Vous aimerez peut-être aussi
- RapportDocument29 pagesRapportMariem SelmiPas encore d'évaluation
- Rapport Stage Lamme ABRAICH AYOUBDocument97 pagesRapport Stage Lamme ABRAICH AYOUBAyoub AbraichPas encore d'évaluation
- Data Mining ChaimaDocument15 pagesData Mining ChaimaMariem SelmiPas encore d'évaluation
- Logiciel D'ajustements Statistiques: OrstomDocument33 pagesLogiciel D'ajustements Statistiques: OrstomJunior WayagPas encore d'évaluation
- RapportDocument8 pagesRapportachref.chalbiPas encore d'évaluation
- Manuscrit Final TodoranDocument205 pagesManuscrit Final TodoranKHITER YOUSSOUFPas encore d'évaluation
- Ist Proba Stats l3Document80 pagesIst Proba Stats l3Locmann NacroPas encore d'évaluation
- APznzaahOLeMI2KTJc2BZ8PzV1qKFyUlHqpIIFNpFP5-eYyChj5CAx0fU6FNtbJyjjMGtDPGWyhvGHvRO1ynkxR7JCue9fQVklzm2HI5xxfAfl6tYBODa83HYhzLClL RbKikL1fWFxNlUkmIjMrSURQuDjjHwMNGpYHJlUo3wlLAeuhe4uzrUa8P0JupEoMCyUDDocument27 pagesAPznzaahOLeMI2KTJc2BZ8PzV1qKFyUlHqpIIFNpFP5-eYyChj5CAx0fU6FNtbJyjjMGtDPGWyhvGHvRO1ynkxR7JCue9fQVklzm2HI5xxfAfl6tYBODa83HYhzLClL RbKikL1fWFxNlUkmIjMrSURQuDjjHwMNGpYHJlUo3wlLAeuhe4uzrUa8P0JupEoMCyUDGhassen OrfPas encore d'évaluation
- Cours de Data Mining 1-Introduction-EPFDocument19 pagesCours de Data Mining 1-Introduction-EPFClaireBrunetPas encore d'évaluation
- Cours de Data Mining 2-Metier Et Donnees-EPFDocument57 pagesCours de Data Mining 2-Metier Et Donnees-EPFamarasidibeavmPas encore d'évaluation
- Cours de Topographie Et Topométrie GénéraleDocument65 pagesCours de Topographie Et Topométrie GénéraleMay KodoPas encore d'évaluation
- BiskraDocument96 pagesBiskraSouhaila DjaffalPas encore d'évaluation
- Cours Proba StatDocument61 pagesCours Proba StatJean Luc NgouafongPas encore d'évaluation
- Notes de Cours - Analyse Quantitative Des Données - L2 ESR-2020Document29 pagesNotes de Cours - Analyse Quantitative Des Données - L2 ESR-2020Yasmine ArounaPas encore d'évaluation
- Traitement Numerique Des Images PDFDocument204 pagesTraitement Numerique Des Images PDFÏmãÐøCħâřmãntPas encore d'évaluation
- Cours de CSPro - BonDocument53 pagesCours de CSPro - BonMerry Soussouni DEHOUEPas encore d'évaluation
- AccessDocument32 pagesAccessmobo2008Pas encore d'évaluation
- I - Data MiningDocument10 pagesI - Data Miningkitaki2020Pas encore d'évaluation
- Polycopié TP FDDDocument86 pagesPolycopié TP FDDmadmajPas encore d'évaluation
- 1 Data MiningDocument74 pages1 Data MiningKaouther BenaliPas encore d'évaluation
- Data MiningDocument49 pagesData MiningDjimramadji JosuéPas encore d'évaluation
- 0249governance Indicators A Users Guide, 2nd Edition (2007) LDocument100 pages0249governance Indicators A Users Guide, 2nd Edition (2007) LmohammedbakkarPas encore d'évaluation
- Memoire de Master de MathematiquesDocument65 pagesMemoire de Master de MathematiquesCheick Amed TraorePas encore d'évaluation
- Cours1 - Intoduction À L'analyse de Données - 2Document28 pagesCours1 - Intoduction À L'analyse de Données - 2abdelalim gacemPas encore d'évaluation
- Bourahdoun - Mohammed Ilyas1603808428Document60 pagesBourahdoun - Mohammed Ilyas1603808428Meli MaylessPas encore d'évaluation
- Polycopié Boukli Hacène Chérifa HydrauliqueDocument79 pagesPolycopié Boukli Hacène Chérifa HydrauliqueApollos_80Pas encore d'évaluation
- Hamma ManelDocument46 pagesHamma ManelMeryem BouchemamaPas encore d'évaluation
- Dra 12 124789 07543a Panorama Des Bases de Données V4vweb 1 1393947572Document199 pagesDra 12 124789 07543a Panorama Des Bases de Données V4vweb 1 1393947572jfjd6889Pas encore d'évaluation
- Entrepôts de Données Pour L'aide À La Decision MedicaleDocument164 pagesEntrepôts de Données Pour L'aide À La Decision MedicaleHabib Bedouin BensafiPas encore d'évaluation
- Allele Imane f5 InformatiqueDocument69 pagesAllele Imane f5 InformatiqueChrifPas encore d'évaluation
- Chamek Linda MagisterDocument113 pagesChamek Linda MagisterLeon Joel LukusaPas encore d'évaluation
- Rapport TP INFOVIS BOUAZIZ Sofiane OUSSAIDENE Smail SID1Document10 pagesRapport TP INFOVIS BOUAZIZ Sofiane OUSSAIDENE Smail SID1fatmazohra rezkellahPas encore d'évaluation
- Rapport Projet DataminingDocument16 pagesRapport Projet DataminingMariem SelmiPas encore d'évaluation
- Corige Finale1Document41 pagesCorige Finale1kakeraPas encore d'évaluation
- Analyse de DonnéeDocument59 pagesAnalyse de DonnéeMeryeme M'HouhPas encore d'évaluation
- These Combe David 2013 PDFDocument200 pagesThese Combe David 2013 PDFSerge AlainPas encore d'évaluation
- Poly TPDocument38 pagesPoly TPChakib BenmhamedPas encore d'évaluation
- Rapport BigDataDocument13 pagesRapport BigDataAyoub AminePas encore d'évaluation
- Cryptographie Dans Les Big DataDocument39 pagesCryptographie Dans Les Big DataYouth ZoomPas encore d'évaluation
- DM Chapitre1Document20 pagesDM Chapitre1elarrouchiPas encore d'évaluation
- Amélioration de La Qualité de Service D'une Application Android À Base D'un Entrepôt de Données Actif.Document94 pagesAmélioration de La Qualité de Service D'une Application Android À Base D'un Entrepôt de Données Actif.trc.berlinPas encore d'évaluation
- Rapport BigDataDocument13 pagesRapport BigDataDa CostaPas encore d'évaluation
- Tecniques D'enquetes Fevrier 22 Partie I CtpeaDocument23 pagesTecniques D'enquetes Fevrier 22 Partie I CtpeaJoseph K. WidgyPas encore d'évaluation
- StatisticsreportDocument36 pagesStatisticsreportit's chaimaPas encore d'évaluation
- Rapport IADocument19 pagesRapport IAZOHORE BATRANIPas encore d'évaluation
- Chapitre1 DM RebbahDocument19 pagesChapitre1 DM RebbahSomaya LgtPas encore d'évaluation
- UntitledDocument179 pagesUntitledGabriel OliveiraPas encore d'évaluation
- Simulations StochastiquesDocument121 pagesSimulations StochastiquesmedamichPas encore d'évaluation
- Sansen Joris 2017Document308 pagesSansen Joris 2017Warda FloraPas encore d'évaluation
- Acp TutorielDocument49 pagesAcp TutorielAli HamiehPas encore d'évaluation
- Vision stéréo par ordinateur: Explorer la perception de la profondeur dans la vision par ordinateurD'EverandVision stéréo par ordinateur: Explorer la perception de la profondeur dans la vision par ordinateurPas encore d'évaluation
- Introduction à l’analyse des données de sondage avec SPSS : Guide d’auto-apprentissageD'EverandIntroduction à l’analyse des données de sondage avec SPSS : Guide d’auto-apprentissagePas encore d'évaluation
- Traité d'économétrie financière: Modélisation financièreD'EverandTraité d'économétrie financière: Modélisation financièrePas encore d'évaluation
- Vision par ordinateur: Explorer les profondeurs de la vision par ordinateurD'EverandVision par ordinateur: Explorer les profondeurs de la vision par ordinateurPas encore d'évaluation
- Survivre à son projet de recherche: Introduction à la méthodologie en gestionD'EverandSurvivre à son projet de recherche: Introduction à la méthodologie en gestionPas encore d'évaluation
- Appliquer le modèle de Rasch: Défis et pistes de solutionD'EverandAppliquer le modèle de Rasch: Défis et pistes de solutionPas encore d'évaluation
- Developing Cost Estimates for Environmental Remediation ProjectsD'EverandDeveloping Cost Estimates for Environmental Remediation ProjectsPas encore d'évaluation
- Initiation au travail intellectuel et à la recherche: Pratique réflexive de recherche scientifiqueD'EverandInitiation au travail intellectuel et à la recherche: Pratique réflexive de recherche scientifiquePas encore d'évaluation
- RCR Rapport3Document20 pagesRCR Rapport3Younes ZizouPas encore d'évaluation
- Chap 02 - Expressions RégulièresDocument44 pagesChap 02 - Expressions RégulièresYounes ZizouPas encore d'évaluation
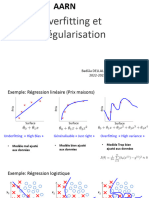
- Chap5 Overfit RegularisationDocument13 pagesChap5 Overfit RegularisationYounes ZizouPas encore d'évaluation
- 01 Chap1 - Introduction A La RI 2023 2024-1Document10 pages01 Chap1 - Introduction A La RI 2023 2024-1Younes ZizouPas encore d'évaluation
- Cours - Modélisation-Statistique - Test D - IndépendanceDocument22 pagesCours - Modélisation-Statistique - Test D - IndépendanceTahiri LahcenPas encore d'évaluation
- Statistique UnivarieeDocument7 pagesStatistique Univarieeayoub faresPas encore d'évaluation
- Calcul de VolatilitéDocument3 pagesCalcul de VolatilitéTavarez eckoPas encore d'évaluation
- Les Cartes de ContrôleDocument9 pagesLes Cartes de ContrôleabdelhafidPas encore d'évaluation
- Introduction - Objectifs: Section 3Document12 pagesIntroduction - Objectifs: Section 3malakPas encore d'évaluation
- Série Des Exercices - IDocument10 pagesSérie Des Exercices - IbabazhyrtPas encore d'évaluation
- TP1 StatDesc RDocument4 pagesTP1 StatDesc RThiaré ModouPas encore d'évaluation
- CoesDocument5 pagesCoesAhmed MaPas encore d'évaluation
- 1er Devoir Du 3ème Trimestre Mathematiques 1ere Ab 2021-2022 Cpeg Saint JustinDocument2 pages1er Devoir Du 3ème Trimestre Mathematiques 1ere Ab 2021-2022 Cpeg Saint JustinBrice SedagondjiPas encore d'évaluation
- EXERCICE 2 Statistique CorrectionDocument4 pagesEXERCICE 2 Statistique CorrectionmamadouibrahimanPas encore d'évaluation
- TD2 BiostatistiqueDocument1 pageTD2 BiostatistiqueChawki MokademPas encore d'évaluation
- RésuméDocument2 pagesRésuméعبد اللهPas encore d'évaluation
- BiostatistiqueDocument6 pagesBiostatistiquemokermiPas encore d'évaluation
- Exercices Introductifs (Kachar Achraf)Document19 pagesExercices Introductifs (Kachar Achraf)Gabryel FotsoPas encore d'évaluation
- La Boîte MoustacheDocument2 pagesLa Boîte Moustacheanas el guerrabPas encore d'évaluation
- 7316 Corriges Finance2Document143 pages7316 Corriges Finance2osmar666Pas encore d'évaluation
- MSP - Carte de ControleDocument17 pagesMSP - Carte de ControleHayat Raoui100% (1)
- Devoir de Biostatistique M1Document10 pagesDevoir de Biostatistique M1Bernardin Marie MillogoPas encore d'évaluation
- BiostatistiqueDocument9 pagesBiostatistiqueRabehi DhoPas encore d'évaluation
- Cours StatistiqueDocument228 pagesCours StatistiquedevasicPas encore d'évaluation
- Corrigé Des Exercices 6 Et 7 - Série 01Document2 pagesCorrigé Des Exercices 6 Et 7 - Série 01Mellah ImadPas encore d'évaluation
- 19 StatistiqueDocument16 pages19 StatistiqueNahiPas encore d'évaluation
- SeriesTemp Cours2Document34 pagesSeriesTemp Cours2GOUAL SaraPas encore d'évaluation
- Sol Examen PST Aut 2017Document7 pagesSol Examen PST Aut 2017BRVZEPas encore d'évaluation
- Chapitre II - Statistique Descriptive À Un Caractère Ou Analyse Univariée (2e, 3e Et 4e Semaines)Document7 pagesChapitre II - Statistique Descriptive À Un Caractère Ou Analyse Univariée (2e, 3e Et 4e Semaines)edem fiademPas encore d'évaluation
- Statistiques - Paramètres de Position Et de DispersionDocument42 pagesStatistiques - Paramètres de Position Et de DispersionHamza HarrakPas encore d'évaluation
- Corriges2 2010Document21 pagesCorriges2 2010Ilhem de RennesPas encore d'évaluation