Vous aimerez peut-être aussi
- k8s - KubernetesDocument20 pagesk8s - KubernetesIman khayatiPas encore d'évaluation
- 02 Differents Objets Composants KubernetesDocument8 pages02 Differents Objets Composants KubernetesChristian BibouePas encore d'évaluation
- Document1 5Document3 pagesDocument1 5Nour alhouda BenboubkerPas encore d'évaluation
- Plateforme DockerDocument7 pagesPlateforme DockeraminaPas encore d'évaluation
- Kubernetes For TeenagersDocument28 pagesKubernetes For TeenagersAntony Kervazo-CanutPas encore d'évaluation
- KUBERNETESDocument9 pagesKUBERNETESKingrone1Pas encore d'évaluation
- Devoir N°2 - ClusterDocument3 pagesDevoir N°2 - Clustermaliani adolphPas encore d'évaluation
- Cluster MultinoeudsDocument14 pagesCluster MultinoeudsinesPas encore d'évaluation
- TP Kub ManalDocument22 pagesTP Kub Manalissam hach63Pas encore d'évaluation
- Kubernetes FRDocument22 pagesKubernetes FRamel fajraouiPas encore d'évaluation
- Programme Kubernetes - Orchestrer Ses ConteneursDocument5 pagesProgramme Kubernetes - Orchestrer Ses ConteneursahmedwerchfaniPas encore d'évaluation
- CM KubernetesDocument55 pagesCM Kubernetesissam hach63Pas encore d'évaluation
- VM Et ContainersDocument22 pagesVM Et Containersnetsystems formationPas encore d'évaluation
- Achitecture Logicielle ModerneDocument29 pagesAchitecture Logicielle ModernePaul Zidane KEMTHOPas encore d'évaluation
- Kubernetes Et OpenshiftDocument3 pagesKubernetes Et OpenshiftmohamedPas encore d'évaluation
- Kubernetes Maîtrisez Lorchestrateur Des Infrastructures Du Futur - Kelsey Hightower - Brendan Burns EtDocument282 pagesKubernetes Maîtrisez Lorchestrateur Des Infrastructures Du Futur - Kelsey Hightower - Brendan Burns EtConstant Kefrane100% (1)
- Plan de Formation - Openshift - IIIDocument4 pagesPlan de Formation - Openshift - IIIkaralyhPas encore d'évaluation
- La Virtualisation Vs La ConteneurisationDocument15 pagesLa Virtualisation Vs La ConteneurisationJbir DoniaPas encore d'évaluation
- De La Conteneurisation À L'orchestration Avec KubernetesDocument37 pagesDe La Conteneurisation À L'orchestration Avec Kubernetesde-jacquesPas encore d'évaluation
- ConteneurisationDocument27 pagesConteneurisationlandryPas encore d'évaluation
- Kubernetes Certified Application DeveloperDocument56 pagesKubernetes Certified Application DeveloperDominique RoduitPas encore d'évaluation
- Assignement 3 2021f-MSE-001Document7 pagesAssignement 3 2021f-MSE-001Omar AkhlaqPas encore d'évaluation
- Mouanou Mitori Guichel Prosit6Document12 pagesMouanou Mitori Guichel Prosit6Guichel MouanouPas encore d'évaluation
- Pres OpenshiftDocument20 pagesPres OpenshiftEdgar Orlando Bermudez AljuriPas encore d'évaluation
- ApprendreKubernetes Ehandbook 2018Document46 pagesApprendreKubernetes Ehandbook 2018papa babacar DiagnePas encore d'évaluation
- Docker IntroDocument32 pagesDocker IntroIman khayatiPas encore d'évaluation
- Lecture2 Conteneurisation V3.0 4p1Document13 pagesLecture2 Conteneurisation V3.0 4p1Ahmed SassiPas encore d'évaluation
- MAJ Chapitre2 ConteneurisationDocument26 pagesMAJ Chapitre2 ConteneurisationJbali HelaPas encore d'évaluation
- Kubernetes FrancaisDocument142 pagesKubernetes FrancaisruroniPas encore d'évaluation
- Introduction Aux Outils DevOpsDocument115 pagesIntroduction Aux Outils DevOpsManar FERMASPas encore d'évaluation
- TP - Getting Started With KubernetesDocument14 pagesTP - Getting Started With KubernetesZineb ErrajiPas encore d'évaluation
- Résumé Docker 090949Document4 pagesRésumé Docker 090949Aya GramiPas encore d'évaluation
- DockerDocument3 pagesDockermimomaro777Pas encore d'évaluation
- Lab 1 MinikubeDocument7 pagesLab 1 MinikubeZizoAzizPas encore d'évaluation
- 03 Minikube Installation Manipulation Cluster KubernetesDocument10 pages03 Minikube Installation Manipulation Cluster KubernetesChristian BibouePas encore d'évaluation
- LAB1Document11 pagesLAB1Jbir DoniaPas encore d'évaluation
- Interview Ques and Ans - 30Document11 pagesInterview Ques and Ans - 30shrinivasanPas encore d'évaluation
- Ri3 k8s 101Document51 pagesRi3 k8s 101Ahcene Aiti100% (1)
- K8S Seance01 Installation Single Cluster Node Via MinikubeDocument11 pagesK8S Seance01 Installation Single Cluster Node Via Minikubekem ITPas encore d'évaluation
- Complément VirtualisationDocument6 pagesComplément Virtualisationmagep92240Pas encore d'évaluation
- TP2 Virtualisation DockerDocument10 pagesTP2 Virtualisation DockerFarah Hkiri100% (1)
- KVM Et ClusterDocument24 pagesKVM Et Clusterhedil zbidiPas encore d'évaluation
- IN2P3 Intro ConteneursDocument48 pagesIN2P3 Intro Conteneursfati.zahra7778Pas encore d'évaluation
- Distribution RehHat D'openstackDocument44 pagesDistribution RehHat D'openstackDali HadrichePas encore d'évaluation
- 4 Docker Kubernetes PDFDocument36 pages4 Docker Kubernetes PDF4qc5hn9tbbPas encore d'évaluation
- Virtualisation Mise A JourDocument30 pagesVirtualisation Mise A Joursarrfallou267Pas encore d'évaluation
- ConteunerisationDocument41 pagesConteunerisationjohndavisambassaPas encore d'évaluation
- Questionnaire Devops V1Document2 pagesQuestionnaire Devops V1Kingrone1Pas encore d'évaluation
- Docker - Tout Savoir Sur La Plateforme de ContainérisationDocument34 pagesDocker - Tout Savoir Sur La Plateforme de Containérisationmoisendiaye245Pas encore d'évaluation
- TP: Fonctionnalités Avancées D'ansible: P. MartiniDocument38 pagesTP: Fonctionnalités Avancées D'ansible: P. MartiniAnge StephenPas encore d'évaluation
- KubernetesDocument13 pagesKubernetesHAMDI GDHAMIPas encore d'évaluation
- Kubernetes TP de Prises en MainDocument20 pagesKubernetes TP de Prises en MainAbdallah SAAD SAOUDPas encore d'évaluation
- Plan de Formation - Openshift - IIDocument4 pagesPlan de Formation - Openshift - IIkaralyhPas encore d'évaluation
- Sysadm Base 1Document45 pagesSysadm Base 1KAMAYUMBI PHILEMONPas encore d'évaluation
- Pfe Rafif1Document19 pagesPfe Rafif1rafifrafif825Pas encore d'évaluation
- 01 Cours Complet Apprendre Orchestrateur Kubernetes k8sDocument6 pages01 Cours Complet Apprendre Orchestrateur Kubernetes k8sChristian BibouePas encore d'évaluation
- DockerDocument8 pagesDockerNicoletta NouetagniPas encore d'évaluation
- Annexe 1 Fiche Descriptive Formation OpenstackDocument6 pagesAnnexe 1 Fiche Descriptive Formation OpenstackHouda Sidi AmmiPas encore d'évaluation
- Maîtriser PowerShell: Guide Complet: La collection informatiqueD'EverandMaîtriser PowerShell: Guide Complet: La collection informatiquePas encore d'évaluation
- Spring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplateD'EverandSpring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplatePas encore d'évaluation
- Ingress TraefikDocument2 pagesIngress TraefikAbdallah SAAD SAOUDPas encore d'évaluation
- StickerMR 89078622Document1 pageStickerMR 89078622Abdallah SAAD SAOUDPas encore d'évaluation
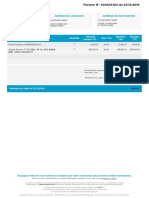
- Facture Reservation HotelDocument1 pageFacture Reservation HotelAbdallah SAAD SAOUDPas encore d'évaluation
- RKE2 - Mise en PlaceDocument4 pagesRKE2 - Mise en PlaceAbdallah SAAD SAOUDPas encore d'évaluation
- Facture ORANGE Christophe QUIQUET1 PDFDocument2 pagesFacture ORANGE Christophe QUIQUET1 PDFAbdallah SAAD SAOUDPas encore d'évaluation
- CA Attestation Multirisque HabitationDocument10 pagesCA Attestation Multirisque HabitationAbdallah SAAD SAOUDPas encore d'évaluation
- Facture Orange 2Document1 pageFacture Orange 2Yann HajjiPas encore d'évaluation
- AttestationDroits 1Document2 pagesAttestationDroits 1Abdallah SAAD SAOUDPas encore d'évaluation
- Invoice: Apple Distribution InternationalDocument1 pageInvoice: Apple Distribution Internationalmary_chapenPas encore d'évaluation
- Facture BoulangerDocument3 pagesFacture BoulangerAbdallah SAAD SAOUDPas encore d'évaluation
- 20220528-StickerMR-89095831 Dyson7Document1 page20220528-StickerMR-89095831 Dyson7Abdallah SAAD SAOUDPas encore d'évaluation
- File BackupDocument2 pagesFile BackupAbdallah SAAD SAOUD100% (1)
- 20220527-StickerMR-89085227 Dyson V10Document1 page20220527-StickerMR-89085227 Dyson V10Abdallah SAAD SAOUDPas encore d'évaluation
- PCR YanisDocument2 pagesPCR YanisAbdallah SAAD SAOUDPas encore d'évaluation
- Facture - Bouygues Iphone 11 Pro Max SG 64gbDocument1 pageFacture - Bouygues Iphone 11 Pro Max SG 64gbAbdallah SAAD SAOUD100% (1)
- Facture Boulanger 3Document3 pagesFacture Boulanger 3Abdallah SAAD SAOUDPas encore d'évaluation
- Facture Boulanger Iphone 13 Pro Max Silver 128GBDocument3 pagesFacture Boulanger Iphone 13 Pro Max Silver 128GBAbdallah SAAD SAOUDPas encore d'évaluation
- SFR - IPHONE 11 BLANC 128GB - 2Document1 pageSFR - IPHONE 11 BLANC 128GB - 2Abdallah SAAD SAOUD100% (2)
- Facture Fnac IPADDocument1 pageFacture Fnac IPADAbdallah SAAD SAOUD67% (3)
- Facture Apple Watch FnacDocument1 pageFacture Apple Watch FnacAbdallah SAAD SAOUDPas encore d'évaluation
- Facture - Bouygues IPHONE 12 BLUE 128GBDocument1 pageFacture - Bouygues IPHONE 12 BLUE 128GBAbdallah SAAD SAOUD100% (6)
- PCR - Djabou SamirDocument2 pagesPCR - Djabou SamirAbdallah SAAD SAOUDPas encore d'évaluation
- Facture-Darty - IpadDocument1 pageFacture-Darty - IpadAbdallah SAAD SAOUDPas encore d'évaluation
- Facture Fnac MacBook ProDocument1 pageFacture Fnac MacBook ProAbdallah SAAD SAOUDPas encore d'évaluation
- Cours 3eme 2021 - 2022 - Élève - Partie9 - Interfaces GraphiquesDocument8 pagesCours 3eme 2021 - 2022 - Élève - Partie9 - Interfaces GraphiquesGlaine Kaputo Amada67% (3)
- TP N1 Sec OSDocument4 pagesTP N1 Sec OSSalim AssalamPas encore d'évaluation
- b2 JPF ExempleDocument10 pagesb2 JPF ExempleMILK CHEAKPas encore d'évaluation
- Cours 10Document4 pagesCours 10Chayma bmaPas encore d'évaluation
- M1607 - Secrétariat Riasec: CS: AppellationsDocument4 pagesM1607 - Secrétariat Riasec: CS: AppellationsOceane LopeezPas encore d'évaluation
- Fiches Techniques PDFDocument9 pagesFiches Techniques PDFBrahim MidounePas encore d'évaluation
- Télécharger Méthode Lafay PDF GratuitDocument4 pagesTélécharger Méthode Lafay PDF GratuitneqejucPas encore d'évaluation
- Cours - Les Donnees NumeriquesDocument4 pagesCours - Les Donnees NumeriquesNejib JallouliPas encore d'évaluation
- Accés Aux Ressources DisqueDocument44 pagesAccés Aux Ressources DisqueMoustapha SanoussiPas encore d'évaluation
- TP9 SQLDocument9 pagesTP9 SQLamine HouafPas encore d'évaluation
- Enset Mohammedia: - FormationsDocument2 pagesEnset Mohammedia: - FormationsayatPas encore d'évaluation
- Comment Briser La Glace Sur Tinder PDFDocument40 pagesComment Briser La Glace Sur Tinder PDFKarim KhelifiPas encore d'évaluation
- S4GC5GestionSporadicite LTEV2 VPOLY2sur1LIGHTDocument24 pagesS4GC5GestionSporadicite LTEV2 VPOLY2sur1LIGHTPacome ChedePas encore d'évaluation
- Sujet E2 Metropole Bac Pro Melec Juin 2023Document11 pagesSujet E2 Metropole Bac Pro Melec Juin 2023kateb.documentsPas encore d'évaluation
- Manual Delta 2200-3000 - En-Es-FrDocument18 pagesManual Delta 2200-3000 - En-Es-FrKrustytfePas encore d'évaluation
- 01GLIntro 1Document52 pages01GLIntro 1Seini MtkPas encore d'évaluation
- Rapport Financier Annuel - 29042021 - MicrodataDocument66 pagesRapport Financier Annuel - 29042021 - MicrodataifePas encore d'évaluation
- Devoir 2 Modele 1 Informatique Tronc Commun Semestre 1Document2 pagesDevoir 2 Modele 1 Informatique Tronc Commun Semestre 1ZAHRA FASKAPas encore d'évaluation
- Lycee Classique D'Edea: Minesec 03.10.2017 EXAMEN Sequence #1 Durée: 3h Classe: C Coeff. 5 Epreuve MathematiquesDocument2 pagesLycee Classique D'Edea: Minesec 03.10.2017 EXAMEN Sequence #1 Durée: 3h Classe: C Coeff. 5 Epreuve MathematiquesSanz GuéPas encore d'évaluation
- RSX102 Juin 2010-CfinalDocument9 pagesRSX102 Juin 2010-Cfinalbenabdallahm8205Pas encore d'évaluation
- Main 1Document54 pagesMain 1Nejwa ParadPas encore d'évaluation
- PHP-PDO 27mars2019 (Abdelwahed)Document16 pagesPHP-PDO 27mars2019 (Abdelwahed)Morad EL MASLOUHYPas encore d'évaluation
- Un TéléphoneDocument2 pagesUn Téléphonegeorge yeboahPas encore d'évaluation
- TP DNS PersonnaliseDocument7 pagesTP DNS PersonnaliseAbdoul Djalil MahamadouPas encore d'évaluation
- Chap 7 ArchiDocument39 pagesChap 7 ArchiTh'real TFPas encore d'évaluation
- Utilisation de Lex Dans Le Processus de CompilationDocument6 pagesUtilisation de Lex Dans Le Processus de CompilationDARIL RAOUL KENGNE WAMBO100% (1)
- La Virtualisation SousDocument131 pagesLa Virtualisation SousFarid40Pas encore d'évaluation
- TP5-Routage Statique (To Do)Document9 pagesTP5-Routage Statique (To Do)Firas AbdallahPas encore d'évaluation
- Thierry Vaira PDFDocument115 pagesThierry Vaira PDFZineddine El Mehdi MustaphaPas encore d'évaluation
- RIL Belazzoug Chap2Document15 pagesRIL Belazzoug Chap2younesmohammedamine.ksouriPas encore d'évaluation