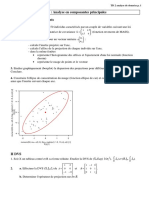
Vous aimerez peut-être aussi
- Analyse FactorielleDocument15 pagesAnalyse Factoriellekistidi33Pas encore d'évaluation
- CHAP1 - ACP Mni3i PDFDocument26 pagesCHAP1 - ACP Mni3i PDFMouhcine Zianee100% (1)
- Master - Exercices Corrigés CMDocument14 pagesMaster - Exercices Corrigés CMYOUSSEF SIYAHPas encore d'évaluation
- Technique D'analyse Multidimensionnelle Des DonneesDocument114 pagesTechnique D'analyse Multidimensionnelle Des DonneesKhaled AmriPas encore d'évaluation
- Exo 2Document7 pagesExo 2Amandine GbayePas encore d'évaluation
- TD 1 2019-2020Document2 pagesTD 1 2019-2020biz nryoo100% (1)
- Series Tempo-8 PDFDocument15 pagesSeries Tempo-8 PDFMar YoumaPas encore d'évaluation
- Introduction Analyse MultidimensionnelleDocument5 pagesIntroduction Analyse MultidimensionnelleAsma SatouriPas encore d'évaluation
- CopulesDocument8 pagesCopulesDaouda CamaraPas encore d'évaluation
- TD 2 PDFDocument13 pagesTD 2 PDFfayssal0% (1)
- AcpDocument26 pagesAcpAmine RakichiPas encore d'évaluation
- Correctionmai2005 PDFDocument4 pagesCorrectionmai2005 PDFMed Amine Talhaoui100% (1)
- CoursSeriesTemp Chap1Document58 pagesCoursSeriesTemp Chap1fouadPas encore d'évaluation
- C - Repère Les Exercices Dont Un Corrigé Est en Ligne. Menu - Risque D Un Portefeuille (Chapitre 10)Document66 pagesC - Repère Les Exercices Dont Un Corrigé Est en Ligne. Menu - Risque D Un Portefeuille (Chapitre 10)Musenge Samson TayaliPas encore d'évaluation
- DéterminantDocument2 pagesDéterminantKhalil FatiPas encore d'évaluation
- Chapitre 3 AFCDocument25 pagesChapitre 3 AFCFeriel HdhiliPas encore d'évaluation
- TD 2Document5 pagesTD 2titoPas encore d'évaluation
- TP1Document3 pagesTP1Chatiri AzizPas encore d'évaluation
- TestsHypStatL3Mass1516 ExamDocument19 pagesTestsHypStatL3Mass1516 ExamMETAHRI DhiyaeddinePas encore d'évaluation
- TD Cours3 PDFDocument4 pagesTD Cours3 PDFMohamedPas encore d'évaluation
- Sondage StratifiéDocument70 pagesSondage StratifiéousmanePas encore d'évaluation
- Scoring CorrectionsDocument32 pagesScoring CorrectionsMarie Vierge Meli JoundaPas encore d'évaluation
- 7B Cooperatifs Coeur ArticleDocument8 pages7B Cooperatifs Coeur ArticleAbdel ES-SameryPas encore d'évaluation
- Chapitre III - Analyse Des DonnéesDocument14 pagesChapitre III - Analyse Des Donnéesسهى نداريPas encore d'évaluation
- AfcDocument16 pagesAfcKarimaPas encore d'évaluation
- Methodes Reduction VarianceDocument78 pagesMethodes Reduction VariancejujumdrPas encore d'évaluation
- Cours de Sondages Master Is 2011-2012 (PDFDrive)Document234 pagesCours de Sondages Master Is 2011-2012 (PDFDrive)Lucien Mounpain100% (1)
- Fiche de TD 2: Méthodes de Sondage Exercice 1Document2 pagesFiche de TD 2: Méthodes de Sondage Exercice 1Zeidan JiddouPas encore d'évaluation
- Exercice ACPDocument5 pagesExercice ACPAchraf DahechPas encore d'évaluation
- correctionTD2 PDFDocument3 pagescorrectionTD2 PDFwikokkkPas encore d'évaluation
- Regression Logistique Polytomique PDFDocument23 pagesRegression Logistique Polytomique PDFdeyPas encore d'évaluation
- Slides Chap4c Cooperatifs Shapley ArticleDocument8 pagesSlides Chap4c Cooperatifs Shapley Articleham MacuisinePas encore d'évaluation
- Théorie Des JeuxDocument7 pagesThéorie Des Jeuxالفتى المتواضعPas encore d'évaluation
- Resume AfcDocument4 pagesResume AfcAbdallahi SidiPas encore d'évaluation
- Solutions Des Exercices Chapitre EstimationsDocument18 pagesSolutions Des Exercices Chapitre EstimationsSimo MnhPas encore d'évaluation
- td5 CorDocument5 pagestd5 CorwalidPas encore d'évaluation
- Travaux Dirig Es: Mod' Eles de Dur Ee S Eance N 2 Du 30 Novembre 2015 - Corrig eDocument8 pagesTravaux Dirig Es: Mod' Eles de Dur Ee S Eance N 2 Du 30 Novembre 2015 - Corrig eEric DassiePas encore d'évaluation
- Présentation - AFC RéctifiéeDocument60 pagesPrésentation - AFC Réctifiéesalmael372Pas encore d'évaluation
- Cours AFCDocument27 pagesCours AFCBenaissa LinaPas encore d'évaluation
- Cours de Stat InferentiellesDocument65 pagesCours de Stat InferentiellesDuy An100% (1)
- Naive Bayes ClassifierDocument35 pagesNaive Bayes ClassifiershimunoPas encore d'évaluation
- Corrigé Serie 3Document12 pagesCorrigé Serie 3Ayyoub DriouechPas encore d'évaluation
- Data Mining tp.5 Régression Linéaire MultipleDocument13 pagesData Mining tp.5 Régression Linéaire MultipleHoussayen Ben OuhibaPas encore d'évaluation
- Corrige Complexité PDFDocument5 pagesCorrige Complexité PDFMOUNIR HLALIPas encore d'évaluation
- Analyse de Donnees Joli Cours PDFDocument42 pagesAnalyse de Donnees Joli Cours PDFelioune100% (1)
- Analyse MultidimensionnelleDocument157 pagesAnalyse MultidimensionnelleEden Sam IndexPas encore d'évaluation
- Analyse de Données - Cours IntroductifDocument35 pagesAnalyse de Données - Cours IntroductifetdalechekhabPas encore d'évaluation
- Corrigé Exercice P.56, N 2Document6 pagesCorrigé Exercice P.56, N 2راجية الفردوسPas encore d'évaluation
- Chapitre 2 L'Analyse en Composantes Principales (ACP)Document15 pagesChapitre 2 L'Analyse en Composantes Principales (ACP)ceiizPas encore d'évaluation
- Cours Analyse de DonneesDocument144 pagesCours Analyse de DonneesOMAR0% (1)
- Regression Multiple Annexes18-02-2007 PDFDocument83 pagesRegression Multiple Annexes18-02-2007 PDFJbm KanyindaPas encore d'évaluation
- Exe Cor RLSDocument11 pagesExe Cor RLSAhlam ElabbadiPas encore d'évaluation
- Fac FacpDocument3 pagesFac FacpZineb Kanche100% (1)
- Exam Master 1213Document2 pagesExam Master 1213stevy darelPas encore d'évaluation
- CoursDocument44 pagesCoursSouhaila DjaffalPas encore d'évaluation
- Analysesmultivariées ACPDocument95 pagesAnalysesmultivariées ACPRomane LahillePas encore d'évaluation
- Corrigé de Examen ACPDocument4 pagesCorrigé de Examen ACPAbdallahi SidiPas encore d'évaluation
- Mathématiques Pour L'assurance: Travaux Dirigés 1 Théorie Du RisqueDocument3 pagesMathématiques Pour L'assurance: Travaux Dirigés 1 Théorie Du RisquesoftPas encore d'évaluation
- RAPPORT La Conduite Du Changement Au Sein D Une EntrepriseDocument66 pagesRAPPORT La Conduite Du Changement Au Sein D Une EntrepriseAsma SatouriPas encore d'évaluation
- Correction TD Contrôle de GestionDocument12 pagesCorrection TD Contrôle de GestionAsma SatouriPas encore d'évaluation
- KueteTadzongGhislain 2016Document58 pagesKueteTadzongGhislain 2016Asma SatouriPas encore d'évaluation
- Feuilletage 187Document21 pagesFeuilletage 187Asma SatouriPas encore d'évaluation
- Explication ÉcartsDocument5 pagesExplication ÉcartsAsma SatouriPas encore d'évaluation
- Khi2 AFCDocument30 pagesKhi2 AFCAsma SatouriPas encore d'évaluation
- chapitreIV ACP-1Document41 pageschapitreIV ACP-1Asma SatouriPas encore d'évaluation
- Présentation Du Module Analyse Des DonnéesDocument2 pagesPrésentation Du Module Analyse Des DonnéesAsma SatouriPas encore d'évaluation
- Introduction Analyse MultidimensionnelleDocument5 pagesIntroduction Analyse MultidimensionnelleAsma SatouriPas encore d'évaluation
- Correction Examen À FaireDocument3 pagesCorrection Examen À FaireAsma SatouriPas encore d'évaluation
- CHAPITRE 2 Analyse UnidimensionnelleDocument21 pagesCHAPITRE 2 Analyse UnidimensionnelleAsma SatouriPas encore d'évaluation
- Chap2 - Identification Et Typologie Des ProcessusDocument12 pagesChap2 - Identification Et Typologie Des ProcessusAsma SatouriPas encore d'évaluation
- Chapitre I Les Données StatistiquesDocument11 pagesChapitre I Les Données StatistiquesAsma SatouriPas encore d'évaluation
- Geophysique INE LPH2 2020-1Document28 pagesGeophysique INE LPH2 2020-1EustachianPas encore d'évaluation
- Lois de Newton Resume de Cours 2Document3 pagesLois de Newton Resume de Cours 2Trkhbi9 AnoflPas encore d'évaluation
- Dossier Sur Le JaponDocument40 pagesDossier Sur Le JaponYomna SondossPas encore d'évaluation
- Analyse D'un Programme 1Document19 pagesAnalyse D'un Programme 1yahiaoui abirPas encore d'évaluation
- Manuel de Procédure XRF NITONDocument10 pagesManuel de Procédure XRF NITONMamadou FAYEPas encore d'évaluation
- TP03 onduleur MLI Vectorielle - ٠٩٣٦٣٦Document3 pagesTP03 onduleur MLI Vectorielle - ٠٩٣٦٣٦ammari.dz2002Pas encore d'évaluation
- Cours de Transferts Thermiques SMP (S6)Document83 pagesCours de Transferts Thermiques SMP (S6)MOHAMMED ZAKARIA BAALIPas encore d'évaluation
- PowerpointDocument18 pagesPowerpointDjeradé golbé ParfaitPas encore d'évaluation
- Le Mouvement Et Le Repos Exercices 3ac 2Document2 pagesLe Mouvement Et Le Repos Exercices 3ac 2anosa sninehPas encore d'évaluation
- SM GESs - Referentiel v2Document30 pagesSM GESs - Referentiel v2Oumaima AqilPas encore d'évaluation
- 3615 Fiscalite Du Digital Digitalisation de La FiscaliteDocument14 pages3615 Fiscalite Du Digital Digitalisation de La FiscalitewisalPas encore d'évaluation
- CG1RapportPripodev1 0Document160 pagesCG1RapportPripodev1 0Serge LengaPas encore d'évaluation
- Propriétés Physiques Et Mécaniques Du BoisDocument8 pagesPropriétés Physiques Et Mécaniques Du Boiselie moyap100% (3)
- These Final PDFDocument244 pagesThese Final PDFNozha FehriPas encore d'évaluation
- Integration de L'education Aux Valeurs...Document73 pagesIntegration de L'education Aux Valeurs...Hamdi HamdiPas encore d'évaluation
- 2 Bac CC 2 - 3 S2 PC 2bacDocument4 pages2 Bac CC 2 - 3 S2 PC 2bacrihabPas encore d'évaluation
- CV Abdelghani AtbirDocument2 pagesCV Abdelghani Atbirtiwahib2023Pas encore d'évaluation
- Controle 3 - 1 S2 3AC InterDocument2 pagesControle 3 - 1 S2 3AC Intertamimi marwanePas encore d'évaluation
- Note TechniqueDocument11 pagesNote TechniqueKhlif NadaPas encore d'évaluation
- TCHAD CompressedDocument12 pagesTCHAD CompressedamadoumodiaPas encore d'évaluation
- Francais MicromegasDocument4 pagesFrancais MicromegasBilal El OuassiliPas encore d'évaluation
- Fon CtionsDocument24 pagesFon CtionsSofiane KharchiPas encore d'évaluation
- TD TP3Document21 pagesTD TP3Latifa Er-rajyPas encore d'évaluation
- CV LoubnaDocument1 pageCV LoubnaAmine DiabyPas encore d'évaluation
- Syllabus Cours Microecodev M1 - EcoDocument7 pagesSyllabus Cours Microecodev M1 - EcoEliada OlapadePas encore d'évaluation
- 6986 Fiche CyberdeckDocument2 pages6986 Fiche CyberdecksltrPas encore d'évaluation
- Algorithmique CoursetTP USTHBDocument70 pagesAlgorithmique CoursetTP USTHBVEFREEDOM Sarl100% (1)
- Cours ROUTE CTE TOPO LABO - Evacuation Des EauxDocument14 pagesCours ROUTE CTE TOPO LABO - Evacuation Des EauxStachis MadiambaPas encore d'évaluation
- Le Kit de Survie de L'étudiant en Droit 2022-2023Document47 pagesLe Kit de Survie de L'étudiant en Droit 2022-2023Ousmane Kâ100% (1)
- 355 BM Sda2017 2030 Vo1528122082147Document120 pages355 BM Sda2017 2030 Vo1528122082147Igo NakiPas encore d'évaluation