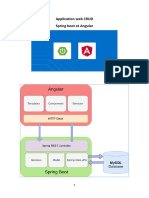
Vous aimerez peut-être aussi
- TP HadoopDocument11 pagesTP HadoopJas MinPas encore d'évaluation
- Master 2 Miage-Mbds Projet Big Data Analytics: Analyse de La Clientèle D'un Concessionnaire Automobile Pour La Recommandation de Modèles de VéhiculesDocument20 pagesMaster 2 Miage-Mbds Projet Big Data Analytics: Analyse de La Clientèle D'un Concessionnaire Automobile Pour La Recommandation de Modèles de VéhiculesAsilPas encore d'évaluation
- tp2 Designpatternsdanshadoop 140428050218 Phpapp02Document6 pagestp2 Designpatternsdanshadoop 140428050218 Phpapp02chebinegaPas encore d'évaluation
- tp2 Map ReduceDocument5 pagestp2 Map ReduceRaja BsPas encore d'évaluation
- EFM Création D'une Application Cloud Native Bahae Eddine HalimDocument7 pagesEFM Création D'une Application Cloud Native Bahae Eddine HalimSiham DLPas encore d'évaluation
- TP1 BigDataAnalytics Initiation HadoopDocument9 pagesTP1 BigDataAnalytics Initiation HadoopSouleyPas encore d'évaluation
- Hadoop 1Document61 pagesHadoop 1Mouhamed BouazziPas encore d'évaluation
- Examen Big DATADocument4 pagesExamen Big DATAzaki workerPas encore d'évaluation
- Lab 3Document15 pagesLab 3Maryâm BôuchPas encore d'évaluation
- tp4 - Framework - Struts 2Document5 pagestp4 - Framework - Struts 2halabimeryem89Pas encore d'évaluation
- ExpressTuto - DEV205-P1Document6 pagesExpressTuto - DEV205-P1Hamza ChaloutPas encore d'évaluation
- CBD TPDocument6 pagesCBD TPzemerPas encore d'évaluation
- Cours Spring FondamentauxDocument59 pagesCours Spring FondamentauxBaghdadi AbsPas encore d'évaluation
- React Redux Tutoriel 1Document9 pagesReact Redux Tutoriel 1hachemfstPas encore d'évaluation
- Openldap ServerDocument52 pagesOpenldap Serverichbin1199Pas encore d'évaluation
- Active DirectoryDocument5 pagesActive DirectoryAmunoxPas encore d'évaluation
- Chapitre3 NoSQL Avec RedisDocument44 pagesChapitre3 NoSQL Avec RedisGodni RodneyPas encore d'évaluation
- coursNodeJs PDFDocument66 pagescoursNodeJs PDFrodrigue ntchounkeuPas encore d'évaluation
- Introduction À Laravel - CoursDocument21 pagesIntroduction À Laravel - CoursJean marc KonanPas encore d'évaluation
- SujetEvaluation2017 CorrectionDocument5 pagesSujetEvaluation2017 CorrectionAbdo Elmamoun100% (4)
- TP1 Hadoop3.1.2Document20 pagesTP1 Hadoop3.1.2fatima ezzahrae el ghatousPas encore d'évaluation
- tp1 IRSDocument7 pagestp1 IRSZohra CHANNOUF100% (1)
- Projet PHPDocument13 pagesProjet PHPHoudadine AbdouPas encore d'évaluation
- Cours Big Data Avancee Chp2 Data-IngestionDocument46 pagesCours Big Data Avancee Chp2 Data-IngestionMarwenCherifPas encore d'évaluation
- Formation Node Expressjs 617c0eb091742Document41 pagesFormation Node Expressjs 617c0eb091742Adil KhalkiPas encore d'évaluation
- Supervision Avec NagiosDocument28 pagesSupervision Avec NagiosAli Amaniss67% (3)
- Mongo DBDocument13 pagesMongo DBZied ZinelabidinePas encore d'évaluation
- Cours AndroidDocument111 pagesCours AndroidAbdelhamid El GuartiPas encore d'évaluation
- TP N°2 - Exemple Word Count Avec HadoopDocument12 pagesTP N°2 - Exemple Word Count Avec HadoopinesPas encore d'évaluation
- NodejsDocument20 pagesNodejsMohamed El HaddadPas encore d'évaluation
- Tutorial Spring MVC Crud Jpa Hibernate PostgresqlDocument39 pagesTutorial Spring MVC Crud Jpa Hibernate Postgresqlneji jlassi100% (1)
- Mickaelbaron-Hadoopinstallation Part4Document2 pagesMickaelbaron-Hadoopinstallation Part4satmaniaPas encore d'évaluation
- Bootstrap AbdaliDocument49 pagesBootstrap AbdaliYoussefPas encore d'évaluation
- TP01 Installation de Hadoop Sous LinuxDocument10 pagesTP01 Installation de Hadoop Sous LinuxManal EssPas encore d'évaluation
- Atelier 1 - Projet Spring BootDocument10 pagesAtelier 1 - Projet Spring BootJouhaina NasriPas encore d'évaluation
- Compte Rendu TP 1 Big DataDocument6 pagesCompte Rendu TP 1 Big DataGaith BelkacemPas encore d'évaluation
- AM2020 1-CopierDocument4 pagesAM2020 1-CopierSia BoualemPas encore d'évaluation
- Atelier Framework Big Data PDFDocument21 pagesAtelier Framework Big Data PDFZohra CHANNOUFPas encore d'évaluation
- Spring Boot-2Document31 pagesSpring Boot-2Jouhaina NasriPas encore d'évaluation
- Récupérer Des Données Hadoop Avec Python - Makina CorpusDocument3 pagesRécupérer Des Données Hadoop Avec Python - Makina CorpusAhmed MohamedPas encore d'évaluation
- ScalaDocument33 pagesScalaZouhair NgPas encore d'évaluation
- TP1 Producing SOAP Web ServiceDocument10 pagesTP1 Producing SOAP Web Servicezineb elfadiliPas encore d'évaluation
- Tuto Spring JpaDocument17 pagesTuto Spring JpalangagecccPas encore d'évaluation
- TP4-5 SparkDocument21 pagesTP4-5 SparkMazozi safaePas encore d'évaluation
- TP ASP Net Core MVCDocument8 pagesTP ASP Net Core MVCBOUZAZIPas encore d'évaluation
- BigData2A TD3 4 Enonce - 2Document9 pagesBigData2A TD3 4 Enonce - 2Souhail Ben AfiaPas encore d'évaluation
- Tutorial Spring MVC Crud Spring Data PostgresqlDocument31 pagesTutorial Spring MVC Crud Spring Data Postgresqlneji jlassiPas encore d'évaluation
- PHP Ex Codeigniter4Document11 pagesPHP Ex Codeigniter4RaliteraTokyPas encore d'évaluation
- TP1-SOAP ServiceDocument8 pagesTP1-SOAP ServiceArbi BouhaddiPas encore d'évaluation
- Extensions Plugins QgisDocument12 pagesExtensions Plugins QgisHebray SébastienPas encore d'évaluation
- Spring MVC (PDFDrive)Document64 pagesSpring MVC (PDFDrive)world internetPas encore d'évaluation
- Hadoop EcosystemDocument37 pagesHadoop Ecosystemhajar.filali4Pas encore d'évaluation
- Fiche de TD INF 356Document21 pagesFiche de TD INF 356Sali Yaya FaraniPas encore d'évaluation
- 1.1 Prise en Main de L'émulateur: ChapitreDocument8 pages1.1 Prise en Main de L'émulateur: ChapitreMamadou Mouctar DialloPas encore d'évaluation
- Administration Et Hebergement WebDocument5 pagesAdministration Et Hebergement WebTagne Guylain FlorianPas encore d'évaluation
- Spring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplateD'EverandSpring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplatePas encore d'évaluation
- MAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsD'EverandMAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsPas encore d'évaluation
- Cours Tableau de BordDocument55 pagesCours Tableau de Bordnafissa bridah100% (1)
- Chapitre 2 - Les Collections de Données en PythonDocument61 pagesChapitre 2 - Les Collections de Données en Pythonnafissa bridahPas encore d'évaluation
- TD 1 ImpDocument4 pagesTD 1 Impnafissa bridahPas encore d'évaluation
- Les Graphiques Dans Power BIDocument3 pagesLes Graphiques Dans Power BInafissa bridahPas encore d'évaluation
- ExemplesDocument3 pagesExemplesnafissa bridahPas encore d'évaluation
- RévisionDocument7 pagesRévisionnafissa bridahPas encore d'évaluation
- AZUUUREDocument30 pagesAZUUUREnafissa bridahPas encore d'évaluation
- GDP 22 23 - L3 - CHAP2 - VFDocument70 pagesGDP 22 23 - L3 - CHAP2 - VFnafissa bridahPas encore d'évaluation
- Definition Couplage For Et Couplage LegerDocument2 pagesDefinition Couplage For Et Couplage Legernafissa bridahPas encore d'évaluation
- PFE Book 2023-2024: 12 Novembre 2023Document83 pagesPFE Book 2023-2024: 12 Novembre 2023nafissa bridahPas encore d'évaluation
- TD 2 ImpDocument4 pagesTD 2 Impnafissa bridahPas encore d'évaluation
- TD 1 ImpDocument4 pagesTD 1 Impnafissa bridahPas encore d'évaluation
- TD 6 ImpDocument5 pagesTD 6 Impnafissa bridahPas encore d'évaluation
- Les Processus Autorégressifs 12-12-2021 (Partie Finie)Document20 pagesLes Processus Autorégressifs 12-12-2021 (Partie Finie)nafissa bridah100% (1)
- TP 5Document25 pagesTP 5nafissa bridahPas encore d'évaluation
- Cours 02 Intro HadoopDocument30 pagesCours 02 Intro HadoopMichael Sniper WuPas encore d'évaluation
- TP3 Hadoop ExercicesDocument2 pagesTP3 Hadoop Exerciceskoyine9472Pas encore d'évaluation
- Hadoop TP MSBGDocument7 pagesHadoop TP MSBGzemerPas encore d'évaluation
- Big Data RésumeDocument1 pageBig Data RésumeOumaima EzafaPas encore d'évaluation
- Chap 1Document18 pagesChap 1Hakim FarhaniPas encore d'évaluation
- C01Document16 pagesC01Serigne NdourPas encore d'évaluation
- TP Map ReduceDocument3 pagesTP Map Reducefidaletaief58Pas encore d'évaluation
- Chapitre 2 Hadoop-Part2Document47 pagesChapitre 2 Hadoop-Part2souhail nahedPas encore d'évaluation
- Ch0 Big DataDocument21 pagesCh0 Big DataYounes Oulad SayadPas encore d'évaluation
- Ex Amen Big Data 1617Document6 pagesEx Amen Big Data 1617Med Nour Elhak JouiniPas encore d'évaluation
- BDA mongoDB PDFDocument80 pagesBDA mongoDB PDFHamdouch BachrPas encore d'évaluation
- Mbds Big Data Hadoop 2019 2020 TP 2Document11 pagesMbds Big Data Hadoop 2019 2020 TP 2Pevo JoPas encore d'évaluation
- Les Bases de Données Nosql: Pr. Soussi NassimaDocument112 pagesLes Bases de Données Nosql: Pr. Soussi NassimaSokaina ElharouriPas encore d'évaluation
- HadoopDocument25 pagesHadoopadjemi_brahim100% (2)
- tp1 MapreduceDocument15 pagestp1 MapreduceIvan003Pas encore d'évaluation
- Big Data Analytics Three Use Cases With R Python ADocument39 pagesBig Data Analytics Three Use Cases With R Python AMelek MaalejPas encore d'évaluation
- TP Map Reduce2Document4 pagesTP Map Reduce2mariemltifi61Pas encore d'évaluation
- Tpe Yarn-1Document11 pagesTpe Yarn-1Taka fidèlePas encore d'évaluation
- tp1 BigDataDocument9 pagestp1 BigDataHaitam LaaouiniPas encore d'évaluation
- Tpe-Inf-356 Modifié OKDocument17 pagesTpe-Inf-356 Modifié OKSeini MtkPas encore d'évaluation
- Chapitre 2 Final FRDocument94 pagesChapitre 2 Final FRÄya ĶhPas encore d'évaluation
- BigData Technologies AvancéesDocument81 pagesBigData Technologies Avancéesnihed attiaPas encore d'évaluation
- Chapitre 3 Mongo MapreduceDocument20 pagesChapitre 3 Mongo Mapreducesouhail nahedPas encore d'évaluation
- Big DataDocument11 pagesBig DataSalahPas encore d'évaluation
- Miniprojet BigDataDocument9 pagesMiniprojet BigDataghassen lassouedPas encore d'évaluation
- PFE Cloud Computing - Open StackDocument69 pagesPFE Cloud Computing - Open StackYoussef ameurPas encore d'évaluation
- 3 PDFDocument81 pages3 PDFKouakou N'coréPas encore d'évaluation
- CY3903 Formation Cloudera Essentials For Apache Hadoop PDFDocument1 pageCY3903 Formation Cloudera Essentials For Apache Hadoop PDFCertyouFormationPas encore d'évaluation
- Big DataDocument15 pagesBig DataNezha SoufiPas encore d'évaluation