Vous aimerez peut-être aussi
- TR PC Pola Lumiere 1213Document47 pagesTR PC Pola Lumiere 1213Cherry BmPas encore d'évaluation
- Linux Systeme SiliciumDocument26 pagesLinux Systeme SiliciumCherry BmPas encore d'évaluation
- LignesDocument28 pagesLignesSarah MhPas encore d'évaluation
- LignesDocument28 pagesLignesSarah MhPas encore d'évaluation
- Tutorial Ofdmtutorial FrenchDocument27 pagesTutorial Ofdmtutorial FrenchDavid SalahPas encore d'évaluation
- Tipe Ltrage Adaptatif ENSA KenitraDocument41 pagesTipe Ltrage Adaptatif ENSA KenitraCherry BmPas encore d'évaluation
- GELE5222 Chapitre1Document101 pagesGELE5222 Chapitre1Mohamed El GlafiPas encore d'évaluation
- GELE5222 Chapitre1Document101 pagesGELE5222 Chapitre1Mohamed El GlafiPas encore d'évaluation
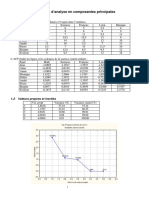
- Exemple Interpret ACPDocument10 pagesExemple Interpret ACPralaivao123Pas encore d'évaluation
- PipelineDocument25 pagesPipelineCherry BmPas encore d'évaluation
- Huff PDFDocument28 pagesHuff PDFMustapha El IdrissiPas encore d'évaluation
- FR Tanagra Calcul P Value PDFDocument21 pagesFR Tanagra Calcul P Value PDFCherry BmPas encore d'évaluation
- Cours SETREX6Document20 pagesCours SETREX6Cherry BmPas encore d'évaluation
- Ordonnancement Temps Réel Des Tâches Dans Un Système Industriel Par Intégration D'une Loi de Régulation AutomatiqueDocument128 pagesOrdonnancement Temps Réel Des Tâches Dans Un Système Industriel Par Intégration D'une Loi de Régulation AutomatiqueCherry BmPas encore d'évaluation
- 5-Capteur Numerique TP CorrDocument2 pages5-Capteur Numerique TP CorrCherry BmPas encore d'évaluation
- Num 2Document2 pagesNum 2Cherry BmPas encore d'évaluation
- (Canaux de Transmission) 2008-2009 - Cours - Partie 1Document48 pages(Canaux de Transmission) 2008-2009 - Cours - Partie 1Ibra CissePas encore d'évaluation
- Ensi2 TS S6Document19 pagesEnsi2 TS S6Cherry BmPas encore d'évaluation
- Filtrage AdaptatifDocument11 pagesFiltrage AdaptatifCherry BmPas encore d'évaluation
- (Canaux de Transmission) 2008-2009 - Cours - Partie 1Document48 pages(Canaux de Transmission) 2008-2009 - Cours - Partie 1Ibra CissePas encore d'évaluation
- AcpDocument72 pagesAcpzakariPas encore d'évaluation
- Optique de Polarisation Et Ses Applications: To Cite This VersionDocument29 pagesOptique de Polarisation Et Ses Applications: To Cite This Versionramos sergioPas encore d'évaluation
- Année Universitaire: 2019/2020 Semestre 3 Contrôle ContinueDocument1 pageAnnée Universitaire: 2019/2020 Semestre 3 Contrôle Continueamine9-406741Pas encore d'évaluation
- Génération de Variables AléatoiresDocument35 pagesGénération de Variables AléatoiresIlham TimadjerPas encore d'évaluation
- 2017 SujetsDocument23 pages2017 SujetsGogoPas encore d'évaluation
- Cours Proba PDFDocument36 pagesCours Proba PDFSamah Sam BouimaPas encore d'évaluation
- Statistique MathematiqueDocument107 pagesStatistique MathematiqueFabrice ArriaPas encore d'évaluation
- Cours SurvieDocument59 pagesCours SurvieFranck BouePas encore d'évaluation
- CNAEM-ECT 2019-EnonceDocument4 pagesCNAEM-ECT 2019-EnonceProfchaari SciencesPas encore d'évaluation
- TD4 - SMI - S3 - Corrigé TotalDocument6 pagesTD4 - SMI - S3 - Corrigé Totalelammaryibtissam777Pas encore d'évaluation
- STL3075Document44 pagesSTL3075Jacques BekonoPas encore d'évaluation
- Exercices de Probabilités IDocument25 pagesExercices de Probabilités IYoukoulelePas encore d'évaluation
- Cours de Gestion Des Risques D'assurances Et de Theorie de La RuineDocument102 pagesCours de Gestion Des Risques D'assurances Et de Theorie de La Ruinestn304Pas encore d'évaluation
- Liste Proba18Document19 pagesListe Proba18Lamine SarrPas encore d'évaluation
- TP8 Solutionnaire PDFDocument6 pagesTP8 Solutionnaire PDFFPPas encore d'évaluation
- TD 3Document2 pagesTD 3LoudjeinePas encore d'évaluation
- TD3 PDFDocument4 pagesTD3 PDFMay SsenPas encore d'évaluation
- Exercices L10Document12 pagesExercices L10ZogoPas encore d'évaluation
- QCM WormsDocument13 pagesQCM Wormsslimane AmPas encore d'évaluation
- Cours de ProbabilitésDocument3 pagesCours de ProbabilitésAbdessatar GouiderPas encore d'évaluation
- Chapitre Lois Usuelles Continues 2021 - 2022Document42 pagesChapitre Lois Usuelles Continues 2021 - 2022Abdelkaber abdelkaberPas encore d'évaluation
- SimulationDocument127 pagesSimulationIbtihal BenchikarPas encore d'évaluation
- Probabilite Au Bac S2 M. GassamaDocument7 pagesProbabilite Au Bac S2 M. GassamaBabacar NdiayePas encore d'évaluation
- 8 CoursDocument5 pages8 Courspaul steevPas encore d'évaluation
- Statistique 3 Chap1 FsjeDocument7 pagesStatistique 3 Chap1 FsjeSidahmed Cheikh AhmedouPas encore d'évaluation
- Chapitre1: Variables Aléatoires Discrètes: Benramdane AminaDocument33 pagesChapitre1: Variables Aléatoires Discrètes: Benramdane AminaMohamed MimnePas encore d'évaluation
- Exos Probas Agreg14 CorrDocument15 pagesExos Probas Agreg14 CorrSi Mohamed RahiliPas encore d'évaluation
- Cours Sureté Et Fiabilité (5éme Séance)Document20 pagesCours Sureté Et Fiabilité (5éme Séance)Wajdi ChtourouPas encore d'évaluation
- Cours Des V A R TTLDocument18 pagesCours Des V A R TTLbriki ayoubPas encore d'évaluation
- Introduction Aux Prob Abilites Eta La StatistiqueDocument86 pagesIntroduction Aux Prob Abilites Eta La StatistiqueEudes De L'Esprit SaintPas encore d'évaluation
- 2015 + CorrigéDocument5 pages2015 + CorrigéAYMEN MOUFIDPas encore d'évaluation
- Cfeuille 10Document4 pagesCfeuille 10Cliff Michel ZafackPas encore d'évaluation