
- The Cocomo ModelDocument9 pagesThe Cocomo ModelSukhveer SangheraPas encore d'évaluation
- Database Models Explained in 40 CharactersDocument42 pagesDatabase Models Explained in 40 CharactersSoudipta Swar100% (1)
- DBMS Lab Manual GuideDocument40 pagesDBMS Lab Manual GuideKarthikeyan Ramajayam80% (10)
- 06 - Physical Design in Data WarehouseDocument18 pages06 - Physical Design in Data WarehouseMase LikuPas encore d'évaluation
- CH1 Data Warehouse DesignDocument33 pagesCH1 Data Warehouse Designriazahmad82100% (1)
- Data Warehouse - FinalDocument28 pagesData Warehouse - Finallatikaverma93Pas encore d'évaluation
- Designing The Data Warehouse Aima Second LectureDocument34 pagesDesigning The Data Warehouse Aima Second LecturedineshgomberPas encore d'évaluation
- Class Chapter 14Document25 pagesClass Chapter 14api-3805837Pas encore d'évaluation
- Data Warehousing: Engr. Madeha Mushtaq Department of Computer Science Iqra National UniversityDocument31 pagesData Warehousing: Engr. Madeha Mushtaq Department of Computer Science Iqra National UniversityNusrat UllahPas encore d'évaluation
- INFORMATION MANAGEMENT Unit 3 NEWDocument61 pagesINFORMATION MANAGEMENT Unit 3 NEWThirumal Azhagan100% (1)
- Advantages of ObjectDocument11 pagesAdvantages of ObjectAman KukarPas encore d'évaluation
- What is a Data Warehouse? - The Complete GuideDocument48 pagesWhat is a Data Warehouse? - The Complete GuideKishori PatilPas encore d'évaluation
- Unit-4 Relational Database and Big DataDocument22 pagesUnit-4 Relational Database and Big DataPurnachary CharyPas encore d'évaluation
- Theories of Onset of LabourDocument36 pagesTheories of Onset of LabourmitnexusPas encore d'évaluation
- Online Photography Management System 1Document4 pagesOnline Photography Management System 1kamalshrish100% (1)
- Dsa Ques Jan 2019Document1 pageDsa Ques Jan 2019kamalshrishPas encore d'évaluation
- Unit 8Document7 pagesUnit 8kamalshrishPas encore d'évaluation
- Data ScienceDocument1 pageData SciencekamalshrishPas encore d'évaluation
- Assignment Stat IDocument1 pageAssignment Stat IkamalshrishPas encore d'évaluation
- Neural SyllabusDocument1 pageNeural SyllabuskamalshrishPas encore d'évaluation
- Draft ICTEd 476-AI EducationDocument4 pagesDraft ICTEd 476-AI EducationkamalshrishPas encore d'évaluation
- Indian RailwaysDocument1 pageIndian RailwayskamalshrishPas encore d'évaluation
- Himanshi HomeworkDocument23 pagesHimanshi HomeworkkamalshrishPas encore d'évaluation
- B.SC .CSIT Revised SyllabusDocument57 pagesB.SC .CSIT Revised SyllabuskamalshrishPas encore d'évaluation
- Unit Five What Is KDD?Document3 pagesUnit Five What Is KDD?kamalshrishPas encore d'évaluation
- B.SC .CSIT Revised SyllabusDocument57 pagesB.SC .CSIT Revised SyllabuskamalshrishPas encore d'évaluation
- Section A Attempt Any Two Questions: (2×10 20)Document1 pageSection A Attempt Any Two Questions: (2×10 20)kamalshrishPas encore d'évaluation
- Sad - Data Modeling - Data Modeling - WattpadDocument11 pagesSad - Data Modeling - Data Modeling - WattpadkamalshrishPas encore d'évaluation
- Unit 5 StandardsDocument1 pageUnit 5 StandardskamalshrishPas encore d'évaluation
- InternshipDocument3 pagesInternshipArun LamichhanePas encore d'évaluation
- Database AdministrationDocument4 pagesDatabase AdministrationkamalshrishPas encore d'évaluation
- Kamal 6th Sem Web 2074Document2 pagesKamal 6th Sem Web 2074kamalshrishPas encore d'évaluation
- Cognos Security Overview1Document11 pagesCognos Security Overview1kamalshrishPas encore d'évaluation
- Exam InsertDocument1 pageExam InsertkamalshrishPas encore d'évaluation
- Introduction:-: Database Security Database Management System - 2Document9 pagesIntroduction:-: Database Security Database Management System - 2kamalshrishPas encore d'évaluation
- Approval SheetDocument1 pageApproval SheetkamalshrishPas encore d'évaluation
- BEd - Ict Nepali 2ndDocument14 pagesBEd - Ict Nepali 2ndkamalshrishPas encore d'évaluation
- 2074 DAA 5th SemDocument1 page2074 DAA 5th SemkamalshrishPas encore d'évaluation
- Unit 4 New Database ApplicationDocument1 pageUnit 4 New Database ApplicationkamalshrishPas encore d'évaluation
- Kamal 8th Sem Mining 2074Document1 pageKamal 8th Sem Mining 2074kamalshrishPas encore d'évaluation
- Unit 2 EER ModelDocument1 pageUnit 2 EER ModelkamalshrishPas encore d'évaluation
- Unit 3 Emerging DatabaseDocument1 pageUnit 3 Emerging DatabasekamalshrishPas encore d'évaluation
- Java Programming With Oracle Database 19cDocument19 pagesJava Programming With Oracle Database 19cakbezawadaPas encore d'évaluation
- Computer Science Paper 2 SL MarkschemeDocument17 pagesComputer Science Paper 2 SL Markschemepraveena.kiranPas encore d'évaluation
- Realtional Model - Relational AlgebraDocument67 pagesRealtional Model - Relational AlgebraneetunarwalPas encore d'évaluation
- Sakhr - Chaib - Paper On Data MiningDocument3 pagesSakhr - Chaib - Paper On Data MiningChaieb SakherPas encore d'évaluation
- Iii TrialDocument10 pagesIii TrialisattsatduvpssuttsPas encore d'évaluation
- SQL Server Cheat Sheet: by ViaDocument1 pageSQL Server Cheat Sheet: by ViaSri BalajiPas encore d'évaluation
- Apex Code Best Practices - Apex HoursDocument16 pagesApex Code Best Practices - Apex HoursPradyumna P100% (1)
- Reference For Super LabDocument52 pagesReference For Super Labmairamiho1999Pas encore d'évaluation
- Root Password and Log Into The SystemDocument4 pagesRoot Password and Log Into The SystemNasir KamalPas encore d'évaluation
- Build Analytics Apps with Embedded VisualizationsDocument1 pageBuild Analytics Apps with Embedded VisualizationsAkrama HussainPas encore d'évaluation
- Database Fundamentals in MS AccessDocument3 pagesDatabase Fundamentals in MS AccessCherry G. QuibuyenPas encore d'évaluation
- Cassandra Brass Tacks Q&ADocument4 pagesCassandra Brass Tacks Q&AVenkatesh BabuPas encore d'évaluation
- Geo Distance Search With MySQLDocument29 pagesGeo Distance Search With MySQLOleksiy Kovyrin94% (87)
- Lecture6 DBMSDocument10 pagesLecture6 DBMSsamlakshiaPas encore d'évaluation
- MASTER OF BUSINESS ADMINISTRATION I YEAR COMPUTER APPLICATION FOR BUSINESS LAB RECORD SQL AND PL/SQL EXPERIMENTSDocument21 pagesMASTER OF BUSINESS ADMINISTRATION I YEAR COMPUTER APPLICATION FOR BUSINESS LAB RECORD SQL AND PL/SQL EXPERIMENTSSrinivas Kulkarni100% (1)
- Applies To:: How To Configure ODI Studio With External Authentication (Doc ID 1510392.1)Document8 pagesApplies To:: How To Configure ODI Studio With External Authentication (Doc ID 1510392.1)nareshreddyguntakaPas encore d'évaluation
- Menu Design, Screen Design, Performance Analysis, and Process Modeling from Data ModelsDocument28 pagesMenu Design, Screen Design, Performance Analysis, and Process Modeling from Data ModelsHaroon ExamPas encore d'évaluation
- Udemy Documentation 4Document2 pagesUdemy Documentation 4Roberto Mellino LadresPas encore d'évaluation
- Microsoft Official Course: Implementing Active Directory Domain Services Sites and ReplicationDocument31 pagesMicrosoft Official Course: Implementing Active Directory Domain Services Sites and ReplicationRafael ReyesPas encore d'évaluation
- Sample 1Document20 pagesSample 1davPas encore d'évaluation
- INFA Scenario Based Q N A - 16 PagesDocument16 pagesINFA Scenario Based Q N A - 16 Pageskumar.sena4633Pas encore d'évaluation
- Roadmap To Define A Backup Strategy For Sap Applications: by Prakash PalaniDocument11 pagesRoadmap To Define A Backup Strategy For Sap Applications: by Prakash PalaniCésar GarciaPas encore d'évaluation
- What Is SQL?: Below Is An Example of A Table Called "Persons"Document31 pagesWhat Is SQL?: Below Is An Example of A Table Called "Persons"Niraj Hande0% (1)
- Dbms Schemas:: Internal, Conceptual, ExternalDocument11 pagesDbms Schemas:: Internal, Conceptual, ExternalEichhorst AutomobilesPas encore d'évaluation
- Sqlmap Automated SQL Injection ToolDocument6 pagesSqlmap Automated SQL Injection ToolSaddam RanjhaniPas encore d'évaluation
- Data Delivery Alternative 3Document12 pagesData Delivery Alternative 3syed hamza100% (2)
- DWDM UNIT-1 DATA WAREHOUSING 100% THEORYDocument25 pagesDWDM UNIT-1 DATA WAREHOUSING 100% THEORYGiriDharanPas encore d'évaluation
- Database Final AssignmentDocument8 pagesDatabase Final AssignmentCaijunn TanPas encore d'évaluation
- Amazon Web Services (Aws)Document13 pagesAmazon Web Services (Aws)shanmathi100% (1)
- LogDocument60 pagesLogSanderi PPas encore d'évaluation