Vous aimerez peut-être aussi
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryD'EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryÉvaluation : 3.5 sur 5 étoiles3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)D'EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Évaluation : 4.5 sur 5 étoiles4.5/5 (120)
- Grit: The Power of Passion and PerseveranceD'EverandGrit: The Power of Passion and PerseveranceÉvaluation : 4 sur 5 étoiles4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaD'EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaÉvaluation : 4.5 sur 5 étoiles4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingD'EverandThe Little Book of Hygge: Danish Secrets to Happy LivingÉvaluation : 3.5 sur 5 étoiles3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItD'EverandNever Split the Difference: Negotiating As If Your Life Depended On ItÉvaluation : 4.5 sur 5 étoiles4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeD'EverandShoe Dog: A Memoir by the Creator of NikeÉvaluation : 4.5 sur 5 étoiles4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerD'EverandThe Emperor of All Maladies: A Biography of CancerÉvaluation : 4.5 sur 5 étoiles4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeD'EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeÉvaluation : 4 sur 5 étoiles4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyD'EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyÉvaluation : 3.5 sur 5 étoiles3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersD'EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersÉvaluation : 4.5 sur 5 étoiles4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnD'EverandTeam of Rivals: The Political Genius of Abraham LincolnÉvaluation : 4.5 sur 5 étoiles4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreD'EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreÉvaluation : 4 sur 5 étoiles4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceD'EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceÉvaluation : 4 sur 5 étoiles4/5 (895)
- Her Body and Other Parties: StoriesD'EverandHer Body and Other Parties: StoriesÉvaluation : 4 sur 5 étoiles4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureD'EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureÉvaluation : 4.5 sur 5 étoiles4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaD'EverandThe Unwinding: An Inner History of the New AmericaÉvaluation : 4 sur 5 étoiles4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)D'EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Évaluation : 4 sur 5 étoiles4/5 (98)
- On Fire: The (Burning) Case for a Green New DealD'EverandOn Fire: The (Burning) Case for a Green New DealÉvaluation : 4 sur 5 étoiles4/5 (73)
- Discrete-Time Digital Signal Processing - Oppenheim, Schafer & Buck PDFDocument895 pagesDiscrete-Time Digital Signal Processing - Oppenheim, Schafer & Buck PDFKishanPas encore d'évaluation
- Integrated XML Gateway Implementation GuideDocument142 pagesIntegrated XML Gateway Implementation GuideManu K BhagavathPas encore d'évaluation
- Labour Regulations 101Document27 pagesLabour Regulations 101kanishkPas encore d'évaluation
- Module 1 Digital MarketingDocument16 pagesModule 1 Digital MarketingkanishkPas encore d'évaluation
- Deco401 Microeconomic Theory English PDFDocument428 pagesDeco401 Microeconomic Theory English PDFkanishkPas encore d'évaluation
- Statement For A/c XXXXXXXXX5471 For The Period 26-Mar-2023 To 04-Apr-2023Document13 pagesStatement For A/c XXXXXXXXX5471 For The Period 26-Mar-2023 To 04-Apr-2023Jadhav PawanPas encore d'évaluation
- Leadership TheoriesDocument4 pagesLeadership Theorieskanishk100% (1)
- Yamini HR Generalist ResumeDocument2 pagesYamini HR Generalist ResumeGangadhar BiradarPas encore d'évaluation
- Major Biomes of The WorldDocument13 pagesMajor Biomes of The Worldk ARYAPas encore d'évaluation
- Gs Prelims 5 Years Modern History Analysis Questions and AnswersDocument10 pagesGs Prelims 5 Years Modern History Analysis Questions and AnswersamrendrasinghgPas encore d'évaluation
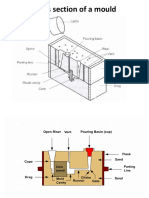
- Cross Section of A MouldDocument54 pagesCross Section of A MouldkanishkPas encore d'évaluation
- Made Easy Dheeraj Sir: Reasoning & Aptitude Classroom HandoutDocument23 pagesMade Easy Dheeraj Sir: Reasoning & Aptitude Classroom HandoutsalmanPas encore d'évaluation
- Maps - Art and CultureDocument10 pagesMaps - Art and CultureShivani ManePas encore d'évaluation
- Gs Prelims 5 Years Modern HistoryDocument130 pagesGs Prelims 5 Years Modern HistorykanishkPas encore d'évaluation
- Polity Sample NotesDocument9 pagesPolity Sample NoteskanishkPas encore d'évaluation
- Ancient History TimelineDocument1 pageAncient History Timelinetinaantony100% (1)
- S&T Sample NotesDocument9 pagesS&T Sample NoteskanishkPas encore d'évaluation
- Ancient History TimelineDocument1 pageAncient History Timelinetinaantony100% (1)
- Ethics Sample Notes - Shreyans KumatDocument14 pagesEthics Sample Notes - Shreyans KumatAmritpal Bhagat0% (1)
- January 2019: Monthly Current AffairsDocument39 pagesJanuary 2019: Monthly Current AffairsysantoshPas encore d'évaluation
- Economy Sample NotesDocument13 pagesEconomy Sample NotesTina AntonyPas encore d'évaluation
- Shreyans Kumat (Air 4) - T.Me/Shreyansupsc: Scanned by CamscannerDocument8 pagesShreyans Kumat (Air 4) - T.Me/Shreyansupsc: Scanned by CamscannerMINATO NAMIKAZEPas encore d'évaluation
- Indifference Curve Analysis Concept Assumptions and PropertiesDocument6 pagesIndifference Curve Analysis Concept Assumptions and PropertieskanishkPas encore d'évaluation
- Toppers Notes For UPSDocument10 pagesToppers Notes For UPSnirmalaPas encore d'évaluation
- 5 6215465066322460765Document5 pages5 6215465066322460765Edwin MartinPas encore d'évaluation
- MBA2ndYearSyllabus (Effective From 2017 - 18) PDFDocument72 pagesMBA2ndYearSyllabus (Effective From 2017 - 18) PDFKomal Khandelwal DasPas encore d'évaluation
- Cut-Off Scores of Shortlisted Candidates For ONGC GT Recruitment Interviews Based On UGC - NET-July 2018 Score Against Advt. No. 1/2018 (R&P)Document1 pageCut-Off Scores of Shortlisted Candidates For ONGC GT Recruitment Interviews Based On UGC - NET-July 2018 Score Against Advt. No. 1/2018 (R&P)kanishkPas encore d'évaluation
- Committee Reports and StatisticsDocument1 pageCommittee Reports and StatisticsAmbrish MishraPas encore d'évaluation
- Difference Between Leader and ManagerDocument3 pagesDifference Between Leader and ManagerkanishkPas encore d'évaluation
- Vegetation of IndiaDocument7 pagesVegetation of IndiakanishkPas encore d'évaluation
- BANKING BOLT - Static Banking GK PDFDocument58 pagesBANKING BOLT - Static Banking GK PDFSamuel BeckettPas encore d'évaluation
- BonusDocument2 pagesBonusabcd1124Pas encore d'évaluation
- Waygo: Advanced Location Device and AppDocument11 pagesWaygo: Advanced Location Device and AppkanishkPas encore d'évaluation
- 1000+ Education, Police & Anti Corruption Jobs Through SPSCDocument12 pages1000+ Education, Police & Anti Corruption Jobs Through SPSCZahid AliPas encore d'évaluation
- CH 1Document24 pagesCH 1Chew Ting LiangPas encore d'évaluation
- 2024 AI Set-4Document11 pages2024 AI Set-4TanishPas encore d'évaluation
- Alienware 17 R4 Service Manual: Computer Model: Alienware 17 R4 Regulatory Model: P31E Regulatory Type: P31E001Document133 pagesAlienware 17 R4 Service Manual: Computer Model: Alienware 17 R4 Regulatory Model: P31E Regulatory Type: P31E001Diki Fernando SaputraPas encore d'évaluation
- Proservo NMS53x Series: Operating ManualDocument116 pagesProservo NMS53x Series: Operating Manualjohnf2328Pas encore d'évaluation
- The Evolution of Project ManagementDocument5 pagesThe Evolution of Project Managementcrib85Pas encore d'évaluation
- BRO ASD535-532-531 en PDFDocument6 pagesBRO ASD535-532-531 en PDFArman Ul NasarPas encore d'évaluation
- Introduction To VLSI Design EEE 416: Dr. Mohammad Al HakimDocument23 pagesIntroduction To VLSI Design EEE 416: Dr. Mohammad Al HakimMizanur Rahman SujanPas encore d'évaluation
- EXP-LG-048822 Lighting Management - Wall mounting-DT-360°-for 93 M Areas - Flush MountingDocument1 pageEXP-LG-048822 Lighting Management - Wall mounting-DT-360°-for 93 M Areas - Flush MountingPercy GoitsemangPas encore d'évaluation
- Arturo B. Del Ayre's Curriculum Vitae & ResumeDocument14 pagesArturo B. Del Ayre's Curriculum Vitae & ResumeArturo Brondial del Ayre100% (6)
- Visual Foxpro ErrorsDocument18 pagesVisual Foxpro ErrorsLucianGhPas encore d'évaluation
- Ring and Johnson CounterDocument5 pagesRing and Johnson CounterkrsekarPas encore d'évaluation
- Assignment 3Document5 pagesAssignment 3RosaPas encore d'évaluation
- Arduino Uno Rev3 02 TH - SCHDocument1 pageArduino Uno Rev3 02 TH - SCHMatija Buden100% (1)
- Aim-To Provide A Project Plan of Online Boookstore System ObjectiveDocument3 pagesAim-To Provide A Project Plan of Online Boookstore System Objectiveamal sureshPas encore d'évaluation
- Development of Value Stream Mapping From L'Oreal's Artwork Process PDFDocument25 pagesDevelopment of Value Stream Mapping From L'Oreal's Artwork Process PDFReuben AzavedoPas encore d'évaluation
- Unit Test 2: Answer All Thirty Questions. There Is One Mark Per QuestionDocument3 pagesUnit Test 2: Answer All Thirty Questions. There Is One Mark Per QuestionNguyên Nguyễn75% (4)
- Sinfar, Surveying AssignmentDocument81 pagesSinfar, Surveying Assignmentmuhammathusinfar01Pas encore d'évaluation
- Evidence CasesDocument79 pagesEvidence Caseszyphora grace trillanesPas encore d'évaluation
- Electronics and Communication Engineering: Projectbased Lab Report OnDocument21 pagesElectronics and Communication Engineering: Projectbased Lab Report OnGowtham RoxtaPas encore d'évaluation
- Bundle PatchDocument4 pagesBundle PatchnizamPas encore d'évaluation
- The Information Schema - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsDocument12 pagesThe Information Schema - MySQL 8 Query Performance Tuning - A Systematic Method For Improving Execution SpeedsChandra Sekhar DPas encore d'évaluation
- CL 60 SM 005 User Manual En)Document24 pagesCL 60 SM 005 User Manual En)NoahPas encore d'évaluation
- Salesforce Industries Communications Cloud DatasheetDocument2 pagesSalesforce Industries Communications Cloud DatasheetCharLy HuynhPas encore d'évaluation
- Companion WebsiteDocument110 pagesCompanion WebsiteDren FazliuPas encore d'évaluation
- LG 42LK450 (SM) PDFDocument72 pagesLG 42LK450 (SM) PDFSandroCezardeAraujoPas encore d'évaluation