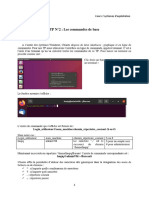
Vous aimerez peut-être aussi
- Resume LinuxDocument9 pagesResume Linuxbouananirania2004Pas encore d'évaluation
- Complements-Commandes TPDocument10 pagesComplements-Commandes TPMohammed TesjalePas encore d'évaluation
- Complements CommandesDocument10 pagesComplements CommandesmahdiPas encore d'évaluation
- Linux 2Document23 pagesLinux 2Brahim ElmoutaouakkilPas encore d'évaluation
- Administration LinuxDocument121 pagesAdministration LinuxbolathebearPas encore d'évaluation
- CommandesDocument3 pagesCommandesAbdessalem MehdiPas encore d'évaluation
- Regex, Grep Et Sed: Langages de ScriptsDocument5 pagesRegex, Grep Et Sed: Langages de ScriptsliliasaferPas encore d'évaluation
- Partie 3 UnixDocument22 pagesPartie 3 UnixFirdaous JEBRIPas encore d'évaluation
- Chap 4Document21 pagesChap 4ghaitan00Pas encore d'évaluation
- Se Sir CH3 P2Document12 pagesSe Sir CH3 P2Mohammed TesjalePas encore d'évaluation
- Commandes LinuxqfdsfqDocument8 pagesCommandes Linuxqfdsfqjedipi7523Pas encore d'évaluation
- Des Commandes Plus Avancees UnixDocument19 pagesDes Commandes Plus Avancees Unixusher01Pas encore d'évaluation
- Les Fil TresDocument33 pagesLes Fil TresIbtiheel SaafiPas encore d'évaluation
- Commandes Linux IntéressantesDocument3 pagesCommandes Linux IntéressantesAmadouPas encore d'évaluation
- La Commande SedDocument12 pagesLa Commande SedNouhaila ElPas encore d'évaluation
- 6.2. Manipulation Des Fichiers Et RépertoiresDocument17 pages6.2. Manipulation Des Fichiers Et RépertoiresAbdou Lat DiawPas encore d'évaluation
- Linux Na9la N 2Document2 pagesLinux Na9la N 2Samia RabhiouiPas encore d'évaluation
- TP3-SE AvancésDocument15 pagesTP3-SE Avancésmahmoud01 ayachiPas encore d'évaluation
- Cours Linux-Ch4Document30 pagesCours Linux-Ch4Bouraoui Ben abdallahPas encore d'évaluation
- TP N - 5 - V2Document6 pagesTP N - 5 - V2Ilias RhPas encore d'évaluation
- TP03Document3 pagesTP03ZINEB BELBACHIRPas encore d'évaluation
- Notions - IntermediairesDocument33 pagesNotions - Intermediairesadnane bouloudenePas encore d'évaluation
- Les 45 Commandes Linux Les Plus UtilesDocument25 pagesLes 45 Commandes Linux Les Plus UtilesFatim EzzahraPas encore d'évaluation
- Memo BashDocument9 pagesMemo BashsaadPas encore d'évaluation
- LinuxDocument42 pagesLinuxPap KeitPas encore d'évaluation
- 2 CMD BasesDocument7 pages2 CMD BasesSalma BoutherPas encore d'évaluation
- Grep and CoDocument18 pagesGrep and Cozukinet103Pas encore d'évaluation
- Linux Cours3Document39 pagesLinux Cours3Ens HAMANI NacerPas encore d'évaluation
- TP2Document5 pagesTP2Mahdi Kachouri100% (1)
- TP1 EnonceDocument5 pagesTP1 Enoncedhiflaoui amiraPas encore d'évaluation
- Suite Cours OSDocument75 pagesSuite Cours OSSouf 212Pas encore d'évaluation
- Système D'exploitation - TD02-03Document40 pagesSystème D'exploitation - TD02-03LOUNDOU orthegaPas encore d'évaluation
- Commandes de Bases UnixDocument6 pagesCommandes de Bases UnixBinou BiniuPas encore d'évaluation
- Annexes LinuxDocument47 pagesAnnexes LinuxAgro ForesteriePas encore d'évaluation
- Introduction À La Commande Sed: Expressions RégulièresDocument3 pagesIntroduction À La Commande Sed: Expressions RégulièresbierquedPas encore d'évaluation
- Exo1 Shell LinuxDocument5 pagesExo1 Shell LinuxjoePas encore d'évaluation
- Gestion Des Fichiers: Redirections-Pipes-RecherchesDocument58 pagesGestion Des Fichiers: Redirections-Pipes-Recherches8D audio drugsPas encore d'évaluation
- LAB2 NoncorrigéDocument3 pagesLAB2 NoncorrigéAla ArbounPas encore d'évaluation
- Memo UnixDocument5 pagesMemo UnixAya EnnaPas encore d'évaluation
- Linux VI f77 PDFDocument23 pagesLinux VI f77 PDFSalah GharbiPas encore d'évaluation
- Systeme de Fichier LinuxDocument59 pagesSysteme de Fichier Linuxhiba ammariPas encore d'évaluation
- Chapitre 3Document64 pagesChapitre 3Aïcha BOUCHRAÂPas encore d'évaluation
- Awk DigestDocument3 pagesAwk Digestelmamoun1Pas encore d'évaluation
- TP1 EnonceDocument5 pagesTP1 EnonceMacloutPas encore d'évaluation
- TP1 EnonceDocument5 pagesTP1 EnonceSaid AbbaouiPas encore d'évaluation
- Ad Linux P4Document39 pagesAd Linux P4kezadfatiPas encore d'évaluation
- Latex Présentation VFDocument42 pagesLatex Présentation VFmed ouksiliPas encore d'évaluation
- TP N 2-LinuxDocument8 pagesTP N 2-Linuxbouki15Pas encore d'évaluation
- Travail Personnel Noté Avant de Commencer (1pt) : Sorties AttenduesDocument2 pagesTravail Personnel Noté Avant de Commencer (1pt) : Sorties AttenduesEdouard CossinPas encore d'évaluation
- Cours Ms-Dos MR Bouih ModifiéDocument46 pagesCours Ms-Dos MR Bouih ModifiéSIMO BESTPas encore d'évaluation
- Filtre Sed LinuxDocument6 pagesFiltre Sed LinuxKONEPas encore d'évaluation
- SE UNIX - Part5Document16 pagesSE UNIX - Part5simohamed.arrouchPas encore d'évaluation
- TP2 - Commandes de Base - LinuxDocument4 pagesTP2 - Commandes de Base - LinuxWafae BoudrarPas encore d'évaluation
- LaTeX VademecumDocument47 pagesLaTeX VademecumganimedesfqPas encore d'évaluation
- tp1 8Document6 pagestp1 8Brice TOSSAVIPas encore d'évaluation
- Culture Et Compétences NumériqueDocument74 pagesCulture Et Compétences NumériqueAhmed Ben AliPas encore d'évaluation
- Développement WEB: Liscence Professionel SILDocument15 pagesDéveloppement WEB: Liscence Professionel SILOutmane El GharbaliPas encore d'évaluation
- Manual (FRA)Document13 pagesManual (FRA)ashok_openPas encore d'évaluation
- QCM HTML Partie 1Document3 pagesQCM HTML Partie 1Jeff FinPas encore d'évaluation
- Acp-Ridges Sources R DIADocument3 pagesAcp-Ridges Sources R DIAمسك الختامPas encore d'évaluation
- Edoc - Tips Telecharger Tout Se Joue Avant 6 Ans PDF Livre GratuitDocument2 pagesEdoc - Tips Telecharger Tout Se Joue Avant 6 Ans PDF Livre GratuitNo FoundPas encore d'évaluation
- TD3 Et Suppl+ - MentDocument13 pagesTD3 Et Suppl+ - MentAbdellah GhoualiPas encore d'évaluation
- VuejsDocument3 pagesVuejsMohamed Aziz RbiiPas encore d'évaluation
- Guide Du Pirate ÉclairéDocument9 pagesGuide Du Pirate ÉclairéAdrian Garcia PradoPas encore d'évaluation
- Lase9 UnixDocument3 pagesLase9 UnixKãrîm KåhlìPas encore d'évaluation
- TP Creer Un Site StatiqueDocument11 pagesTP Creer Un Site StatiqueDriss EssaadiPas encore d'évaluation
- Reajustement Des CumulsDocument8 pagesReajustement Des CumulsNacer IdjedarenePas encore d'évaluation
- Operations Unitaires en Genie Biologique Tome 3 La Fermentation 2866175964Document1 pageOperations Unitaires en Genie Biologique Tome 3 La Fermentation 2866175964Zineddine RegadPas encore d'évaluation
- HTML5 ResumeDocument4 pagesHTML5 Resumeyassmine delladjiPas encore d'évaluation
- Examen XML 2023 RatDocument2 pagesExamen XML 2023 Rathajar.filali4Pas encore d'évaluation
- Regional 2Document3 pagesRegional 2rachida ajbayrPas encore d'évaluation
- Norme CIREO 2.1: Spécification Technique (Image & Son) Pour La Fabrication D'un DCPDocument1 pageNorme CIREO 2.1: Spécification Technique (Image & Son) Pour La Fabrication D'un DCPVincent FollézouPas encore d'évaluation
- Fichier Indd en PDFDocument2 pagesFichier Indd en PDFJennyPas encore d'évaluation
- La Formule de DieuDocument2 pagesLa Formule de Dieuxojires100% (1)
- Lecteur Musique - Play Musique - Applications SurDocument1 pageLecteur Musique - Play Musique - Applications SurXNINEPas encore d'évaluation
- QCM Linux101trainingDocument9 pagesQCM Linux101trainingHassan Faouzi0% (1)
- Rene Vannes Dictionnaire Universel Des Luthiers Preface de Giovanni Iviglia Avertissement de Ernest B001D3IO0QDocument2 pagesRene Vannes Dictionnaire Universel Des Luthiers Preface de Giovanni Iviglia Avertissement de Ernest B001D3IO0QRichard Arellano PaezPas encore d'évaluation
- GDFGSDFDocument17 pagesGDFGSDFRocio ChuraPas encore d'évaluation
- ChangesDocument8 pagesChangesperiPas encore d'évaluation
- Installation Quartus 9.1 Sur PCDocument20 pagesInstallation Quartus 9.1 Sur PCZanarkand TidusPas encore d'évaluation
- Qasr Al Chawq Le Palais Du DesirDocument1 pageQasr Al Chawq Le Palais Du DesirHana ChaabnaPas encore d'évaluation
- Comment Compresser Fichier PDF Avec 7zipDocument2 pagesComment Compresser Fichier PDF Avec 7zipKatrinaPas encore d'évaluation
- TP FTPDocument3 pagesTP FTPhadjar ziane cherif100% (1)
- DOCTYPE HTMLDocument3 pagesDOCTYPE HTMLkhalil.diaibrahimaPas encore d'évaluation
- Bac Pratique 26052018 Algo 8h30Document2 pagesBac Pratique 26052018 Algo 8h30Khouloud Bjaoui BouzidiPas encore d'évaluation