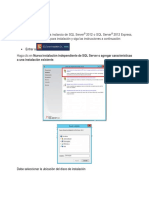
Vous aimerez peut-être aussi
- Taller WORDDocument3 pagesTaller WORDJuan Guillermo Forero NemePas encore d'évaluation
- DiagramasDocument5 pagesDiagramasJuan Guillermo Forero NemePas encore d'évaluation
- RESUMENDocument1 pageRESUMENJuan Guillermo Forero NemePas encore d'évaluation
- Creación de Usuario en TRELLODocument7 pagesCreación de Usuario en TRELLOJuan Guillermo Forero NemePas encore d'évaluation
- Presentacion de Decision de DividendosDocument11 pagesPresentacion de Decision de DividendosJuan Guillermo Forero NemePas encore d'évaluation
- Administracion FinancieraDocument43 pagesAdministracion FinancieraJuan Guillermo Forero NemePas encore d'évaluation
- Evidencia Mapa mental respecto a los planes y acciones establecidos en medio ambiente y SST GA6-220601501-AA3-EV01Document2 pagesEvidencia Mapa mental respecto a los planes y acciones establecidos en medio ambiente y SST GA6-220601501-AA3-EV01Juan Guillermo Forero NemePas encore d'évaluation
- Evidencia Bitácora de trabajo de producción gráfica GA3-220501083-AA1-EV02Document23 pagesEvidencia Bitácora de trabajo de producción gráfica GA3-220501083-AA1-EV02Juan Guillermo Forero NemePas encore d'évaluation
- GA2-250201022-AA2-EV01Document17 pagesGA2-250201022-AA2-EV01Juan Guillermo Forero NemePas encore d'évaluation
- Reglas OrtograficaslorenaDocument9 pagesReglas OrtograficaslorenaJuan Guillermo Forero NemePas encore d'évaluation
- Ficha antropométrica de valoración de la condición física. GA5 230101507 AA3EV01Document2 pagesFicha antropométrica de valoración de la condición física. GA5 230101507 AA3EV01Juan Guillermo Forero NemePas encore d'évaluation
- Politica Monetaria en ColombiaDocument66 pagesPolitica Monetaria en ColombiaJuan Guillermo Forero NemePas encore d'évaluation
- Evidencia Mapa mental respecto a los planes y acciones establecidos en medio ambiente y SST GA6-220601501-AA3-EV01Document2 pagesEvidencia Mapa mental respecto a los planes y acciones establecidos en medio ambiente y SST GA6-220601501-AA3-EV01Juan Guillermo Forero NemePas encore d'évaluation
- PLANTILLADocument1 pagePLANTILLAJuan Guillermo Forero NemePas encore d'évaluation
- Dash-Modelos (1) .IpynbDocument946 pagesDash-Modelos (1) .IpynbJuan Guillermo Forero NemePas encore d'évaluation
- Insert Data BDDocument28 pagesInsert Data BDJuan Guillermo Forero NemePas encore d'évaluation
- Cardboard Bear Oso CartonDocument2 pagesCardboard Bear Oso CartonJuan Guillermo Forero Neme100% (1)
- Mat FraDocument2 pagesMat FraJuan Guillermo Forero NemePas encore d'évaluation
- Tutotial Activacion Cuenta Correo InsDocument5 pagesTutotial Activacion Cuenta Correo InsJuan Guillermo Forero NemePas encore d'évaluation
- Trabajo SistemasDocument1 pageTrabajo SistemasJuan Guillermo Forero NemePas encore d'évaluation
- Fundamentos de Base de Datos MTA 98-364Document160 pagesFundamentos de Base de Datos MTA 98-364escorpionrojo43100% (4)
- Actividad AA8-1 Conceptualizar Sobre Los Niveles de Servicio y Gestión de IncidentesDocument12 pagesActividad AA8-1 Conceptualizar Sobre Los Niveles de Servicio y Gestión de IncidentesJuan Guillermo Forero NemePas encore d'évaluation
- Actividad Aa11Document11 pagesActividad Aa11Juan Guillermo Forero NemePas encore d'évaluation
- Oferta Unicorporativa2019 II DefDocument18 pagesOferta Unicorporativa2019 II DefJuan Guillermo Forero NemePas encore d'évaluation
- Balanza de PagosDocument23 pagesBalanza de PagosJuan Guillermo Forero NemePas encore d'évaluation
- Conceptualizando El Entorno de Los Sistemas y de Los Sistemas de GestionDocument8 pagesConceptualizando El Entorno de Los Sistemas y de Los Sistemas de GestionJuan Guillermo Forero Neme100% (2)
- Crear Instancia NuevaDocument11 pagesCrear Instancia NuevaJuan Guillermo Forero NemePas encore d'évaluation
- CamaroteDocument1 pageCamaroteJuan Guillermo Forero NemePas encore d'évaluation
- FundamentosDocument12 pagesFundamentosJuan Guillermo Forero NemePas encore d'évaluation
- CamaroteDocument1 pageCamaroteJuan Guillermo Forero NemePas encore d'évaluation
- Presentación de Resultados Empresa BetaDocument10 pagesPresentación de Resultados Empresa BetaJesus MillanPas encore d'évaluation
- Plan Marketing 2 FundamentosDocument7 pagesPlan Marketing 2 FundamentosProductos Herbalife Distribuidor IndependientePas encore d'évaluation
- Informe Final. Industrial FerwelDocument36 pagesInforme Final. Industrial FerwelJorge David Castro Cordoba 1104Pas encore d'évaluation
- Cantidades de Hortalizas Juarez-LuciaDocument104 pagesCantidades de Hortalizas Juarez-LuciaduberPas encore d'évaluation
- FUNDAMENTOS DE MERCADEO Caso Practico 2Document4 pagesFUNDAMENTOS DE MERCADEO Caso Practico 2danielPas encore d'évaluation
- TAREA 2 - Importancia de La Etica y Responsabilidad Social en Las Empresarial - 112005 - 1Document12 pagesTAREA 2 - Importancia de La Etica y Responsabilidad Social en Las Empresarial - 112005 - 1ANGELA RAMIREZ MEJIAPas encore d'évaluation
- Trabajo Final Sistema de Informacion GerencialDocument33 pagesTrabajo Final Sistema de Informacion GerencialKeren RaideirisPas encore d'évaluation
- Inv y Describa y Defina Que Tipo de Presupuestos ExistenDocument4 pagesInv y Describa y Defina Que Tipo de Presupuestos ExistenSalma Andrea Sainz PrietoPas encore d'évaluation
- Anteproyecto Comercializadora Productos Salsamentaria MDocument23 pagesAnteproyecto Comercializadora Productos Salsamentaria MGermánAlonsoMuñozPas encore d'évaluation
- 09 OligopolioDocument41 pages09 OligopolioyamilePas encore d'évaluation
- Trabajo Final de Estructuración de Negocios GlobalesDocument10 pagesTrabajo Final de Estructuración de Negocios GlobalesD'alessandro Consuelo monteroPas encore d'évaluation
- Enfermeria ExpressDocument41 pagesEnfermeria ExpressNoemi PastranaPas encore d'évaluation
- Investigar Sobre Plaza y Promoción Como Elementos de La MezclaDocument4 pagesInvestigar Sobre Plaza y Promoción Como Elementos de La Mezclanatascha labastidasPas encore d'évaluation
- Historia de la publicidadDocument16 pagesHistoria de la publicidadANTHONY CAMILO ARDILA BELTRANPas encore d'évaluation
- Trabajo de Administracion UladechDocument16 pagesTrabajo de Administracion UladechHelem Mejia83% (6)
- Fundamentos de mercados UDESDocument4 pagesFundamentos de mercados UDESAJ SotoPas encore d'évaluation
- Guevara Luque Alo DigDocument32 pagesGuevara Luque Alo DigMachPas encore d'évaluation
- Balance - Scorecard - EjemplosDocument5 pagesBalance - Scorecard - EjemplosHuber McaPas encore d'évaluation
- Trabajo de - MercadotecniaDocument25 pagesTrabajo de - MercadotecniaXavier PolancoPas encore d'évaluation
- U4-Contabilidad Amaya - Revenue ManagementDocument4 pagesU4-Contabilidad Amaya - Revenue ManagementcarlosPas encore d'évaluation
- Articulo de Fidelizacion FinalDocument9 pagesArticulo de Fidelizacion FinalSaraPas encore d'évaluation
- VinvulaciónDocument18 pagesVinvulacióncl.luis04Pas encore d'évaluation
- Foda Grupo AdolfoDocument11 pagesFoda Grupo AdolfoCieloLoboPas encore d'évaluation
- Endomarketing Marketing Hacia DentroDocument23 pagesEndomarketing Marketing Hacia DentroIsabella Linares0% (1)
- Implementacion Del Programa de VentasDocument39 pagesImplementacion Del Programa de VentasDina IrisPas encore d'évaluation
- Taller Elasticidad Precio de La DemandaDocument4 pagesTaller Elasticidad Precio de La DemandaNatalia MessinoPas encore d'évaluation
- Eje 3 Gerencia de MercadeoDocument8 pagesEje 3 Gerencia de MercadeoCarlos Olaya TrianaPas encore d'évaluation
- Recibo y Despacho de ObjetosDocument38 pagesRecibo y Despacho de Objetospespe4073% (11)
- Tarea 2-InternacionalizacionDocument12 pagesTarea 2-InternacionalizacionMarco CapristanPas encore d'évaluation
- Trabajo FinalDocument17 pagesTrabajo FinalJhael Cristina Jiménez AchocallaPas encore d'évaluation