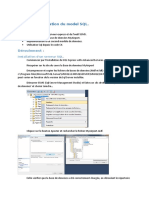
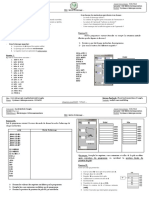
Vous aimerez peut-être aussi
- Bien débuter avec SQL: Exercices dans l'interface PhpMyAdmin et MySQLD'EverandBien débuter avec SQL: Exercices dans l'interface PhpMyAdmin et MySQLPas encore d'évaluation
- Chap 3Document8 pagesChap 3ELaidouni AmaraPas encore d'évaluation
- ExercicesDocument10 pagesExercicesdeogratias davoPas encore d'évaluation
- Tuto Python & Pandas - Installation Et Manipulations de BaseDocument18 pagesTuto Python & Pandas - Installation Et Manipulations de Basedeogratias davoPas encore d'évaluation
- Resume Dot NetDocument112 pagesResume Dot Netguizeni ahmedPas encore d'évaluation
- Support de Cours Parti1 SQLDocument40 pagesSupport de Cours Parti1 SQLjqy4h4zqc6Pas encore d'évaluation
- Kmeans PracticeDocument3 pagesKmeans PracticeSlal OpzaPas encore d'évaluation
- TP Python BDDDocument4 pagesTP Python BDDcastle.lili1009Pas encore d'évaluation
- Les Langages de ManipulationDocument8 pagesLes Langages de ManipulationkribetyasserPas encore d'évaluation
- Lab 2 SparkDocument9 pagesLab 2 Sparkheni.bouhamed100% (1)
- SQLite Databases - FRDocument28 pagesSQLite Databases - FRcirtatractorPas encore d'évaluation
- Resume CoursDocument57 pagesResume CoursWissal KHEMIRIPas encore d'évaluation
- coursPHP 4Document15 pagescoursPHP 4Zineb RouzliPas encore d'évaluation
- Cour pprogrammation mobile bd.docxDocument18 pagesCour pprogrammation mobile bd.docxmathiaszele3Pas encore d'évaluation
- Se Connecter À Une Base de Données Microsoft Access 2013 en CsharpDocument6 pagesSe Connecter À Une Base de Données Microsoft Access 2013 en CsharpEl Mehdi KharkoukPas encore d'évaluation
- Inbound 9055093283059651840Document6 pagesInbound 9055093283059651840SarraPas encore d'évaluation
- Chapitre 4 Accès Aux Bases de DonnéDocument46 pagesChapitre 4 Accès Aux Bases de DonnéYosr RannenPas encore d'évaluation
- TP 2 Model SQLDocument6 pagesTP 2 Model SQLturePas encore d'évaluation
- BB STI 2022 NR VFDocument6 pagesBB STI 2022 NR VFPROF PROFPas encore d'évaluation
- Data Persistence With SQLiteDocument6 pagesData Persistence With SQLiteGeorges A. K. BANNERMANPas encore d'évaluation
- Séance 2 - Transact SQL 2 - Administration Base de DonnéesDocument27 pagesSéance 2 - Transact SQL 2 - Administration Base de DonnéesMed Taha HakamPas encore d'évaluation
- PandasDocument45 pagesPandaschaima.khaluawiPas encore d'évaluation
- Module 5 - DatabaseInAndroidDocument13 pagesModule 5 - DatabaseInAndroidBellahssen BellgacemPas encore d'évaluation
- Linq 2Document19 pagesLinq 2Neo RuthPas encore d'évaluation
- Partie1 BasicsDocument103 pagesPartie1 BasicsFatima Zahra DevPas encore d'évaluation
- Chapitre JBDCDocument31 pagesChapitre JBDChatemPas encore d'évaluation
- Acces Aux DonneesDocument69 pagesAcces Aux DonneesKevin Ulysse AdjahoPas encore d'évaluation
- Optimisation Du Code Python 4Document29 pagesOptimisation Du Code Python 4Mehdi AmmouPas encore d'évaluation
- IntroductionDocument6 pagesIntroductionyousfiPas encore d'évaluation
- CH 4Document29 pagesCH 4Asma SomaPas encore d'évaluation
- LundiDocument57 pagesLundiZineb SaidiPas encore d'évaluation
- Ado NetDocument29 pagesAdo NetEFOUBA KOSSO JEAN MARIEPas encore d'évaluation
- TSQL S4Document24 pagesTSQL S4Mina MinouPas encore d'évaluation
- Les Bases de DonnéesDocument24 pagesLes Bases de DonnéesSimo AhmPas encore d'évaluation
- Chapitre1 1 2019Document15 pagesChapitre1 1 2019MDPas encore d'évaluation
- Les Bases de Données NoSQL2Document10 pagesLes Bases de Données NoSQL2Hanane NadiPas encore d'évaluation
- Connecter À Une BDD Oracle Avec ADODocument3 pagesConnecter À Une BDD Oracle Avec ADODjouhaina HirechePas encore d'évaluation
- Chapitre 2 Manipulation DonneesDocument9 pagesChapitre 2 Manipulation DonneesPape Moussa DiopPas encore d'évaluation
- Accès Aux Bases de Données Via JDBC PDFDocument6 pagesAccès Aux Bases de Données Via JDBC PDFmeftah otmanePas encore d'évaluation
- Tp2: Deep Learning: TensorflowDocument9 pagesTp2: Deep Learning: Tensorflowkais.chammakhiPas encore d'évaluation
- 2022 SDA 04 Types Abstraits - Structures LinéairesDocument62 pages2022 SDA 04 Types Abstraits - Structures Linéairessimon.queyrutPas encore d'évaluation
- Less10 SchemaDocument50 pagesLess10 Schemasalam salamberkaniPas encore d'évaluation
- ConnexionDocument22 pagesConnexiongilles_samuelPas encore d'évaluation
- Leçon 2 Création D'objets de Base de DonnéesDocument8 pagesLeçon 2 Création D'objets de Base de Donnéesaboubakar mohamedPas encore d'évaluation
- iBATIS SqlMaps 2 Tutorial FRDocument10 pagesiBATIS SqlMaps 2 Tutorial FRKhalid BenPas encore d'évaluation
- 14 15 TelecomN TpAAR RootDocument17 pages14 15 TelecomN TpAAR RootMarc MUSOLEPas encore d'évaluation
- TP - Python & MysqlDocument4 pagesTP - Python & MysqlParfait AYIPas encore d'évaluation
- DB IntroRequetesSQL MVDDocument9 pagesDB IntroRequetesSQL MVDCédric AurelPas encore d'évaluation
- Module 5 Python-Utilisation Pour La Data Science - Week3Document16 pagesModule 5 Python-Utilisation Pour La Data Science - Week3syslinux2000Pas encore d'évaluation
- 0074 Cours Ado Net VBDocument19 pages0074 Cours Ado Net VBkabi6713Pas encore d'évaluation
- Intro SQLDocument31 pagesIntro SQLanonymawifiPas encore d'évaluation
- TP 1 - Master Informatique Ann Ee 1: 1.1 Le Jeu de Donn Ees Iris (Fisher, 1936)Document6 pagesTP 1 - Master Informatique Ann Ee 1: 1.1 Le Jeu de Donn Ees Iris (Fisher, 1936)Mariama DIOUFPas encore d'évaluation
- TP2 BD PDFDocument7 pagesTP2 BD PDFIbrahima sory BahPas encore d'évaluation
- Base de Données - Créateur de RequêtesDocument21 pagesBase de Données - Créateur de Requêtesyves1ndriPas encore d'évaluation
- TD 2Document3 pagesTD 222108Pas encore d'évaluation
- 5 BDDDocument12 pages5 BDDRafikWaynePas encore d'évaluation
- LES MACROS AVEC GOOGLE SHEETS: Programmer en JavascriptD'EverandLES MACROS AVEC GOOGLE SHEETS: Programmer en JavascriptPas encore d'évaluation
- Table Des Matières - 978-2-409-00974-7Document39 pagesTable Des Matières - 978-2-409-00974-7Petit GeniePas encore d'évaluation
- M12-Diagnostic Du Poste de TravailDocument94 pagesM12-Diagnostic Du Poste de Travailggqgj56Pas encore d'évaluation
- DBA - Tkatek - Partie3Document24 pagesDBA - Tkatek - Partie3Wail ChoukhairiPas encore d'évaluation
- TP 11Document16 pagesTP 11Abdelmounim Graflog Zaki100% (1)
- Cours de Tech Et Concept Des Syst EmbarquesDocument93 pagesCours de Tech Et Concept Des Syst EmbarquesMC- risAPas encore d'évaluation
- 4 SambaDocument10 pages4 Sambayinero0s04Pas encore d'évaluation
- CHIV Réseaux de Communication Industriels Pour La SupervisionDocument10 pagesCHIV Réseaux de Communication Industriels Pour La SupervisionArrow ArrowPas encore d'évaluation
- Access 2007 Et VBADocument153 pagesAccess 2007 Et VBADominiquePas encore d'évaluation
- 5 - Spring Injection de Dépendances PDFDocument25 pages5 - Spring Injection de Dépendances PDFMohamed SAADAOUIPas encore d'évaluation
- 4-Amites SurchargOperateurs2Document34 pages4-Amites SurchargOperateurs2Kawtar DalalPas encore d'évaluation
- Environenement Micro OrdinateurDocument8 pagesEnvironenement Micro OrdinateurTx ChrisPas encore d'évaluation
- Mode de Structuration D'applications Réparties PDFDocument48 pagesMode de Structuration D'applications Réparties PDFdadou225Pas encore d'évaluation
- Comment Paramétrer Son Traitement de TexteDocument2 pagesComment Paramétrer Son Traitement de TexteAlgor AgbahidPas encore d'évaluation
- AngularDocument114 pagesAngularDidier SolheidPas encore d'évaluation
- Bip & LedDocument6 pagesBip & LedBelle KissPas encore d'évaluation
- Séries 1 2 3 4 5 6 Avec CorrectionDocument39 pagesSéries 1 2 3 4 5 6 Avec CorrectionArwa Rora67% (6)
- HP 245 G8 Notice TechniqueDocument1 pageHP 245 G8 Notice TechniqueMatteo RaphaelPas encore d'évaluation
- Aide Memoire OCLDocument2 pagesAide Memoire OCLmostafazmirli22Pas encore d'évaluation
- Fiche Produit Bitdefender GravityZone Advanced Business SecurityDocument4 pagesFiche Produit Bitdefender GravityZone Advanced Business SecurityRadimiPas encore d'évaluation
- ExercicesDocument24 pagesExerciceseddy lwakPas encore d'évaluation
- Historique Langage CDocument13 pagesHistorique Langage CvolvanoinePas encore d'évaluation
- Cours 7Document23 pagesCours 7sedkaouiwassilaPas encore d'évaluation
- 2018TD3 6800Document2 pages2018TD3 6800lyza DZPas encore d'évaluation
- Support Cours Algo3 L2 MPI LCDocument210 pagesSupport Cours Algo3 L2 MPI LCSARRPas encore d'évaluation
- Fox PDFDocument12 pagesFox PDFAnes Laoufi100% (1)
- 6.4.3.5 Lab - Configuring Basic EIGRP For IPv6Document9 pages6.4.3.5 Lab - Configuring Basic EIGRP For IPv6cheicktest1Pas encore d'évaluation
- Rapport de NAGIOSDocument33 pagesRapport de NAGIOSaya aabidPas encore d'évaluation
- Conception-Et Realisation-Dun-Site-Web-Pour-La-Gestion-Dun Jardin-Denfants PDFDocument41 pagesConception-Et Realisation-Dun-Site-Web-Pour-La-Gestion-Dun Jardin-Denfants PDFKalla AbdelkaderPas encore d'évaluation
- TP Correction Gestion-Des-DisquequotaDocument11 pagesTP Correction Gestion-Des-DisquequotaAbdel Adhim ChalouahPas encore d'évaluation
- Examen Principal Initiation Au CloudDocument3 pagesExamen Principal Initiation Au CloudFàroùk MànsourPas encore d'évaluation