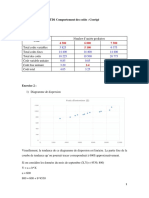
Vous aimerez peut-être aussi
- TD Maint+CorrigeDocument7 pagesTD Maint+CorrigeElmadani Beghdaoui100% (4)
- Ch4 Analyse Factorielle Des Correspondances (AFC)Document42 pagesCh4 Analyse Factorielle Des Correspondances (AFC)Abubakr Sidik86% (7)
- Cours ACMDocument51 pagesCours ACMrhariss97100% (1)
- ACPDocument5 pagesACPladytimaPas encore d'évaluation
- Analyse de DonneesDocument44 pagesAnalyse de DonneesAnta Mbaye100% (2)
- Approximation Au Sens Des Moindres Carrés (MANI YOUSSEF Et KRIT RIDA)Document52 pagesApproximation Au Sens Des Moindres Carrés (MANI YOUSSEF Et KRIT RIDA)RIDA KRITPas encore d'évaluation
- AcpDocument20 pagesAcpKarim Karim100% (1)
- Chapitre I Anlyse en Composantes PrincipalesDocument20 pagesChapitre I Anlyse en Composantes PrincipalesAsma Satouri100% (1)
- Analyse en Composantes Principales A.C.PDocument17 pagesAnalyse en Composantes Principales A.C.PHassnaa LoulouPas encore d'évaluation
- Chapitre ACPDocument5 pagesChapitre ACPBird000Pas encore d'évaluation
- Acp CoursDocument18 pagesAcp CoursMohamedLahouaouiPas encore d'évaluation
- Analyse Des Correspondances Multiples-2012-2 Cle838d4fDocument33 pagesAnalyse Des Correspondances Multiples-2012-2 Cle838d4framondz1100% (2)
- PrésentationDocument27 pagesPrésentationOussama McPas encore d'évaluation
- Cours ACPDocument29 pagesCours ACPtristan_raoultPas encore d'évaluation
- La Première PartieDocument22 pagesLa Première PartieAthmane BenfattoumPas encore d'évaluation
- Session 1: Principes de L'analyse Factorielle en Composantes PrincipalesDocument13 pagesSession 1: Principes de L'analyse Factorielle en Composantes PrincipalesSanders100% (1)
- Acp Sous SPSSDocument60 pagesAcp Sous SPSSOuakrim YounesPas encore d'évaluation
- Analyse en Composante Principal de Series Non Stationnaire PDFDocument14 pagesAnalyse en Composante Principal de Series Non Stationnaire PDFmeone99Pas encore d'évaluation
- Ilide - Info Chapitre Acp PRDocument5 pagesIlide - Info Chapitre Acp PRAkkiPas encore d'évaluation
- Statistiques Et Probabilité: Par Stéphane C. K. TEKOUABOU (P.H.D & Ing.) Département: AnnéeDocument63 pagesStatistiques Et Probabilité: Par Stéphane C. K. TEKOUABOU (P.H.D & Ing.) Département: AnnéeHermann FotsoPas encore d'évaluation
- Analyse en Composantes Principales - WikipédiaDocument75 pagesAnalyse en Composantes Principales - WikipédiaIssaka Soumana BoubacarPas encore d'évaluation
- Analyse FactorielleDocument58 pagesAnalyse FactorielleÖuma ImaPas encore d'évaluation
- AcpDocument10 pagesAcpThinhinane GuedriPas encore d'évaluation
- Analyse de Donnees - StatistiqueDocument6 pagesAnalyse de Donnees - Statistiquebr18Pas encore d'évaluation
- Analyse en Composantes Principales - Résumé (Tchi Drive)Document5 pagesAnalyse en Composantes Principales - Résumé (Tchi Drive)chihebabir1992Pas encore d'évaluation
- AcpDocument5 pagesAcphaindhaindPas encore d'évaluation
- Analyse en Composante Principale (ACP) (S1)Document13 pagesAnalyse en Composante Principale (ACP) (S1)Karima JaffaliPas encore d'évaluation
- FactorAnalysisCoresp SiaghARiDocument25 pagesFactorAnalysisCoresp SiaghARianfal JijPas encore d'évaluation
- Chapitre3-ACF - 2023Document33 pagesChapitre3-ACF - 2023yosraghanmi23Pas encore d'évaluation
- Cours - ACP ORI OAI PDFDocument3 pagesCours - ACP ORI OAI PDFHamza El JemliPas encore d'évaluation
- Ch1 Tableaux de Données MultidimensionnellesDocument17 pagesCh1 Tableaux de Données MultidimensionnellesAbubakr SidikPas encore d'évaluation
- Lassse9 Analyse de Données ACP 23Document35 pagesLassse9 Analyse de Données ACP 23Ikram ChtrPas encore d'évaluation
- Ch3 Analyse Factorielle en Composantes PrincipalesDocument45 pagesCh3 Analyse Factorielle en Composantes PrincipalesAbubakr SidikPas encore d'évaluation
- Interprétaion D'une ACP Par ALAOUIIIIIDocument4 pagesInterprétaion D'une ACP Par ALAOUIIIIIMourad DaoudiPas encore d'évaluation
- Analyse Factorielle de Correspondances SimpleDocument11 pagesAnalyse Factorielle de Correspondances SimpleSalmaElPas encore d'évaluation
- Act. 2/ Sem. 2: Analyse Et Fouille de Données - Jérôme BOSCHE - UPJV - FranceDocument2 pagesAct. 2/ Sem. 2: Analyse Et Fouille de Données - Jérôme BOSCHE - UPJV - FranceAntoine SodoPas encore d'évaluation
- Chap II RegressionDocument53 pagesChap II RegressionmoudouPas encore d'évaluation
- Analyse en Composantes Principales - WikipédiaDocument69 pagesAnalyse en Composantes Principales - Wikipédiadjema fatihaPas encore d'évaluation
- Interprétations ADDDocument3 pagesInterprétations ADDDías VictoriaPas encore d'évaluation
- FR Tanagra AFDMDocument13 pagesFR Tanagra AFDMKasaPas encore d'évaluation
- 6227 15589 1 SMDocument8 pages6227 15589 1 SMHasna IBKHCHACHEPas encore d'évaluation
- Classification Ascendante HiérarchiqueDocument6 pagesClassification Ascendante HiérarchiqueParfait AhohoundoPas encore d'évaluation
- Section 4 Analyse Factorielle Des CorrespondancesDocument4 pagesSection 4 Analyse Factorielle Des CorrespondancesALLAL ZAHIRPas encore d'évaluation
- Synthèse AFCDocument2 pagesSynthèse AFCanas el guerrabPas encore d'évaluation
- Khi DeuxDocument3 pagesKhi DeuxmohakyoPas encore d'évaluation
- Analyses en Composantes PrincipalesDocument6 pagesAnalyses en Composantes PrincipalesKhaoula El BoukhariPas encore d'évaluation
- TPE DAS Groupe2Document21 pagesTPE DAS Groupe2DJELASSEM CYRILLEPas encore d'évaluation
- Travaux Pratique SUR SPSSDocument8 pagesTravaux Pratique SUR SPSSAnoir NegroPas encore d'évaluation
- Cours D'econometrie Licence 3Document67 pagesCours D'econometrie Licence 3Guillaume KOUASSI100% (1)
- Régression Linéaire Simple Avec R Et R CommanderDocument22 pagesRégression Linéaire Simple Avec R Et R CommanderRim AbouttiPas encore d'évaluation
- Correction de Série 1Document21 pagesCorrection de Série 1Abdelali Chaouchaou100% (1)
- Résumé AcpDocument35 pagesRésumé AcpmayaPas encore d'évaluation
- TADD Chapitre1 RégressionDocument15 pagesTADD Chapitre1 RégressionSaide MOHAMEDPas encore d'évaluation
- Application de L'analyse en Composantes Principales ACP : Préparé Par: Encadrée ParDocument5 pagesApplication de L'analyse en Composantes Principales ACP : Préparé Par: Encadrée ParNouha AlaePas encore d'évaluation
- ASDchap1 LicDocument13 pagesASDchap1 LicHafsa zianiPas encore d'évaluation
- CHAP1 - ACP Mni3i PDFDocument26 pagesCHAP1 - ACP Mni3i PDFMouhcine Zianee100% (1)
- Chapitre2 Regression Lineaire MultipleDocument3 pagesChapitre2 Regression Lineaire MultipleZakaria Ghrissi alouiPas encore d'évaluation
- Methodes Mathematiques Pour IngenieurDocument433 pagesMethodes Mathematiques Pour IngenieurJoël Mètogbé Zinsalo100% (1)
- Régression MutilinéaireDocument16 pagesRégression MutilinéaireLebossePas encore d'évaluation
- Taxation-carbone-difficile-a-manierDocument15 pagesTaxation-carbone-difficile-a-manierNour ElhoudaPas encore d'évaluation
- retour sur cheque vert - CopieDocument9 pagesretour sur cheque vert - CopieNour ElhoudaPas encore d'évaluation
- chap8 introduction a l optimisation dynamiqueDocument37 pageschap8 introduction a l optimisation dynamiqueNour Elhouda100% (1)
- Exposee MacrO 2Document21 pagesExposee MacrO 2Nour ElhoudaPas encore d'évaluation
- fonctionementDocument35 pagesfonctionementNour ElhoudaPas encore d'évaluation
- Les Determinants de L'inflationDocument11 pagesLes Determinants de L'inflationNour ElhoudaPas encore d'évaluation
- Chapitre 7Document7 pagesChapitre 7Nour ElhoudaPas encore d'évaluation
- Chapitre 8Document19 pagesChapitre 8Nour ElhoudaPas encore d'évaluation
- Techniques D'enquêtes Et Analyse Des Données (Master Économie de L'envirennement)Document140 pagesTechniques D'enquêtes Et Analyse Des Données (Master Économie de L'envirennement)Nour ElhoudaPas encore d'évaluation
- Master Sciences Économiques Cours Économie MarocaineDocument88 pagesMaster Sciences Économiques Cours Économie MarocaineNour ElhoudaPas encore d'évaluation
- Optimum de Pareto Et Equilibre Concurrentiel GeneralDocument29 pagesOptimum de Pareto Et Equilibre Concurrentiel GeneralNour ElhoudaPas encore d'évaluation
- Révision Et Correction Concours Volet Comptabilité GénéraleDocument5 pagesRévision Et Correction Concours Volet Comptabilité GénéraleNour ElhoudaPas encore d'évaluation
- Cours Séance 2 ÉconométrieDocument48 pagesCours Séance 2 ÉconométrieyoussefPas encore d'évaluation
- Exemple D'application D'un Modèle ARCHDocument8 pagesExemple D'application D'un Modèle ARCHabderrahmani faresPas encore d'évaluation
- Travail À FaireDocument11 pagesTravail À FaireMalika HartPas encore d'évaluation
- TD1 2021 CorrectionDocument3 pagesTD1 2021 CorrectionAnas100% (1)
- Apprentissage 1516 LassoDocument46 pagesApprentissage 1516 LassoLAZARREPas encore d'évaluation
- Mat Sta 07-20Document78 pagesMat Sta 07-20Mohamed EL hadegPas encore d'évaluation
- Chapitre 2 - Statistique Descriptive À Deux DimensionsDocument40 pagesChapitre 2 - Statistique Descriptive À Deux DimensionsMalika IzidPas encore d'évaluation
- Demarche EconometriqueDocument15 pagesDemarche Econometriquealla jean wilfried kouaméPas encore d'évaluation
- Corrigé Serie 3Document12 pagesCorrigé Serie 3Ayyoub DriouechPas encore d'évaluation
- QCM Feuille1 SolutionDocument2 pagesQCM Feuille1 SolutionMike BurdickPas encore d'évaluation
- TDM3 - SPSS-2021...Document9 pagesTDM3 - SPSS-2021...Mohamed BellgnachPas encore d'évaluation
- Econometrie TD 5 Sujet RegressionDocument6 pagesEconometrie TD 5 Sujet RegressionLebel Oved NdoukaPas encore d'évaluation
- ,SDVDocument4 pages,SDVRabie BattachPas encore d'évaluation
- Analyse de La VarianceDocument17 pagesAnalyse de La VarianceHammouch AyoubPas encore d'évaluation
- TP 1. Introduction Au Logiciel SAS Analyse Statistique Univari EeDocument6 pagesTP 1. Introduction Au Logiciel SAS Analyse Statistique Univari EeEzechiel AssoviePas encore d'évaluation
- Corrigés TD4 2022Document15 pagesCorrigés TD4 2022elhayyanyjaabakPas encore d'évaluation
- Exam EnsDocument77 pagesExam EnsMohamed BekhtiPas encore d'évaluation
- EXO Chapitre 3Document6 pagesEXO Chapitre 3abdelwahabPas encore d'évaluation
- Solution de La Série 2 TQADocument4 pagesSolution de La Série 2 TQAHadia HamzaPas encore d'évaluation
- TPplateforme SolutionDocument29 pagesTPplateforme SolutionKarim TamerdPas encore d'évaluation
- TD 2Document2 pagesTD 2Ninine0% (1)
- Statistique TH Eorique Et Appliqu EE: Tome 2 Inf Erence Statistique 'A Une Et 'A Deux Dimensions Pierre DagnelieDocument7 pagesStatistique TH Eorique Et Appliqu EE: Tome 2 Inf Erence Statistique 'A Une Et 'A Deux Dimensions Pierre Dagneliearthur EbaPas encore d'évaluation
- Corrige ExamenDocument5 pagesCorrige ExamenNajwa ElmfeddaliPas encore d'évaluation
- Statistique Descriptive Examen Blanc 2021Document2 pagesStatistique Descriptive Examen Blanc 2021mohamed bouyrhadPas encore d'évaluation
- Analyse de Données: Année Universitaire 2021-2022Document21 pagesAnalyse de Données: Année Universitaire 2021-2022Mouna RedissiPas encore d'évaluation
- Syllabus de Théorie: Techniques Quantitatives Paramétriques Et Non ParamétriquesDocument133 pagesSyllabus de Théorie: Techniques Quantitatives Paramétriques Et Non ParamétriquesVicky PetrosinoPas encore d'évaluation
- Cours Analyse de Données - Chapitre 1-1Document42 pagesCours Analyse de Données - Chapitre 1-1YoussefPas encore d'évaluation
- Analyse Des Correspondances Multiples-2012-2 Cle838d4fDocument33 pagesAnalyse Des Correspondances Multiples-2012-2 Cle838d4framondz1100% (2)
- 8 RegressionDocument32 pages8 RegressionHamza BoulikaPas encore d'évaluation