Vous aimerez peut-être aussi
- Apache SparkDocument16 pagesApache SparkMOHAMED ELRHAOUATPas encore d'évaluation
- Cours SPARK REDUIT V Impression (3450) - 1Document138 pagesCours SPARK REDUIT V Impression (3450) - 1Mohamed ElamriPas encore d'évaluation
- Ch2 (Part 1)Document27 pagesCh2 (Part 1)ya.latrechePas encore d'évaluation
- (Big Data Analytics) CHAP2 - Scala SparkDocument42 pages(Big Data Analytics) CHAP2 - Scala SparkMbarki Med OussemaPas encore d'évaluation
- SparkDocument54 pagesSparkNora HabrichPas encore d'évaluation
- Chapitre2 BigDataDocument35 pagesChapitre2 BigDataouma imaPas encore d'évaluation
- Cours Big Data Chap4Document17 pagesCours Big Data Chap4Ben YasserPas encore d'évaluation
- Spark JiDocument37 pagesSpark JiFaten ClubistiaPas encore d'évaluation
- Resume Big DataDocument9 pagesResume Big DataKhaoula RAZZAKIPas encore d'évaluation
- SparkDocument26 pagesSparkRaja BensalemPas encore d'évaluation
- Chapitre4 Archi Spark 4Document31 pagesChapitre4 Archi Spark 4safia fezai100% (1)
- CH 1Document53 pagesCH 1ya.latrechePas encore d'évaluation
- Cours1 2 Bigdata 1Document93 pagesCours1 2 Bigdata 1mohamed aziz madhounPas encore d'évaluation
- No SQ L Avec CassandraDocument7 pagesNo SQ L Avec CassandrayugaselvanPas encore d'évaluation
- Leçon5 SparkDocument18 pagesLeçon5 SparkMido proPas encore d'évaluation
- Application2 - Initiation Spark PDFDocument7 pagesApplication2 - Initiation Spark PDFAdministration IHETPas encore d'évaluation
- Cours5 Architecture - Big Data SparkDocument43 pagesCours5 Architecture - Big Data Sparkalaska8fouadPas encore d'évaluation
- Cours Intro Hadoop v27022014 Erraki HaddadDocument62 pagesCours Intro Hadoop v27022014 Erraki HaddadZohra CHANNOUFPas encore d'évaluation
- Hadoop (Rihab Chaouch Et Alaa El GhoulDocument17 pagesHadoop (Rihab Chaouch Et Alaa El GhoulChaouch Mohamed Abd SalemPas encore d'évaluation
- Less01 DB Architecture MB3Document26 pagesLess01 DB Architecture MB3abdelali ELFAIZPas encore d'évaluation
- Partie Hadoop Et EcosystèmeDocument93 pagesPartie Hadoop Et EcosystèmeSafa 'Pas encore d'évaluation
- JPA HibernateDocument23 pagesJPA HibernatekhoudidirfatimaPas encore d'évaluation
- PysparkDocument2 pagesPysparkMohammed Sabeur GHARBIPas encore d'évaluation
- ST Tutor4 Pyspark MllibDocument7 pagesST Tutor4 Pyspark MllibZorzoPas encore d'évaluation
- Big Data AnalyticsDocument112 pagesBig Data AnalyticssaadPas encore d'évaluation
- SparkDocument4 pagesSparkfatima ezzahrae el ghatousPas encore d'évaluation
- Cours SparkDocument63 pagesCours SparkZorzoPas encore d'évaluation
- Résumé Big DataDocument6 pagesRésumé Big DataEl Moumne NihalPas encore d'évaluation
- Hadoop 1Document61 pagesHadoop 1Mouhamed BouazziPas encore d'évaluation
- Cours BDD - Avancées (Slide)Document313 pagesCours BDD - Avancées (Slide)hassan adnanPas encore d'évaluation
- SparkDocument28 pagesSparkhajar.filali4Pas encore d'évaluation
- No SQLDocument28 pagesNo SQLAZONTO conradPas encore d'évaluation
- Examen Big DATADocument4 pagesExamen Big DATAzaki workerPas encore d'évaluation
- Les Enjeux Du Big Data Pour La Mise en Place Des Smart-GridsDocument19 pagesLes Enjeux Du Big Data Pour La Mise en Place Des Smart-GridsSalim MehenniPas encore d'évaluation
- Chapitre 2 Final FRDocument94 pagesChapitre 2 Final FRÄya ĶhPas encore d'évaluation
- ch6 Neo4jDocument17 pagesch6 Neo4jHoussayen Ben OuhibaPas encore d'évaluation
- Orient DBDocument27 pagesOrient DBKlaus ERBAKPas encore d'évaluation
- Project Database Group 5Document28 pagesProject Database Group 5Klaus ERBAKPas encore d'évaluation
- BigChapitre 03 Partie02Document11 pagesBigChapitre 03 Partie02khliaissa46Pas encore d'évaluation
- ControleDocument24 pagesControlechristian raharinirinaPas encore d'évaluation
- Apache Spark Interview Questions andDocument19 pagesApache Spark Interview Questions andMohamed RahalPas encore d'évaluation
- ScalaDocument33 pagesScalaZouhair NgPas encore d'évaluation
- Spark IntroductionDocument22 pagesSpark IntroductionBadiss JabouPas encore d'évaluation
- Big Data: Marie NDIAYEDocument28 pagesBig Data: Marie NDIAYESerigne NdourPas encore d'évaluation
- Intro BIG DATADocument34 pagesIntro BIG DATAFernovy GesnerPas encore d'évaluation
- TDBD Part1Document24 pagesTDBD Part1Mbaye Babacar MBODJPas encore d'évaluation
- Big Data: Marie NDIAYEDocument11 pagesBig Data: Marie NDIAYESerigne NdourPas encore d'évaluation
- Correction Examen Big Data 2020 2021 Session NormaleDocument4 pagesCorrection Examen Big Data 2020 2021 Session NormaleNora Habrich88% (8)
- Chapitre 2 Hadoop-Part1Document26 pagesChapitre 2 Hadoop-Part1souhail nahed100% (1)
- ComposantsDocument28 pagesComposantsKHAWLA JABARIPas encore d'évaluation
- Hadoop EcosystemDocument37 pagesHadoop Ecosystemhajar.filali4Pas encore d'évaluation
- MP1 Big Data S4Document39 pagesMP1 Big Data S4Hammami MélekPas encore d'évaluation
- Cours JavaDocument91 pagesCours Javafred biggyPas encore d'évaluation
- Leçon2 - Hadoop, MapReduce Et Le BigDocument52 pagesLeçon2 - Hadoop, MapReduce Et Le BigMido proPas encore d'évaluation
- Présentation Sans TitreDocument20 pagesPrésentation Sans TitreOmayma EddarrajiPas encore d'évaluation
- Chapitre 3 LEcosystème Hadoop VFDocument42 pagesChapitre 3 LEcosystème Hadoop VFBrahim Ben Saada100% (1)
- Ch5 Principes Du NoSQLDocument20 pagesCh5 Principes Du NoSQLzidPas encore d'évaluation
- 1 ELFADDOULI BigData HDFS 2022Document22 pages1 ELFADDOULI BigData HDFS 2022abdou boulifPas encore d'évaluation
- Decisionnel OpensourceDocument103 pagesDecisionnel Opensourceapi-3746600100% (3)
- TD 5Document2 pagesTD 5LGT AMINEPas encore d'évaluation
- Economie Numerique Partie1Document30 pagesEconomie Numerique Partie1Seydou TourePas encore d'évaluation
- 08-ch8 VLSM-CIDRDocument32 pages08-ch8 VLSM-CIDRPrince HoungbassePas encore d'évaluation
- Passage D Un Moteur 4D56 100cv en 115cvDocument20 pagesPassage D Un Moteur 4D56 100cv en 115cvCarlos VelascoPas encore d'évaluation
- Guide Pour La Constitution Des Dossiers Pour L'émission de La Monnaie Électronique Par Les Trésors Publics NationauxDocument26 pagesGuide Pour La Constitution Des Dossiers Pour L'émission de La Monnaie Électronique Par Les Trésors Publics NationauxChamgwei IzuzuPas encore d'évaluation
- (Liebert HPM) Documentation-Commerciale-EmersonDocument16 pages(Liebert HPM) Documentation-Commerciale-EmersonRahim HkmPas encore d'évaluation
- Devoir de Synthèse N°1 - Tableur Excel - 9ème (2009-2010) 2Document2 pagesDevoir de Synthèse N°1 - Tableur Excel - 9ème (2009-2010) 2touati8100% (2)
- Pneu Premier Prix 165 70 R13 79T 150634 21002069 PDFDocument1 pagePneu Premier Prix 165 70 R13 79T 150634 21002069 PDFJean EudesPas encore d'évaluation
- Android France FR 2009-12-23 Integrer Des Pub Admob Dans SesDocument17 pagesAndroid France FR 2009-12-23 Integrer Des Pub Admob Dans SesYoussef AddiPas encore d'évaluation
- Memoire - FinalDocument83 pagesMemoire - FinalKhadija BelkasPas encore d'évaluation
- F0 053 166 ConvertiDocument66 pagesF0 053 166 ConvertiWalid AousPas encore d'évaluation
- Cours - Traitement de TexteDocument3 pagesCours - Traitement de Texteأحمد رميدةPas encore d'évaluation
- Configuration FXODocument6 pagesConfiguration FXOCamus LanmadouceloPas encore d'évaluation
- Fiche de TP PointeursDocument4 pagesFiche de TP PointeursBERROUANEPas encore d'évaluation
- Chapitre 2 4pDocument32 pagesChapitre 2 4pFiras KachroudiPas encore d'évaluation
- Chap 4 Gestion GroupesDocument15 pagesChap 4 Gestion Groupessoutien russePas encore d'évaluation
- Cours 2 Fibre OptiqueDocument6 pagesCours 2 Fibre OptiqueFaty GueyePas encore d'évaluation
- Exercices TransistorDocument2 pagesExercices Transistorمسلمة حرةPas encore d'évaluation
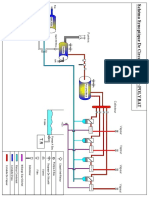
- Schéma Synoptique de Circuit de Vapeur POLYBATDocument1 pageSchéma Synoptique de Circuit de Vapeur POLYBATZribi AmeniPas encore d'évaluation
- Gestion de Droits D'accès Dans Des Réseaux Informatiques: MémoireDocument101 pagesGestion de Droits D'accès Dans Des Réseaux Informatiques: MémoireMohamed SaadaouiPas encore d'évaluation
- Expose Sur Le PontDocument42 pagesExpose Sur Le PontPrince IrPas encore d'évaluation
- Formation RS MINERVEDocument7 pagesFormation RS MINERVEthiePas encore d'évaluation
- Choix Outil ReportingDocument4 pagesChoix Outil ReportingJihad MifdalPas encore d'évaluation
- EBS Premium DXI 460Document128 pagesEBS Premium DXI 460Babacar Ndiaye100% (1)
- Document PDFDocument20 pagesDocument PDFanass sbniPas encore d'évaluation
- Exemple de CDCDocument8 pagesExemple de CDCtahaelayaPas encore d'évaluation
- Wissal RabahDocument8 pagesWissal RabahHEDIIIPas encore d'évaluation
- Inbound-Marketing MR MahmoudDocument23 pagesInbound-Marketing MR Mahmoudahlem meftahPas encore d'évaluation
- PC Astuces - Protéger Ses Enfants Sous Windows 7Document4 pagesPC Astuces - Protéger Ses Enfants Sous Windows 7Polovsky MG GodenPas encore d'évaluation
- CindyniqueDocument3 pagesCindyniqueSilvia JaimesPas encore d'évaluation