Vous aimerez peut-être aussi
- Examen Avec Corrige Du 1er Semestre Linux 2023Document2 pagesExamen Avec Corrige Du 1er Semestre Linux 2023imad100% (2)
- Administration Reseau LinuxDocument59 pagesAdministration Reseau Linuxgibou19203100% (1)
- Some Linux CommandDocument51 pagesSome Linux CommandChaimae Salsabil00100% (1)
- Les Reseaux Sans FilsDocument71 pagesLes Reseaux Sans Filsniko94% (17)
- Commandes de Base LinuxDocument6 pagesCommandes de Base Linuxyassine728100% (5)
- Chapitre 1 & 2 Contrôle Interne & AuditDocument96 pagesChapitre 1 & 2 Contrôle Interne & Auditmonouche020% (1)
- Présentation Assistée Par OrdinateurDocument9 pagesPrésentation Assistée Par OrdinateurAmine DevPas encore d'évaluation
- TP LinuxDocument24 pagesTP LinuxAchrafPas encore d'évaluation
- Exposé Les Commandes Reseaux Sous UnixDocument6 pagesExposé Les Commandes Reseaux Sous UnixBlaise Jonathan VessahPas encore d'évaluation
- Exo 1 Avec CommandeDocument36 pagesExo 1 Avec CommandeKevin Bocko MichelPas encore d'évaluation
- Commande LinuxDocument10 pagesCommande LinuxBen ali SowPas encore d'évaluation
- Commandes LinuxDocument3 pagesCommandes Linuxbahaj zouhairPas encore d'évaluation
- TD TP OS-LinuxDocument10 pagesTD TP OS-LinuxNael Le BayonPas encore d'évaluation
- QCM Linux PARTIE 3Document3 pagesQCM Linux PARTIE 3AwonoPas encore d'évaluation
- TD 1 ReponseDocument4 pagesTD 1 Reponseghaitan00Pas encore d'évaluation
- Tp1 Tp2 Se Maryam Laqlii Sic A1Document33 pagesTp1 Tp2 Se Maryam Laqlii Sic A1Maryam LaqliiPas encore d'évaluation
- Rapport TP SeDocument7 pagesRapport TP SemalikouallaPas encore d'évaluation
- Module M3206 2020-2021 Automatisation Des T Aches D'administrationDocument45 pagesModule M3206 2020-2021 Automatisation Des T Aches D'administrationGeorges Le Mignon OlePas encore d'évaluation
- SSH + SFTPDocument13 pagesSSH + SFTPAlin TrancaPas encore d'évaluation
- Administration GNU - Linux en Ligne de Commandes PDFDocument6 pagesAdministration GNU - Linux en Ligne de Commandes PDFCédric LevenPas encore d'évaluation
- Lpi UnixDocument34 pagesLpi Unixsyriack mboliPas encore d'évaluation
- CommandelinuxDocument44 pagesCommandelinuxhelinandrianina SahazaPas encore d'évaluation
- Some Linux CommandDocument30 pagesSome Linux CommandDOUAA BEJOUPas encore d'évaluation
- TP1 SE - Initiation À LinuxDocument12 pagesTP1 SE - Initiation À Linuxq6bzx7b7t4Pas encore d'évaluation
- Commandes LinuxDocument9 pagesCommandes LinuxziedkPas encore d'évaluation
- Les 40 Commandes Linux de Base Les Plus Populaires Que Vous Devez ConnaitreDocument19 pagesLes 40 Commandes Linux de Base Les Plus Populaires Que Vous Devez ConnaitreJulien CKPas encore d'évaluation
- Lignes de Commande LinuxDocument39 pagesLignes de Commande LinuxJulien DupuisPas encore d'évaluation
- Adminustration Reseaux Sous GNU LinuxDocument105 pagesAdminustration Reseaux Sous GNU LinuxAristote EngudiPas encore d'évaluation
- Cours CommandesSELinuxDocument16 pagesCours CommandesSELinuxEssozimna LibilulePas encore d'évaluation
- CORRECTION EP COURS DU SOIR - Securisation LinuxDocument3 pagesCORRECTION EP COURS DU SOIR - Securisation LinuxArafat MohamedPas encore d'évaluation
- DevoirDocument4 pagesDevoirmma siPas encore d'évaluation
- Module 2Document7 pagesModule 2Dandiégou KOMBATEPas encore d'évaluation
- QstTECH (1)Document20 pagesQstTECH (1)Ayoub TouijerPas encore d'évaluation
- Linux Et Infrastructures 17 01 2022Document10 pagesLinux Et Infrastructures 17 01 2022Claude DongmoPas encore d'évaluation
- Redondance 2Document8 pagesRedondance 2yaya konatePas encore d'évaluation
- Resumer Colle TPDocument4 pagesResumer Colle TPrizlane korichiPas encore d'évaluation
- 03-Terminaux Et Commandes de BaseDocument40 pages03-Terminaux Et Commandes de BaseRachid BenjalouajaPas encore d'évaluation
- 03-Terminaux Et Commandes de Base PDFDocument40 pages03-Terminaux Et Commandes de Base PDFkhaledPas encore d'évaluation
- Commandes LinuxDocument47 pagesCommandes LinuxGabriel CholletPas encore d'évaluation
- TP1 SE - Initiation À Linux GPDocument10 pagesTP1 SE - Initiation À Linux GPq6bzx7b7t4Pas encore d'évaluation
- 2 InvestigationDocument11 pages2 Investigationtapha06300Pas encore d'évaluation
- Partager Des Ressources Sur Le RéseauDocument4 pagesPartager Des Ressources Sur Le RéseauetitahPas encore d'évaluation
- Memento ASR3Document21 pagesMemento ASR3Tristan DelplacePas encore d'évaluation
- Resume linux_231206_153224Document1 pageResume linux_231206_153224Hanane IfarciPas encore d'évaluation
- Commandes LinuxDocument11 pagesCommandes LinuxMichael Sniper WuPas encore d'évaluation
- Examen 102 LongDocument6 pagesExamen 102 LongPape Mignane FayePas encore d'évaluation
- Rapport UnixDocument8 pagesRapport UnixBoutaïna EttakiPas encore d'évaluation
- Serveur BackupfdgfdgDocument7 pagesServeur BackupfdgfdgŸsf ÀîttàjErPas encore d'évaluation
- LINUXDocument59 pagesLINUXrianasontsiravaPas encore d'évaluation
- Nsi 5b TD Decouverte LinuxDocument4 pagesNsi 5b TD Decouverte LinuxTite MouassaPas encore d'évaluation
- TP N 2-LinuxDocument8 pagesTP N 2-Linuxbouki15Pas encore d'évaluation
- CahierTP CoursSystemeExploitationLinux 2 Par FeuilleDocument23 pagesCahierTP CoursSystemeExploitationLinux 2 Par FeuilleERWAN KUÉTÉPas encore d'évaluation
- QCM LinuxDocument2 pagesQCM LinuxVito CoppolaPas encore d'évaluation
- Licpro0708 PDFDocument144 pagesLicpro0708 PDFPape Mignane FayePas encore d'évaluation
- Ppe SSHDocument5 pagesPpe SSHapi-349720571Pas encore d'évaluation
- MCARS21Document54 pagesMCARS21bhhPas encore d'évaluation
- LunixDocument20 pagesLunixSadouki AlaePas encore d'évaluation
- Linux - 5Document18 pagesLinux - 5houbriPas encore d'évaluation
- Maîtriser PowerShell: Guide Complet: La collection informatiqueD'EverandMaîtriser PowerShell: Guide Complet: La collection informatiquePas encore d'évaluation
- XML 3Document205 pagesXML 3youssef oulaPas encore d'évaluation
- Notion SIGDocument4 pagesNotion SIGMou MenPas encore d'évaluation
- Cours Se Chap1Document31 pagesCours Se Chap1WasimPas encore d'évaluation
- USEO Etude Réseaux Sociaux Tome2 v1 100126Document159 pagesUSEO Etude Réseaux Sociaux Tome2 v1 100126Michaël KaëlPas encore d'évaluation
- Java 4Document31 pagesJava 4Alassane BAPas encore d'évaluation
- TDn2 MensuraDocument8 pagesTDn2 Mensuraedzeghe victorPas encore d'évaluation
- Logical Volume Management (LVM) : Serveur Linux CentosDocument26 pagesLogical Volume Management (LVM) : Serveur Linux CentosChristopheProustPas encore d'évaluation
- Mise en Place D Une Application Securise PDFDocument85 pagesMise en Place D Une Application Securise PDFABBASSI RABAHPas encore d'évaluation
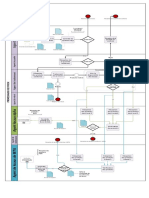
- BPMN Processus Gestion de StockDocument1 pageBPMN Processus Gestion de StockdaoPas encore d'évaluation
- Celia Cruz Quimbara Piano Amp Bass - Compress PDFDocument7 pagesCelia Cruz Quimbara Piano Amp Bass - Compress PDFAlejo DuquePas encore d'évaluation
- Syllabus Labo Web G2 ISPDocument117 pagesSyllabus Labo Web G2 ISPfrancis katunyasaPas encore d'évaluation
- Sujet 1 Modelisation UML AVance CorrectionDocument2 pagesSujet 1 Modelisation UML AVance CorrectionJULIO STEPHANEPas encore d'évaluation
- Bizhub 362 282 222 - Ug - Print Operations - FR - 1 1 1Document412 pagesBizhub 362 282 222 - Ug - Print Operations - FR - 1 1 1Ali OuchnPas encore d'évaluation
- Manuel de Nettoyage Des Donnes Lexmark - CX410Document11 pagesManuel de Nettoyage Des Donnes Lexmark - CX410NOVATEK MedninePas encore d'évaluation
- Peripheriques 221114 213148Document4 pagesPeripheriques 221114 213148Aaron Stifler ASPas encore d'évaluation
- DiplômeDocument2 pagesDiplômeIbrahim SumaïliPas encore d'évaluation
- Zehaf Aboubeker: ObjectifDocument2 pagesZehaf Aboubeker: Objectifzehaf aboubakerPas encore d'évaluation
- GL 3Document28 pagesGL 3Azza JradPas encore d'évaluation
- Systeme de FichiersDocument9 pagesSysteme de FichiersJV JVPas encore d'évaluation
- Conception Surfacique (Avance) : GSD 3 JoursDocument1 pageConception Surfacique (Avance) : GSD 3 JoursMoustapha HELALIPas encore d'évaluation
- CV Rouass MohammedDocument1 pageCV Rouass MohammedMohamed RouassPas encore d'évaluation
- Art 01 DesignDocument10 pagesArt 01 DesignSenadheera PiyanwadaPas encore d'évaluation
- Uml 1Document49 pagesUml 1jeanPas encore d'évaluation
- ListesDocument5 pagesListesaimeblumen007Pas encore d'évaluation
- Projet PHPDocument13 pagesProjet PHPHoudadine AbdouPas encore d'évaluation
- COURS4 Fonction D ExecutionDocument51 pagesCOURS4 Fonction D ExecutionIkram ZiriPas encore d'évaluation
- Architecture de Lordi Net-311 Chap 1Document14 pagesArchitecture de Lordi Net-311 Chap 1stanislas nabelewaPas encore d'évaluation