Vous aimerez peut-être aussi
- Ebook Piano Guide CompressedDocument148 pagesEbook Piano Guide CompressedAlexPas encore d'évaluation
- Rapport Scores TAGE MAGE 2021 S2Document26 pagesRapport Scores TAGE MAGE 2021 S2Aziz AidaraPas encore d'évaluation
- Ellipses NSI Terminale 2edDocument210 pagesEllipses NSI Terminale 2edRhodia100% (2)
- Dimensionnement Des Installations Électriques Relatives Aux Courants Forts de L'agence BDM-SADocument52 pagesDimensionnement Des Installations Électriques Relatives Aux Courants Forts de L'agence BDM-SAetimex maliPas encore d'évaluation
- 01 Structure CristallineDocument24 pages01 Structure CristallineMariam Rosa100% (4)
- Formulaires Fonctions Usuelles, Dérivées, PrimitivesDocument3 pagesFormulaires Fonctions Usuelles, Dérivées, PrimitivesserialaminePas encore d'évaluation
- FDocument13 pagesFAziz AidaraPas encore d'évaluation
- TexteDocument1 pageTexteAziz AidaraPas encore d'évaluation
- Chap7 Statique Sans FrottementDocument20 pagesChap7 Statique Sans FrottementAziz AidaraPas encore d'évaluation
- ISEMath2017-Contraction de TextDocument3 pagesISEMath2017-Contraction de TextAziz AidaraPas encore d'évaluation
- Filière MP: 5 - Dates, Horaires Et Coefficients Des Épreuves Ecrites Du Ccinp Et Des Concours en Banque D'ÉpreuvesDocument1 pageFilière MP: 5 - Dates, Horaires Et Coefficients Des Épreuves Ecrites Du Ccinp Et Des Concours en Banque D'ÉpreuvesAziz AidaraPas encore d'évaluation
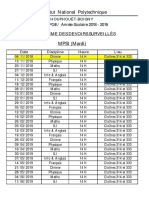
- Institut National Polytechnique: CPGE/ Année Scolaire 2018 - 2019 Programme Des Devoirs SurveillésDocument1 pageInstitut National Polytechnique: CPGE/ Année Scolaire 2018 - 2019 Programme Des Devoirs SurveillésAziz AidaraPas encore d'évaluation
- Thermodynamique-Chapitre 1-Description Macroscopique D'un Systeme Thermodynamique À L'equilibreDocument98 pagesThermodynamique-Chapitre 1-Description Macroscopique D'un Systeme Thermodynamique À L'equilibreAziz Aidara100% (1)
- Les Reactions ComplexesDocument9 pagesLes Reactions ComplexesAziz AidaraPas encore d'évaluation
- Calendrier Pedagogique 2018-2019 - v0Document1 pageCalendrier Pedagogique 2018-2019 - v0Aziz AidaraPas encore d'évaluation
- ISEMath2017-Contraction de TextDocument3 pagesISEMath2017-Contraction de TextAziz AidaraPas encore d'évaluation
- Filière MP: 5 - Dates, Horaires Et Coefficients Des Épreuves Ecrites Du Ccinp Et Des Concours en Banque D'ÉpreuvesDocument1 pageFilière MP: 5 - Dates, Horaires Et Coefficients Des Épreuves Ecrites Du Ccinp Et Des Concours en Banque D'ÉpreuvesAziz AidaraPas encore d'évaluation
- d00.frDocument20 pagesd00.frPeterPas encore d'évaluation
- Sujet Metropole-Bac-Pro-Melec-Juin-2022Document11 pagesSujet Metropole-Bac-Pro-Melec-Juin-2022petitprePas encore d'évaluation
- AFNILDocument2 pagesAFNILSMITHPas encore d'évaluation
- Serie D Exo 01 RDPDocument2 pagesSerie D Exo 01 RDPredwane100% (4)
- Compteur de Particules: Climet Ci-450TDocument1 pageCompteur de Particules: Climet Ci-450Timenegeo.hzPas encore d'évaluation
- TP3-Simulation PSK-QAM Winqsim CorrectionDocument16 pagesTP3-Simulation PSK-QAM Winqsim CorrectionJessi autisolPas encore d'évaluation
- TD3 BDD Ex1 2 3Document6 pagesTD3 BDD Ex1 2 3Gojo SatoruPas encore d'évaluation
- 766-Article Text-2068-1-10-202209Document12 pages766-Article Text-2068-1-10-202209LamssarbiPas encore d'évaluation
- L'intelligence Artificiele:: Processus D'imitation de L'intelligence Humaine Informatique Ordinateurs Êtres HumainsDocument4 pagesL'intelligence Artificiele:: Processus D'imitation de L'intelligence Humaine Informatique Ordinateurs Êtres HumainsmaryemPas encore d'évaluation
- Report Forum AFR Brazaville-FrDocument9 pagesReport Forum AFR Brazaville-FrMoussa Karim AlioPas encore d'évaluation
- Sfra 5000 - FRDocument4 pagesSfra 5000 - FRmohamed anasPas encore d'évaluation
- Procedure Controle Des Informations Documenteesdocx PDF FreeDocument10 pagesProcedure Controle Des Informations Documenteesdocx PDF FreeHermann A. TONHONPas encore d'évaluation
- Java FXfinalDocument22 pagesJava FXfinalarbogaste adzabaPas encore d'évaluation
- Logiciel: ÉtymologieDocument1 pageLogiciel: ÉtymologieAnthony APas encore d'évaluation
- Options CN Heidenhain A.SynoptimDocument70 pagesOptions CN Heidenhain A.SynoptimNcir TaherPas encore d'évaluation
- ISE3 - ISSEA - Traitement - Exploitation Des Données D'enquêtes 2021 - Pratique 03janvier21OKDocument54 pagesISE3 - ISSEA - Traitement - Exploitation Des Données D'enquêtes 2021 - Pratique 03janvier21OKChristine Yawa Agbotse100% (1)
- TP3 BDII SolDocument6 pagesTP3 BDII SolSOUHAIL YOUSFIPas encore d'évaluation
- Guide de Communication: en Contexte Humanitaire Et de Consolidation de La PaixDocument44 pagesGuide de Communication: en Contexte Humanitaire Et de Consolidation de La PaixamouPas encore d'évaluation
- Copie de Vol MJC - ConstatsDocument2 pagesCopie de Vol MJC - Constats2w4gmgrdnfPas encore d'évaluation
- Audit SEO 2021 2022 CathoDocument20 pagesAudit SEO 2021 2022 CathoSkndrPas encore d'évaluation
- Chapitre 1 Classification Des Circuits IntégrésDocument29 pagesChapitre 1 Classification Des Circuits IntégrésHichem GuedriPas encore d'évaluation
- Corrige IMN 01.1Document14 pagesCorrige IMN 01.1Nowe AhmadePas encore d'évaluation
- Chap IV PPTP - Toolkit Graphique - Java Swing - Composants AtomiquesDocument29 pagesChap IV PPTP - Toolkit Graphique - Java Swing - Composants AtomiquesMohamed SelmaniPas encore d'évaluation
- Introduction A Matlab Et SimulinkDocument71 pagesIntroduction A Matlab Et Simulinkouasti moroPas encore d'évaluation
- Canevas 2020 Equipement InfoDocument1 pageCanevas 2020 Equipement InfoZaza TurbinePas encore d'évaluation
- Série de TD 2Document1 pageSérie de TD 2Laasri YounesPas encore d'évaluation
- User Manual Silvercrest IAN 339464 10530B - Programmateur Prise ÉlectriqueDocument104 pagesUser Manual Silvercrest IAN 339464 10530B - Programmateur Prise Électriquearnaud.montegutPas encore d'évaluation