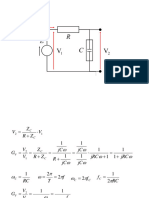
Vous aimerez peut-être aussi
- Examen Bidon 2011Document6 pagesExamen Bidon 2011rachidinfo777Pas encore d'évaluation
- Bac-Blanc2022.pdf Version 1Document4 pagesBac-Blanc2022.pdf Version 1Aziz HamdiPas encore d'évaluation
- TD Révision Python ISMEDocument3 pagesTD Révision Python ISMEHendou MohamedPas encore d'évaluation
- TP2 Les Chaines Et Les Listes: Année Universitaire: 2019/2020Document3 pagesTP2 Les Chaines Et Les Listes: Année Universitaire: 2019/2020Emna ChouikhiPas encore d'évaluation
- Rattrapage 1Document8 pagesRattrapage 1calabi mozartPas encore d'évaluation
- Sud-Tulan Algorithmique - Et - Structures - de - DonneesDocument18 pagesSud-Tulan Algorithmique - Et - Structures - de - DonneesAnw aarPas encore d'évaluation
- Ex AlgoDocument8 pagesEx Algogueraria grPas encore d'évaluation
- ProgStruct2 - TDs 1 - Pointeurs PDFDocument5 pagesProgStruct2 - TDs 1 - Pointeurs PDFAbdoulrazak100% (1)
- TD Révision Python ISMSDocument4 pagesTD Révision Python ISMSYakoub IshaghPas encore d'évaluation
- Prototype Théorique SCDocument3 pagesPrototype Théorique SCyoussef ben ltaifaPas encore d'évaluation
- Prototype Théorique SC 220413 101720Document3 pagesPrototype Théorique SC 220413 101720Walim ZouariPas encore d'évaluation
- TD 2 CorrigeDocument3 pagesTD 2 CorrigeVivo Vivoo VIPas encore d'évaluation
- Structure Répétitive: I Boucle InconditionnelleDocument5 pagesStructure Répétitive: I Boucle InconditionnelleSim SalabimPas encore d'évaluation
- Devoir-De-Synthèse-N°3-Exemple - 10Document2 pagesDevoir-De-Synthèse-N°3-Exemple - 10Hadj Hani Abed ElhamidPas encore d'évaluation
- tp6 PDFDocument4 pagestp6 PDFAmenPas encore d'évaluation
- Devoir 1 Algorithmes-1Document3 pagesDevoir 1 Algorithmes-1Nour El ZeroualiPas encore d'évaluation
- Devoir 1312Document5 pagesDevoir 1312kntmd8ppdaPas encore d'évaluation
- DS Ap1 2021 - 2022Document2 pagesDS Ap1 2021 - 2022ben Mhamed IssamPas encore d'évaluation
- Poo 1 TD1&2Document4 pagesPoo 1 TD1&2instagram comPas encore d'évaluation
- Complexité D - Un AlgorithmeDocument60 pagesComplexité D - Un Algorithmekaram laafifPas encore d'évaluation
- Formateur A BENDAOUD Remarque:: Travaux Dirigés 7Document5 pagesFormateur A BENDAOUD Remarque:: Travaux Dirigés 7MW • ITAČHÎPas encore d'évaluation
- TD EnoncesDocument26 pagesTD EnoncesBelcheri DIABAKAPas encore d'évaluation
- TD - N4 - Fonctions Et ProcéduresDocument2 pagesTD - N4 - Fonctions Et ProcéduresHabbaChi SaLwaPas encore d'évaluation
- Serie Tri 4siDocument2 pagesSerie Tri 4siKhouloud Bjaoui BouzidiPas encore d'évaluation
- TP C AavncéDocument5 pagesTP C AavncésafouhPas encore d'évaluation
- Epreuve ASD Concours de Doctorat Univ Batna 2017-2018 (Tchi Drive)Document4 pagesEpreuve ASD Concours de Doctorat Univ Batna 2017-2018 (Tchi Drive)Ikram BoubaPas encore d'évaluation
- Rattrapage S2-Juin-2018pDocument1 pageRattrapage S2-Juin-2018ptroxxPas encore d'évaluation
- Devoir de Synthèse N°2 - Algorithmique Et Programmation - 3ème Informatique (2011-2012) Mme IbtissemDocument2 pagesDevoir de Synthèse N°2 - Algorithmique Et Programmation - 3ème Informatique (2011-2012) Mme Ibtissemanourane485Pas encore d'évaluation
- Coursalgorithmiqueetcomplexitecomplet 120919033813 Phpapp02 PDFDocument104 pagesCoursalgorithmiqueetcomplexitecomplet 120919033813 Phpapp02 PDFazertytyty000Pas encore d'évaluation
- Devoir de Synthèse N°1 Exemple 29 2014 2015Document2 pagesDevoir de Synthèse N°1 Exemple 29 2014 2015Narjes BoussamaPas encore d'évaluation
- DS 1Document5 pagesDS 1PROF PROFPas encore d'évaluation
- ds2 2024 FinalDocument8 pagesds2 2024 FinalMahmoud BakiniPas encore d'évaluation
- 7a280-Langagec TD SolutionsDocument33 pages7a280-Langagec TD SolutionsEddy OuattaraPas encore d'évaluation
- Prototype Théorique SC ImprimableDocument2 pagesPrototype Théorique SC Imprimableyoussef ben ltaifaPas encore d'évaluation
- Enoncé Seance N°3 PDFDocument3 pagesEnoncé Seance N°3 PDFkhalil stars10% (1)
- TD EnoncesDocument26 pagesTD Enoncesihsen gasmiPas encore d'évaluation
- Série D'exercices N°2 - Algorithmique Pour La Revision - Bac Informatique (2010-2011) Elève Mahdhi MabroukDocument3 pagesSérie D'exercices N°2 - Algorithmique Pour La Revision - Bac Informatique (2010-2011) Elève Mahdhi MabroukSaifeddine MakniPas encore d'évaluation
- TDS 2021 2022 EtudiantsDocument12 pagesTDS 2021 2022 EtudiantsHuy NguyễnPas encore d'évaluation
- Série D'exercices N°1 - Algorithmique - Bac Informatique (2010-2011) Elève Mahdhi MabroukDocument2 pagesSérie D'exercices N°1 - Algorithmique - Bac Informatique (2010-2011) Elève Mahdhi MabroukSaifeddine Makni100% (2)
- Controle 2 - AlgoDocument4 pagesControle 2 - AlgoYassin AbdoPas encore d'évaluation
- Formateur A BENDAOUD: Travaux Dirigés 2Document5 pagesFormateur A BENDAOUD: Travaux Dirigés 2MW • ITAČHÎPas encore d'évaluation
- DS20Document4 pagesDS20Azumi ChanPas encore d'évaluation
- 4 Synsth 1 18b4da6 PDFDocument1 page4 Synsth 1 18b4da6 PDFGhassen AMAIMIAPas encore d'évaluation
- PfeDocument7 pagesPfeSi Mohamed RahiliPas encore d'évaluation
- TP 5Document7 pagesTP 5Mohamed OuaggaPas encore d'évaluation
- DS2 3si PDFDocument2 pagesDS2 3si PDFSafowan0% (1)
- TP Examen Inf231 10 02 2024Document1 pageTP Examen Inf231 10 02 2024edoafarellePas encore d'évaluation
- Analyse Numériqie PDFDocument32 pagesAnalyse Numériqie PDFismailinesPas encore d'évaluation
- Poly MN 2016-2017Document32 pagesPoly MN 2016-2017Moustapha ChaibdraaPas encore d'évaluation
- Coursalgorithmique Et ComplexiteDocument105 pagesCoursalgorithmique Et ComplexiteAÿlä AylaPas encore d'évaluation
- Exos Suppl2012Document6 pagesExos Suppl2012AzZaPas encore d'évaluation
- Cours 4si 2022 2023 Anis ELBAHI (Version2) ÉlèveDocument63 pagesCours 4si 2022 2023 Anis ELBAHI (Version2) Élèvemedprof5Pas encore d'évaluation
- Devoir 3 SI S N°3Document2 pagesDevoir 3 SI S N°3Hadj Hani Abed Elhamid50% (2)
- CPGE Info MementoPythonDocument3 pagesCPGE Info MementoPythonAlexandre Quaranta Aubin SahallorPas encore d'évaluation
- ACFrOgCPGNvt15vNiyVgYD7eXj OEZzG iWevnQKLQwnPmnJIcwJus3V7DId84mWzSR0OZeJvhJ-1CXN2DPguUKBaUDvIZL0lHD6QDI4MxQKorBAcH5cdHhveCdlf5Zn-pWzXd Jdm7x4 VBVCSRDocument3 pagesACFrOgCPGNvt15vNiyVgYD7eXj OEZzG iWevnQKLQwnPmnJIcwJus3V7DId84mWzSR0OZeJvhJ-1CXN2DPguUKBaUDvIZL0lHD6QDI4MxQKorBAcH5cdHhveCdlf5Zn-pWzXd Jdm7x4 VBVCSRAli Yassine BelHadj Rhouma100% (2)
- ds1 2eme InfoDocument4 pagesds1 2eme Infolaz100% (1)
- Inf1005C - Programmation Procédurale: Directives ParticulièresDocument3 pagesInf1005C - Programmation Procédurale: Directives ParticulièresMohamed Amine BEN BOUBKERPas encore d'évaluation
- Corrige Du CC1 - MatlabDocument3 pagesCorrige Du CC1 - MatlabSequaq Mohammed Amine100% (2)
- Examen Mai 09 Avec Corrige StrictDocument6 pagesExamen Mai 09 Avec Corrige Strictihsen gasmiPas encore d'évaluation
- Serie 1 MProGCDocument2 pagesSerie 1 MProGCMedlemine AghrabattePas encore d'évaluation
- TP3 Ti 2019Document3 pagesTP3 Ti 2019Babi BenPas encore d'évaluation
- Cours Matlab M1ASEDocument15 pagesCours Matlab M1ASEHerton CarelPas encore d'évaluation
- Chapitre 2Document20 pagesChapitre 2hichampikpok2021Pas encore d'évaluation
- ANA NUM 2 - Cours Approximation PolynômialeDocument9 pagesANA NUM 2 - Cours Approximation PolynômialeSab RinaPas encore d'évaluation
- 3 2 Pannes 150508152704 Lva1 App6892Document6 pages3 2 Pannes 150508152704 Lva1 App6892Hõüđä ŽãabařPas encore d'évaluation
- CM AcoustiqueDocument72 pagesCM AcoustiqueNabila HamlilPas encore d'évaluation
- Le Tournant Cognitif en PragmatiqueDocument19 pagesLe Tournant Cognitif en PragmatiqueHélène-Marie JuteauPas encore d'évaluation
- 1-Reseaux Direct Reciproque Correction Devoir 1 PDFDocument2 pages1-Reseaux Direct Reciproque Correction Devoir 1 PDFSamah Samah100% (2)
- Pour L'Obtention Du Doctorat en Science Économique: Ecole Nationale Superieure Du Pétrole Et Des MoteurvsDocument353 pagesPour L'Obtention Du Doctorat en Science Économique: Ecole Nationale Superieure Du Pétrole Et Des MoteurvsAmina BadaouiPas encore d'évaluation
- Environnement Et Proprete 2009Document59 pagesEnvironnement Et Proprete 2009toufikPas encore d'évaluation
- TDTZDocument2 pagesTDTZShakib MesbahiPas encore d'évaluation
- Manuel Macros Xsteel 8Document69 pagesManuel Macros Xsteel 8Chaker Amir100% (1)
- Mini-Projet Sur RDM Au Niveau de l'ENSTP Du TchadDocument96 pagesMini-Projet Sur RDM Au Niveau de l'ENSTP Du TchadIves GuelmbayePas encore d'évaluation
- Tracé en PlanDocument8 pagesTracé en PlanYacoudima100% (1)
- CoursDocument12 pagesCours9jm5q4qj47Pas encore d'évaluation
- Planification ProjetDocument0 pagePlanification ProjetbkajjiPas encore d'évaluation
- TP4 ConteneursDocument2 pagesTP4 ConteneursNo00orPas encore d'évaluation
- Série 5 Systémes 3APIC - PDF SystemDocument1 pageSérie 5 Systémes 3APIC - PDF SystemOmar BoulouihaPas encore d'évaluation
- Series FonctionsDocument4 pagesSeries FonctionsAmine XGhost MidoPas encore d'évaluation
- 04 Trace Et Normes GeometriquesDocument76 pages04 Trace Et Normes GeometriquesYesmine100% (3)
- 03 Statique AnalytiqueDocument5 pages03 Statique Analytiquewilliandry NDJEWEPas encore d'évaluation
- Theoremes Du Point Fixe de Banach BrouweDocument48 pagesTheoremes Du Point Fixe de Banach BrouweBESSAIAH IMANEPas encore d'évaluation
- La Validation de La Méthode AnalytiqueDocument39 pagesLa Validation de La Méthode AnalytiqueImane Ht100% (1)
- E141 TP Circuit RC Et CRDocument8 pagesE141 TP Circuit RC Et CRsihamarbaz14Pas encore d'évaluation
- CoursDocument35 pagesCours[AE]Pas encore d'évaluation
- Rapport Zeta TeamDocument25 pagesRapport Zeta TeamSow AbibalahiPas encore d'évaluation
- Modelisation 19Document20 pagesModelisation 19Haitam El FathiPas encore d'évaluation
- Cours Math - Chap 1 Produit Scalaire Dans Le Plan - 3ème Sciences (2009-2010) MR Abdelbasset LaataouiDocument7 pagesCours Math - Chap 1 Produit Scalaire Dans Le Plan - 3ème Sciences (2009-2010) MR Abdelbasset Laataouiوجدي ريدانPas encore d'évaluation
- Appui Technique-Temps UnitaireDocument6 pagesAppui Technique-Temps UnitaireRustem SahinPas encore d'évaluation