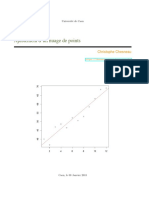
Vous aimerez peut-être aussi
- Premier Essai Apres Les ResuméDocument19 pagesPremier Essai Apres Les Resuménaimemed3Pas encore d'évaluation
- Chapitre 1Document17 pagesChapitre 1naimemed3Pas encore d'évaluation
- MLchap1 Verpedagogique23 24Document11 pagesMLchap1 Verpedagogique23 24Sameh SebaiPas encore d'évaluation
- Questionnaire Machine LearningDocument21 pagesQuestionnaire Machine LearningNan-Has NagorngarPas encore d'évaluation
- EX ML Corrigé CII-3-SSIR A BDocument4 pagesEX ML Corrigé CII-3-SSIR A BsnoussiwahibaPas encore d'évaluation
- ReservoirDocument11 pagesReservoirkarel nkpwangPas encore d'évaluation
- Chapitre7 Intelligence ArtificielleDocument29 pagesChapitre7 Intelligence ArtificiellevenanceharoldPas encore d'évaluation
- Chapitre 4Document8 pagesChapitre 4Meziane AkliPas encore d'évaluation
- Projet Recherche Examen Intro RechercheDocument5 pagesProjet Recherche Examen Intro Recherchejunior gbodjoPas encore d'évaluation
- Introduction Au Machine Learning - Chapitre1Document13 pagesIntroduction Au Machine Learning - Chapitre1dj Best MusicPas encore d'évaluation
- Machine Learning - InitiationDocument18 pagesMachine Learning - InitiationAnass Roman100% (1)
- Apprentissage Supervisé VS Apprentissage Non SuperviséDocument6 pagesApprentissage Supervisé VS Apprentissage Non Supervisélouki.riahiPas encore d'évaluation
- Introduction To Machine LearningDocument6 pagesIntroduction To Machine LearningArsalan TlmPas encore d'évaluation
- ML PRDocument66 pagesML PRAbdrrahim ElhPas encore d'évaluation
- Cours MM Chap1 2020Document11 pagesCours MM Chap1 2020Sameh SebaiPas encore d'évaluation
- Tps Data Mining (Matlab)Document14 pagesTps Data Mining (Matlab)Mohammed Amine Halbaba100% (10)
- OMEREDIAPODocument41 pagesOMEREDIAPOBajikila AmandPas encore d'évaluation
- Top 50 ML Q&A - Follow Dr. Angshuman Ghosh For More - En.fr - 2Document8 pagesTop 50 ML Q&A - Follow Dr. Angshuman Ghosh For More - En.fr - 2kader aziziPas encore d'évaluation
- E BookDocument12 pagesE Bookbrico johnPas encore d'évaluation
- Cours IntroductifsDocument13 pagesCours Introductifsnaimemed3Pas encore d'évaluation
- INF 365 ING-Données-Chap3 - 2019Document9 pagesINF 365 ING-Données-Chap3 - 2019NOUTCHEU CHOUBAELPas encore d'évaluation
- Chap 2Document5 pagesChap 2Zineb DbbPas encore d'évaluation
- Chapitre Apache Mahout & Machine LearningDocument85 pagesChapitre Apache Mahout & Machine LearningKhalid HarratiPas encore d'évaluation
- Cours MLDocument40 pagesCours MLRoni YakamPas encore d'évaluation
- Machine Learning (Deep Learning) Pour La Vision Artificielle 2021Document4 pagesMachine Learning (Deep Learning) Pour La Vision Artificielle 2021youcef88Pas encore d'évaluation
- Projet IADocument29 pagesProjet IAfarahzayani82Pas encore d'évaluation
- Introduction À L'apprentissage Automatique.1Document4 pagesIntroduction À L'apprentissage Automatique.1aya bouremanaPas encore d'évaluation
- Machine Learning Avec PythonDocument8 pagesMachine Learning Avec Pythonhyacinthe d'almeida100% (1)
- Diapo1ML DIC1 2022Document48 pagesDiapo1ML DIC1 2022Dia Mouhamadou NabyPas encore d'évaluation
- Chapitre 2Document63 pagesChapitre 2DUTERRAGE HugoPas encore d'évaluation
- Machine LearningDocument5 pagesMachine LearningOumayma Ben YoussefPas encore d'évaluation
- Diapo BienvenueDocument44 pagesDiapo BienvenueBajikila AmandPas encore d'évaluation
- Machine Learning (ML) : Imane AllaouziDocument16 pagesMachine Learning (ML) : Imane AllaouziChaymaePas encore d'évaluation
- Cours1 - Intoduction À L'apprentissage Et ComplexitéDocument42 pagesCours1 - Intoduction À L'apprentissage Et ComplexitéMoumouh KingPas encore d'évaluation
- Exposé MLDocument31 pagesExposé MLSoltan SadokPas encore d'évaluation
- 2 - 9 - IA CoursDocument19 pages2 - 9 - IA CoursHafsa MehdaouiPas encore d'évaluation
- Cours ML Chap1Document54 pagesCours ML Chap1Nour Ben NasserPas encore d'évaluation
- Data MiningDocument5 pagesData Miningzakaria kassemiPas encore d'évaluation
- 1 Machine Learning (Intro)Document25 pages1 Machine Learning (Intro)hacke9834Pas encore d'évaluation
- Section 3.1 - ApprentissagesDocument25 pagesSection 3.1 - ApprentissagesBacem ChPas encore d'évaluation
- Chap3-Apprentissage AutomatiqueDocument41 pagesChap3-Apprentissage AutomatiqueLouayPas encore d'évaluation
- Satge RapportDocument7 pagesSatge Rapportmed ayoub khPas encore d'évaluation
- Python Inter B3 - 5Document7 pagesPython Inter B3 - 5elkemar le saoPas encore d'évaluation
- L'intelligence Artificielle AybDocument20 pagesL'intelligence Artificielle AybSasi AybPas encore d'évaluation
- Chapitre II Machine LearningDocument161 pagesChapitre II Machine Learningoumayma bayarPas encore d'évaluation
- Machine LearningDocument42 pagesMachine Learningchristian n'takpePas encore d'évaluation
- Apprentissage AutomatiqueDocument13 pagesApprentissage AutomatiqueNajib Najib0% (1)
- EF ML TekUP 22-23Document7 pagesEF ML TekUP 22-23sarra gbPas encore d'évaluation
- Apprentissage AutomatiqueDocument22 pagesApprentissage AutomatiqueSamue EKEPas encore d'évaluation
- Algorithme Machine LearngDocument16 pagesAlgorithme Machine LearngYayaPas encore d'évaluation
- Cours P1Document90 pagesCours P1Nazih redaPas encore d'évaluation
- Interrogation IADocument10 pagesInterrogation IAmatthieus701Pas encore d'évaluation
- Algorithme2023 Cours Isc Ok - 031323Document49 pagesAlgorithme2023 Cours Isc Ok - 031323Armand ØfficielPas encore d'évaluation
- TP3 DMDocument7 pagesTP3 DMHamdi GdhamiPas encore d'évaluation
- ML Algorithm UseDocument15 pagesML Algorithm UseAbdallahi SidiPas encore d'évaluation
- Algorithmique IDocument41 pagesAlgorithmique IJoumana IsraePas encore d'évaluation
- Sujet 46Document14 pagesSujet 46Amìnè Cheìkh MèdPas encore d'évaluation
- EF ML TekUP 22-23Document4 pagesEF ML TekUP 22-23sarra gbPas encore d'évaluation
- Le diagramme d'Ishikawa: Les liens de cause à effetD'EverandLe diagramme d'Ishikawa: Les liens de cause à effetÉvaluation : 3.5 sur 5 étoiles3.5/5 (3)
- Analyser les données qualitatives en gestionD'EverandAnalyser les données qualitatives en gestionPas encore d'évaluation
- Cours D'econometrie Licence 3Document67 pagesCours D'econometrie Licence 3Guillaume KOUASSI100% (1)
- Économétrie CHP 2-1Document15 pagesÉconométrie CHP 2-1HIGHLIGHT TVPas encore d'évaluation
- Chapitre II - Homogeneisation Des Données PluviomériquesDocument7 pagesChapitre II - Homogeneisation Des Données PluviomériquesDieme EphremPas encore d'évaluation
- Rapport de Modèle de Marché PDFDocument31 pagesRapport de Modèle de Marché PDFAbdelfatah Joudani33% (3)
- BTS Cours 6 Stats2varDocument8 pagesBTS Cours 6 Stats2varIbrahimPas encore d'évaluation
- Data Science For Business and FinanceDocument51 pagesData Science For Business and Financetouimar hamzaPas encore d'évaluation
- Chronologique Actualisee1Document33 pagesChronologique Actualisee1Christian EhouanouPas encore d'évaluation
- Prediction Des Proprietes Des Materiaux Par Apprentissage.Document58 pagesPrediction Des Proprietes Des Materiaux Par Apprentissage.BOULAHLIB ALDJIAPas encore d'évaluation
- EXER CORR Modèle Linéaire SimpleDocument15 pagesEXER CORR Modèle Linéaire Simpleantonio aniPas encore d'évaluation
- SciencesDonnees TD1 5 SujetsDocument14 pagesSciencesDonnees TD1 5 SujetsWiem SmidaPas encore d'évaluation
- Analyse en Composantes PrincipalesDocument10 pagesAnalyse en Composantes PrincipalesAya El Hadri100% (1)
- Document From Jaber KhlieDocument3 pagesDocument From Jaber Khlieoussama khatrouniPas encore d'évaluation
- Choix Des Tests Et Analyses Statistiques V2Document88 pagesChoix Des Tests Et Analyses Statistiques V2carmen84100% (1)
- Régression Linéaire (Pour TD)Document10 pagesRégression Linéaire (Pour TD)Mohamed EL AminePas encore d'évaluation
- Epreuve 2019 PDFDocument3 pagesEpreuve 2019 PDFAbdoulkarim100% (1)
- Rivera Et Al, 2017 (d2)Document11 pagesRivera Et Al, 2017 (d2)Nicol Mariana V. FernándezPas encore d'évaluation
- Econométrie L3 2023-2024. Chap1-1Document83 pagesEconométrie L3 2023-2024. Chap1-1rakissagajacquesPas encore d'évaluation
- Chapitre III PartA Version CorrDocument82 pagesChapitre III PartA Version CorrSamantha FarahPas encore d'évaluation
- A JustementDocument40 pagesA JustementBtdbtdPas encore d'évaluation
- Éléments de Statistique DescriptiveDocument19 pagesÉléments de Statistique DescriptiveSidoïne Bitho GbeteyPas encore d'évaluation
- FISE2 Estimation IntroDocument19 pagesFISE2 Estimation Introthomas vwPas encore d'évaluation
- inseaTD RLS2Document3 pagesinseaTD RLS2kata brhPas encore d'évaluation
- FT TechCharacter 04.08.2014 FRA Amitech-ProtDocument32 pagesFT TechCharacter 04.08.2014 FRA Amitech-Protmohamed roubioPas encore d'évaluation
- Bellahmer H.Document72 pagesBellahmer H.Armel YMGPas encore d'évaluation
- Toutes Les Notes Hcia Ai Huawei Examen Simulé ÉcritDocument31 pagesToutes Les Notes Hcia Ai Huawei Examen Simulé ÉcritScribdTranslationsPas encore d'évaluation
- Econometrie EG6Document3 pagesEconometrie EG6Abd Nor OufkirPas encore d'évaluation
- 16 Resine EchangeuseDocument3 pages16 Resine Echangeuseincocc nnuuPas encore d'évaluation
- Apprentissage Supervisé - Introduction - vf23Document38 pagesApprentissage Supervisé - Introduction - vf23shi ftPas encore d'évaluation
- Commerce International PDFDocument24 pagesCommerce International PDFryadPas encore d'évaluation
- TD Capteurs DIC2Document10 pagesTD Capteurs DIC2Cheikh Ibrahima Alioune SAMBOUPas encore d'évaluation