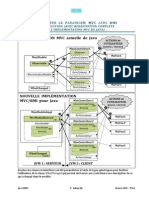
Vous aimerez peut-être aussi
- MAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsD'EverandMAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsPas encore d'évaluation
- TP Oriente Objet Avec Python - Ti15Document2 pagesTP Oriente Objet Avec Python - Ti15noussa79Pas encore d'évaluation
- Formation 3D par la pratique avec C#5 et WPF: Modeliser des moleculesD'EverandFormation 3D par la pratique avec C#5 et WPF: Modeliser des moleculesPas encore d'évaluation
- DS Corrig#U00e9Document5 pagesDS Corrig#U00e9Abir Ay Ed100% (1)
- Examen InterrogationDocument5 pagesExamen InterrogationAyoub BenPas encore d'évaluation
- TD02 - Réseaux de Neurones - SolutionDocument8 pagesTD02 - Réseaux de Neurones - SolutionNassr eddinePas encore d'évaluation
- Programmation Orientée Objet Et Langage Java TD #4Document6 pagesProgrammation Orientée Objet Et Langage Java TD #4Cha ymaPas encore d'évaluation
- Deepmath - Mathématiques (Simples) Des Réseaux de Neurones (Pas Trop Compliqués) : Algorithmes Et MathématiquesDocument283 pagesDeepmath - Mathématiques (Simples) Des Réseaux de Neurones (Pas Trop Compliqués) : Algorithmes Et MathématiquesgilouPas encore d'évaluation
- TD01 - Fondements IADocument2 pagesTD01 - Fondements IAAnes ElmouaddebPas encore d'évaluation
- TP - Evaluation JAVA II - 2022 - 2023 PDFDocument4 pagesTP - Evaluation JAVA II - 2022 - 2023 PDFYounes AKELPas encore d'évaluation
- Activite Controle ContinueDocument2 pagesActivite Controle ContinueKha LedPas encore d'évaluation
- BDD NoSQL Et Big Data - Chapitre II Partie 2 NewDocument6 pagesBDD NoSQL Et Big Data - Chapitre II Partie 2 Newson.600Pas encore d'évaluation
- TP1 Java PDFDocument2 pagesTP1 Java PDFNajeh TouilPas encore d'évaluation
- Correction TD4Document27 pagesCorrection TD4AxA AAAxAxAxAAAPas encore d'évaluation
- Untitled 1Document5 pagesUntitled 1TheoPas encore d'évaluation
- TD Machine Regression PythonDocument3 pagesTD Machine Regression Pythontest testPas encore d'évaluation
- Cours Programmation Dynamique - v2Document11 pagesCours Programmation Dynamique - v2Bob GribyPas encore d'évaluation
- DS Novembre 2018 PDFDocument2 pagesDS Novembre 2018 PDFnassim ksouriPas encore d'évaluation
- Chap1 ProgrammationConcurentePOSIX PDFDocument43 pagesChap1 ProgrammationConcurentePOSIX PDFmehdi snenePas encore d'évaluation
- Compilation s5Document373 pagesCompilation s5Wiam EL BERRARIPas encore d'évaluation
- Programmation ConcurenteDocument74 pagesProgrammation Concurenteikhou08Pas encore d'évaluation
- Administration Et Hebergement WebDocument5 pagesAdministration Et Hebergement WebTagne Guylain FlorianPas encore d'évaluation
- TD MVC Pour RMIDocument6 pagesTD MVC Pour RMIPooopoPas encore d'évaluation
- Partie 1 CH1 Comprendre Les Réseaux Informatique en NuageDocument69 pagesPartie 1 CH1 Comprendre Les Réseaux Informatique en NuageBouchra DikhiyaPas encore d'évaluation
- TD Les SemaphoresDocument4 pagesTD Les SemaphoresKarim KemoumPas encore d'évaluation
- Cours UMLDocument33 pagesCours UMLdeogratias davoPas encore d'évaluation
- TP1 IngDocument4 pagesTP1 IngChouichi GhadaPas encore d'évaluation
- 1 Ch1 Introduction À MLDocument78 pages1 Ch1 Introduction À MLons nouiliPas encore d'évaluation
- PGP PDFDocument105 pagesPGP PDFXenosPas encore d'évaluation
- TD2 IndexationDocument3 pagesTD2 IndexationAmine AmiriPas encore d'évaluation
- Mif18 2015 MapreduceDocument4 pagesMif18 2015 MapreduceAnonymous 1P2S4tbMPas encore d'évaluation
- Mini ProjetDocument3 pagesMini ProjetInsaf Achour100% (1)
- Atelier 2Document3 pagesAtelier 2dddr eePas encore d'évaluation
- Explication TP OpenSSLDocument5 pagesExplication TP OpenSSLLeNantais Sonderangebote100% (1)
- List (Java)Document1 pageList (Java)Diana MvaebemePas encore d'évaluation
- Polycopie ASD 3 PDFDocument88 pagesPolycopie ASD 3 PDFadsfasdfsdfsadfPas encore d'évaluation
- TP3 EnonceDocument4 pagesTP3 EnonceSaid AbbaouiPas encore d'évaluation
- TP Séquence 2Document5 pagesTP Séquence 2Brazza In My VeinsPas encore d'évaluation
- Transformation de Mod LesDocument25 pagesTransformation de Mod LesKarim KACEMPas encore d'évaluation
- Atelier 2 Encapsulation: Classe Et Objet: Objectif Du TPDocument13 pagesAtelier 2 Encapsulation: Classe Et Objet: Objectif Du TPnassim ksouriPas encore d'évaluation
- td01 HadoopDocument6 pagestd01 HadoopaissamemiPas encore d'évaluation
- Cours Algoritmique - Master1 - 2015 - 2021 - V1 - EtudiantDocument86 pagesCours Algoritmique - Master1 - 2015 - 2021 - V1 - EtudiantRitch OlsenPas encore d'évaluation
- Polycopie SEP 2021-ConvertiDocument46 pagesPolycopie SEP 2021-ConvertiSoheibPas encore d'évaluation
- TD Poo#1Document3 pagesTD Poo#1Alfred Mousaa SodeaPas encore d'évaluation
- Communication Inter Processus PDFDocument2 pagesCommunication Inter Processus PDFTracyPas encore d'évaluation
- RAPPORT DE STAGE IotDocument32 pagesRAPPORT DE STAGE IotNajib MounsefPas encore d'évaluation
- Cours 2 Notion de Hardware Et de Software Module Identifier Les Differents Composants Dun Microordinateur.Document2 pagesCours 2 Notion de Hardware Et de Software Module Identifier Les Differents Composants Dun Microordinateur.Paronia Mamadou Marabou40% (5)
- Correction Partie2 TP3 (Lien Physique Et Lien Symbolique)Document3 pagesCorrection Partie2 TP3 (Lien Physique Et Lien Symbolique)Rahma Ben YounesPas encore d'évaluation
- TD1 IngDocument3 pagesTD1 IngChouichi GhadaPas encore d'évaluation
- Série D'exercices #2 (Exclusion Mutuelle Dans Un Système Réparti)Document3 pagesSérie D'exercices #2 (Exclusion Mutuelle Dans Un Système Réparti)Abdessalam HattabPas encore d'évaluation
- Programmation Des Systèmes DistribuésDocument120 pagesProgrammation Des Systèmes DistribuésStaint PATRICKPas encore d'évaluation
- CH 3 ASD II Listes Chainées PDFDocument28 pagesCH 3 ASD II Listes Chainées PDFFiras MezghiPas encore d'évaluation
- Controle SystèmeDocument1 pageControle SystèmeAymane AsPas encore d'évaluation
- TP 3 - C++Document1 pageTP 3 - C++Ly NaPas encore d'évaluation
- UML Cas2DutilisationDocument54 pagesUML Cas2Dutilisationhafsa ladhassePas encore d'évaluation
- Chapitre3-Modele RelationnelDocument17 pagesChapitre3-Modele Relationnelmikao31Pas encore d'évaluation
- Cours Les ExceptionsDocument15 pagesCours Les Exceptionsgharbi mayssenPas encore d'évaluation
- TP CNNDocument4 pagesTP CNNFrank Facundo0% (1)
- TD1POODocument10 pagesTD1POOFarah HkiriPas encore d'évaluation
- TP SVMDocument2 pagesTP SVMChafik BerdjouhPas encore d'évaluation
- Cours Big Data Avancee Chp2 Data-IngestionDocument46 pagesCours Big Data Avancee Chp2 Data-IngestionMarwenCherifPas encore d'évaluation
- Cours Big Data Avancee Chp1 IntroductionDocument28 pagesCours Big Data Avancee Chp1 IntroductionMarwenCherifPas encore d'évaluation
- Atelier2 SqoopDocument4 pagesAtelier2 SqoopMarwenCherifPas encore d'évaluation
- Atelier1 Installation EnvironnementDocument12 pagesAtelier1 Installation EnvironnementMarwenCherifPas encore d'évaluation
- Formation Sur Le Cablage Des Reseaux Infor PDFDocument50 pagesFormation Sur Le Cablage Des Reseaux Infor PDFHamed HadjerPas encore d'évaluation
- Micro tp1Document14 pagesMicro tp1Abdou HarchePas encore d'évaluation
- Sim 231 0087Document29 pagesSim 231 0087Xavier DeguercyPas encore d'évaluation
- 08 SambaDocument19 pages08 SambaKadi DorayPas encore d'évaluation
- RainbowDocument4 pagesRainbowafipaPas encore d'évaluation
- Graphique Dans WordDocument7 pagesGraphique Dans Wordkouaya kebassa cyrillePas encore d'évaluation
- Cours Informatique S1 PDFDocument77 pagesCours Informatique S1 PDFaziz dadass50% (2)
- Chapitre 2 A&IDocument8 pagesChapitre 2 A&Ibouchama.fPas encore d'évaluation
- Cours Partie 1 Microprocesseur-2Document6 pagesCours Partie 1 Microprocesseur-2Mrad BelhasenPas encore d'évaluation
- 11 MalaxeurDocument28 pages11 MalaxeurSamiAmeur75% (4)
- Comment Supprimer Une Page Dans Un Document WordDocument9 pagesComment Supprimer Une Page Dans Un Document WordPeniel KzdPas encore d'évaluation
- Poubelle 3ème 2020 v5Document8 pagesPoubelle 3ème 2020 v5bounounou270Pas encore d'évaluation
- Ontology ENSEMDocument7 pagesOntology ENSEMhamza elgarragPas encore d'évaluation
- Métrologie Et Caractérisation de TraficDocument181 pagesMétrologie Et Caractérisation de TraficSa Mn100% (1)
- Cours3 AndroidDocument43 pagesCours3 Androidnoussa79Pas encore d'évaluation
- Didiacticiel AMC MeriseDocument86 pagesDidiacticiel AMC Merisemajidouba6355Pas encore d'évaluation
- Afef - PDF Chap 1Document17 pagesAfef - PDF Chap 1Ghalia ChalbiPas encore d'évaluation
- FRANCAIS IoT Based Automatic Vehicle License Plate Recognition System Ijariie4633Document7 pagesFRANCAIS IoT Based Automatic Vehicle License Plate Recognition System Ijariie4633Fernand AgneroPas encore d'évaluation
- PurgeDocument12 pagesPurgeahmed karamokoPas encore d'évaluation
- File Server Resource Manager CoursDocument26 pagesFile Server Resource Manager CoursNawal BenPas encore d'évaluation
- Les Structures ItérativesDocument27 pagesLes Structures ItérativesbideewPas encore d'évaluation
- Projet L3 (Enregistré Automatiquement)Document43 pagesProjet L3 (Enregistré Automatiquement)luxury carsPas encore d'évaluation
- Résumée LDDDocument3 pagesRésumée LDDMahdi MoonessPas encore d'évaluation
- Reading Comprehension Test 11Document8 pagesReading Comprehension Test 11mouchkilhadaPas encore d'évaluation
- Rainbow CrackDocument3 pagesRainbow CrackAbdoulaye AwPas encore d'évaluation
- Pa800 201UM FRE - 634618929650250000 PDFDocument358 pagesPa800 201UM FRE - 634618929650250000 PDFmissi yaddadenPas encore d'évaluation
- PFEs STEG Sousse Remote 2022Document4 pagesPFEs STEG Sousse Remote 2022Fares HasnaouiPas encore d'évaluation
- Ofppt: Fin La À ÀDocument27 pagesOfppt: Fin La À ÀMaroc Permis AUTO ECOLEPas encore d'évaluation
- Cours N°3 - Architecture Du Réseau NGNDocument29 pagesCours N°3 - Architecture Du Réseau NGNwakeurboromsam mbackéPas encore d'évaluation
- Application de Gestion de Stock (Scrum)Document9 pagesApplication de Gestion de Stock (Scrum)mouhamed hmidetPas encore d'évaluation
- Apprendre Python rapidement: Le guide du débutant pour apprendre tout ce que vous devez savoir sur Python, même si vous êtes nouveau dans la programmationD'EverandApprendre Python rapidement: Le guide du débutant pour apprendre tout ce que vous devez savoir sur Python, même si vous êtes nouveau dans la programmationPas encore d'évaluation
- Hacking pour débutant Le guide ultime du débutant pour apprendre les bases du hacking avec Kali Linux et comment se protéger des hackersD'EverandHacking pour débutant Le guide ultime du débutant pour apprendre les bases du hacking avec Kali Linux et comment se protéger des hackersPas encore d'évaluation
- Technologie automobile: Les Grands Articles d'UniversalisD'EverandTechnologie automobile: Les Grands Articles d'UniversalisPas encore d'évaluation
- Secrets du Marketing des Médias Sociaux 2021: Conseils et Stratégies Extrêmement Efficaces votre Facebook (Stimulez votre Engagement et Gagnez des Clients Fidèles)D'EverandSecrets du Marketing des Médias Sociaux 2021: Conseils et Stratégies Extrêmement Efficaces votre Facebook (Stimulez votre Engagement et Gagnez des Clients Fidèles)Évaluation : 4 sur 5 étoiles4/5 (2)
- Le guide du hacker : le guide simplifié du débutant pour apprendre les bases du hacking avec Kali LinuxD'EverandLe guide du hacker : le guide simplifié du débutant pour apprendre les bases du hacking avec Kali LinuxÉvaluation : 5 sur 5 étoiles5/5 (2)
- Revue des incompris revue d'histoire des oubliettes: Le Réveil de l'Horloge de Célestin Louis Maxime Dubuisson aliéniste et poèteD'EverandRevue des incompris revue d'histoire des oubliettes: Le Réveil de l'Horloge de Célestin Louis Maxime Dubuisson aliéniste et poèteÉvaluation : 3 sur 5 étoiles3/5 (3)
- Kali Linux pour débutant : Le guide ultime du débutant pour apprendre les bases de Kali Linux.D'EverandKali Linux pour débutant : Le guide ultime du débutant pour apprendre les bases de Kali Linux.Évaluation : 5 sur 5 étoiles5/5 (1)
- Guide Pour Les Débutants En Matière De Piratage Informatique: Comment Pirater Un Réseau Sans Fil, Sécurité De Base Et Test De Pénétration, Kali LinuxD'EverandGuide Pour Les Débutants En Matière De Piratage Informatique: Comment Pirater Un Réseau Sans Fil, Sécurité De Base Et Test De Pénétration, Kali LinuxÉvaluation : 1 sur 5 étoiles1/5 (1)
- Wi-Fi Hacking avec kali linux Guide étape par étape : apprenez à pénétrer les réseaux Wifi et les meilleures stratégies pour les sécuriserD'EverandWi-Fi Hacking avec kali linux Guide étape par étape : apprenez à pénétrer les réseaux Wifi et les meilleures stratégies pour les sécuriserPas encore d'évaluation
- Le plan marketing en 4 étapes: Stratégies et étapes clés pour créer des plans de marketing qui fonctionnentD'EverandLe plan marketing en 4 étapes: Stratégies et étapes clés pour créer des plans de marketing qui fonctionnentPas encore d'évaluation
- Dark Python : Apprenez à créer vos outils de hacking.D'EverandDark Python : Apprenez à créer vos outils de hacking.Évaluation : 3 sur 5 étoiles3/5 (1)
- L'analyse fondamentale facile à apprendre: Le guide d'introduction aux techniques et stratégies d'analyse fondamentale pour anticiper les événements qui font bouger les marchésD'EverandL'analyse fondamentale facile à apprendre: Le guide d'introduction aux techniques et stratégies d'analyse fondamentale pour anticiper les événements qui font bouger les marchésÉvaluation : 3.5 sur 5 étoiles3.5/5 (4)
- Python | Programmer pas à pas: Le guide du débutant pour une initiation simple & rapide à la programmationD'EverandPython | Programmer pas à pas: Le guide du débutant pour une initiation simple & rapide à la programmationPas encore d'évaluation
- WiFi Hacking : Le guide simplifié du débutant pour apprendre le hacking des réseaux WiFi avec Kali LinuxD'EverandWiFi Hacking : Le guide simplifié du débutant pour apprendre le hacking des réseaux WiFi avec Kali LinuxÉvaluation : 3 sur 5 étoiles3/5 (1)
- Le Guide Rapide Du Cloud Computing Et De La CybersécuritéD'EverandLe Guide Rapide Du Cloud Computing Et De La CybersécuritéPas encore d'évaluation
- Wireshark pour les débutants : Le guide ultime du débutant pour apprendre les bases de l’analyse réseau avec Wireshark.D'EverandWireshark pour les débutants : Le guide ultime du débutant pour apprendre les bases de l’analyse réseau avec Wireshark.Pas encore d'évaluation
- Le guide pratique du hacker dans les tests d’intrusion IoT : Le livre indispensable pour identifiez les vulnérabilités et sécurisez vos objets intelligentsD'EverandLe guide pratique du hacker dans les tests d’intrusion IoT : Le livre indispensable pour identifiez les vulnérabilités et sécurisez vos objets intelligentsPas encore d'évaluation
- Le trading en ligne facile à apprendre: Comment devenir un trader en ligne et apprendre à investir avec succèsD'EverandLe trading en ligne facile à apprendre: Comment devenir un trader en ligne et apprendre à investir avec succèsÉvaluation : 3.5 sur 5 étoiles3.5/5 (19)
- L'analyse technique facile à apprendre: Comment construire et interpréter des graphiques d'analyse technique pour améliorer votre activité de trading en ligne.D'EverandL'analyse technique facile à apprendre: Comment construire et interpréter des graphiques d'analyse technique pour améliorer votre activité de trading en ligne.Évaluation : 3.5 sur 5 étoiles3.5/5 (6)
- Le Bon Accord avec le Bon Fournisseur: Comment Mobiliser Toute la Puissance de vos Partenaires Commerciaux pour Réaliser vos ObjectifsD'EverandLe Bon Accord avec le Bon Fournisseur: Comment Mobiliser Toute la Puissance de vos Partenaires Commerciaux pour Réaliser vos ObjectifsÉvaluation : 4 sur 5 étoiles4/5 (2)
- Hacking pour débutants : Le guide complet du débutant pour apprendre les bases du hacking avec Kali LinuxD'EverandHacking pour débutants : Le guide complet du débutant pour apprendre les bases du hacking avec Kali LinuxÉvaluation : 4.5 sur 5 étoiles4.5/5 (4)
- Dans l'esprit des grand investisseurs: Un voyage à la découverte de la psychologie utilisée par les plus grands investisseurs de tous les temps à travers des analyses opérationnellD'EverandDans l'esprit des grand investisseurs: Un voyage à la découverte de la psychologie utilisée par les plus grands investisseurs de tous les temps à travers des analyses opérationnellÉvaluation : 4.5 sur 5 étoiles4.5/5 (3)
- Python Offensif : Le guide du débutant pour apprendre les bases du langage Python et créer des outils de hacking.D'EverandPython Offensif : Le guide du débutant pour apprendre les bases du langage Python et créer des outils de hacking.Pas encore d'évaluation
- La psychologie du trading facile à apprendre: Comment appliquer les stratégies et les attitudes psychologiques des traders gagnants pour réussir dans le trading.D'EverandLa psychologie du trading facile à apprendre: Comment appliquer les stratégies et les attitudes psychologiques des traders gagnants pour réussir dans le trading.Évaluation : 4 sur 5 étoiles4/5 (2)
- Python pour les hackers : Le guide des script kiddies : apprenez à créer vos propres outils de hackingD'EverandPython pour les hackers : Le guide des script kiddies : apprenez à créer vos propres outils de hackingÉvaluation : 5 sur 5 étoiles5/5 (1)
- Gestion de projet : outils pour la vie quotidienneD'EverandGestion de projet : outils pour la vie quotidienneÉvaluation : 5 sur 5 étoiles5/5 (2)