Vous aimerez peut-être aussi
- Circuits Monophas EsDocument23 pagesCircuits Monophas EsYoussef SadkPas encore d'évaluation
- Transfo 1Document14 pagesTransfo 1Naim ChPas encore d'évaluation
- Cours Chapitre 3Document26 pagesCours Chapitre 3Naim ChPas encore d'évaluation
- Circuits Monophas EsDocument23 pagesCircuits Monophas EsYoussef SadkPas encore d'évaluation
- Ex5 Mas CorrigéDocument4 pagesEx5 Mas CorrigéNaim ChPas encore d'évaluation
- Cours Chapitre 2Document17 pagesCours Chapitre 2Naim ChPas encore d'évaluation
- GEAcoursDocument57 pagesGEAcoursNaim ChPas encore d'évaluation
- Intro PM 1Document1 pageIntro PM 1Naim ChPas encore d'évaluation
- Bases 18Document13 pagesBases 18Naim ChPas encore d'évaluation
- Tdmasterq 1Document10 pagesTdmasterq 1Naim ChPas encore d'évaluation
- Mes Repet 1Document4 pagesMes Repet 1Naim ChPas encore d'évaluation
- MementopmDocument4 pagesMementopmNaim ChPas encore d'évaluation
- PDF Cours EtuDocument32 pagesPDF Cours EtuNaim ChPas encore d'évaluation
- Repet 1Document11 pagesRepet 1Imad El GarianiPas encore d'évaluation
- Memento MSP 21Document9 pagesMemento MSP 21Naim ChPas encore d'évaluation
- Estimation Cartes 2Document10 pagesEstimation Cartes 2Naim ChPas encore d'évaluation
- Exo Entrainement 13Document5 pagesExo Entrainement 13Naim ChPas encore d'évaluation
- Cours 3Document37 pagesCours 3Naim ChPas encore d'évaluation
- Descriptif Donnees IshareDocument3 pagesDescriptif Donnees IshareNaim ChPas encore d'évaluation
- Mes Repet 1Document4 pagesMes Repet 1Naim ChPas encore d'évaluation
- Ci Prob 4Document8 pagesCi Prob 4Naim ChPas encore d'évaluation
- Cours MasterDocument55 pagesCours MasterNaim ChPas encore d'évaluation
- Bases 15Document31 pagesBases 15Naim ChPas encore d'évaluation
- Bases 17Document17 pagesBases 17Naim ChPas encore d'évaluation
- tps3 ElnDocument2 pagestps3 ElnNaim ChPas encore d'évaluation
- Mementor 5Document8 pagesMementor 5Naim ChPas encore d'évaluation
- Ex s7 Bsa 1Document9 pagesEx s7 Bsa 1Naim ChPas encore d'évaluation
- Cours 2018 s7 EtuDocument43 pagesCours 2018 s7 EtuNaim ChPas encore d'évaluation
- Cours 2Document11 pagesCours 2CHADDOUPas encore d'évaluation
- Cours 6 Comparaison de MoyennesDocument4 pagesCours 6 Comparaison de MoyenneskouyatePas encore d'évaluation
- Chapitre 2 MLDocument50 pagesChapitre 2 MLNour Ben NasserPas encore d'évaluation
- 1 BI IntroductionDocument17 pages1 BI IntroductionImene AssousPas encore d'évaluation
- TP1 Data MiningDocument3 pagesTP1 Data MiningSARA STAMBOULIPas encore d'évaluation
- Exercices Avec Corriges Analyse Des Donn Es TD 01 05 10Document13 pagesExercices Avec Corriges Analyse Des Donn Es TD 01 05 10Med Amine Talhaoui71% (7)
- 1 1 PDFDocument16 pages1 1 PDFAugustin MbamPas encore d'évaluation
- Sujet Et Corrige Type Bac 2011 Serie A1 Gabon MathematiquesDocument5 pagesSujet Et Corrige Type Bac 2011 Serie A1 Gabon MathematiquesMaria DsiePas encore d'évaluation
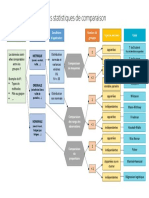
- Tests Statistiques de ComparaisonDocument1 pageTests Statistiques de ComparaisonValentine WautierPas encore d'évaluation
- ResuméDocument2 pagesResuméyafo 2kpiPas encore d'évaluation
- PréfaceDocument3 pagesPréfaceLevi AnohPas encore d'évaluation
- Cours 4 - CAHDocument63 pagesCours 4 - CAHkistidi33Pas encore d'évaluation
- Statistique Descriptive Chap1Document23 pagesStatistique Descriptive Chap1Mohamed labibiPas encore d'évaluation
- Cours RLMultipleDocument60 pagesCours RLMultiplesporara alio100% (2)
- Resume de SpssDocument6 pagesResume de SpssFadiPas encore d'évaluation
- Introduction À La Géostatistique Et VariogrammesDocument67 pagesIntroduction À La Géostatistique Et VariogrammesBachirHaider100% (1)
- Brochure M2 MASS POPDocument22 pagesBrochure M2 MASS POPQu CPas encore d'évaluation
- Tests Statistiques17Document59 pagesTests Statistiques17Tarek FennichePas encore d'évaluation
- Guidelines-on-Data-Analytics-book-05de4f7fd52e565-67820093 FRDocument57 pagesGuidelines-on-Data-Analytics-book-05de4f7fd52e565-67820093 FRNessaty KoubePas encore d'évaluation
- Feuille de TD1Document3 pagesFeuille de TD1amineboubou02Pas encore d'évaluation
- Le livre de la mémoire libérée : Apprenez plus vite, retenez tout avec des techniques de mémorisation simples et puissantesD'EverandLe livre de la mémoire libérée : Apprenez plus vite, retenez tout avec des techniques de mémorisation simples et puissantesÉvaluation : 4 sur 5 étoiles4/5 (6)
- Aimez-Vous en 12 Étapes Pratiques: Un Manuel pour Améliorer l'Estime de Soi, Prendre Conscience de sa Valeur, se Débarrasser du Doute et Trouver un Bonheur VéritableD'EverandAimez-Vous en 12 Étapes Pratiques: Un Manuel pour Améliorer l'Estime de Soi, Prendre Conscience de sa Valeur, se Débarrasser du Doute et Trouver un Bonheur VéritableÉvaluation : 5 sur 5 étoiles5/5 (4)
- Neuropsychologie: Les bases théoriques et pratiques du domaine d'étude (psychologie pour tous)D'EverandNeuropsychologie: Les bases théoriques et pratiques du domaine d'étude (psychologie pour tous)Pas encore d'évaluation
- Comment développer l’autodiscipline: Résiste aux tentations et atteins tes objectifs à long termeD'EverandComment développer l’autodiscipline: Résiste aux tentations et atteins tes objectifs à long termeÉvaluation : 4.5 sur 5 étoiles4.5/5 (7)
- La Pensée Positive en 30 Jours: Manuel Pratique pour Penser Positivement, Former votre Critique Intérieur, Arrêter la Réflexion Excessive et Changer votre État d'Esprit: Devenir une Personne Consciente et PositiveD'EverandLa Pensée Positive en 30 Jours: Manuel Pratique pour Penser Positivement, Former votre Critique Intérieur, Arrêter la Réflexion Excessive et Changer votre État d'Esprit: Devenir une Personne Consciente et PositiveÉvaluation : 4.5 sur 5 étoiles4.5/5 (12)
- La vie des abeilles: Prix Nobel de littératureD'EverandLa vie des abeilles: Prix Nobel de littératureÉvaluation : 4 sur 5 étoiles4/5 (41)
- Force Mentale et Maîtrise de la Discipline: Renforcez votre Confiance en vous pour Débloquer votre Courage et votre Résilience ! (Comprend un Manuel Pratique en 10 Étapes et 15 Puissants Exercices)D'EverandForce Mentale et Maîtrise de la Discipline: Renforcez votre Confiance en vous pour Débloquer votre Courage et votre Résilience ! (Comprend un Manuel Pratique en 10 Étapes et 15 Puissants Exercices)Évaluation : 4.5 sur 5 étoiles4.5/5 (28)
- Anatomie & 100 étirements essentiels: Techniques, Bénéfices attendus, Précautions à prendre, Conseils, Tableaux de séries, DouleursD'EverandAnatomie & 100 étirements essentiels: Techniques, Bénéfices attendus, Précautions à prendre, Conseils, Tableaux de séries, DouleursPas encore d'évaluation
- Secrets ancestraux d'un maître guérisseur: Un sceptique occidental, un maître oriental et les plus grands secrets de la vieD'EverandSecrets ancestraux d'un maître guérisseur: Un sceptique occidental, un maître oriental et les plus grands secrets de la vieÉvaluation : 5 sur 5 étoiles5/5 (2)
- Entretien clinique: Outils et techniques de diagnostic en santé mentaleD'EverandEntretien clinique: Outils et techniques de diagnostic en santé mentalePas encore d'évaluation
- Géobiologie de l'habitat et Géobiologie sacrée: Pour un lieu sainD'EverandGéobiologie de l'habitat et Géobiologie sacrée: Pour un lieu sainÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Électrotechnique | Pas à Pas: Bases, composants & circuits expliqués pour les débutantsD'EverandÉlectrotechnique | Pas à Pas: Bases, composants & circuits expliqués pour les débutantsÉvaluation : 5 sur 5 étoiles5/5 (1)
- Hypnotisme et Magnétisme, Somnambulisme, Suggestion et Télépathie, Influence personnelle: Cours Pratique completD'EverandHypnotisme et Magnétisme, Somnambulisme, Suggestion et Télépathie, Influence personnelle: Cours Pratique completÉvaluation : 4.5 sur 5 étoiles4.5/5 (8)
- Harmonisation Energétique des Lieux: Habitat et haut-lieux sacrés 2020D'EverandHarmonisation Energétique des Lieux: Habitat et haut-lieux sacrés 2020Évaluation : 2.5 sur 5 étoiles2.5/5 (3)
- Magnétisme Personnel ou Psychique: Éducation de la Pensée, développement de la Volonté, pour être Heureux, Fort, Bien Portant et réussir en tout.D'EverandMagnétisme Personnel ou Psychique: Éducation de la Pensée, développement de la Volonté, pour être Heureux, Fort, Bien Portant et réussir en tout.Évaluation : 5 sur 5 étoiles5/5 (1)
- Le TDA/H chez l'adulte: Apprendre à vivre sereinement avec son trouble de l'attentionD'EverandLe TDA/H chez l'adulte: Apprendre à vivre sereinement avec son trouble de l'attentionPas encore d'évaluation
- Émotions et intelligence émotionnelle dans les organisationsD'EverandÉmotions et intelligence émotionnelle dans les organisationsPas encore d'évaluation
- Coaching de vie: Manuel de bord pour coachs et coachésD'EverandCoaching de vie: Manuel de bord pour coachs et coachésPas encore d'évaluation