Vous aimerez peut-être aussi
- TP SVMDocument7 pagesTP SVMmarwaPas encore d'évaluation
- Interrogation IADocument10 pagesInterrogation IAmatthieus701Pas encore d'évaluation
- Résumé Deep LearningDocument15 pagesRésumé Deep LearningACHRAF KADMIRIPas encore d'évaluation
- 2010 - Analyse en Composantes Principales - TutorielDocument7 pages2010 - Analyse en Composantes Principales - TutorielFranck DernoncourtPas encore d'évaluation
- 50 Heures de Formation Entre Python Et Intelligence ArtificielleDocument4 pages50 Heures de Formation Entre Python Et Intelligence ArtificielleNadou ShePas encore d'évaluation
- Chapitre 2Document63 pagesChapitre 2DUTERRAGE HugoPas encore d'évaluation
- Rapport TP3 - Deep LearningDocument8 pagesRapport TP3 - Deep LearningSoufiane BiggiPas encore d'évaluation
- Rapport SVM Yesmine AbdennadherDocument9 pagesRapport SVM Yesmine Abdennadheryesmine abdennadherPas encore d'évaluation
- Maîtrisez Les Possibilités Offertes Par Matplotlib - Découvrez Les Librairies Python Pour La Data ScienceDocument10 pagesMaîtrisez Les Possibilités Offertes Par Matplotlib - Découvrez Les Librairies Python Pour La Data ScienceDANHOUNDO RÉMIPas encore d'évaluation
- 8 Patrons Algorithmes Ac PDFDocument52 pages8 Patrons Algorithmes Ac PDFSerge AlainPas encore d'évaluation
- AlgorithmDocument6 pagesAlgorithmAbdallahi SidiPas encore d'évaluation
- K-Means - Fonctionnement Et Utilisation Dans Un Projet de Clustering PDFDocument10 pagesK-Means - Fonctionnement Et Utilisation Dans Un Projet de Clustering PDFelarrouchiPas encore d'évaluation
- RCPSPDocument29 pagesRCPSPbouchouichaPas encore d'évaluation
- TP4 MLDocument10 pagesTP4 MLWalid LahsikiPas encore d'évaluation
- TutoPython&KerasLesréseauxdeneurones-TutorielPython 1683742635968 PDFDocument23 pagesTutoPython&KerasLesréseauxdeneurones-TutorielPython 1683742635968 PDFkoudou EliePas encore d'évaluation
- DeeepDocument3 pagesDeeepthouraya hadj hassenPas encore d'évaluation
- Sans Nom 1Document13 pagesSans Nom 1Manuellah PekaPas encore d'évaluation
- Aa Progra Python 3 TH Exo Corr 20 21+++++++Document100 pagesAa Progra Python 3 TH Exo Corr 20 21+++++++naoufel charfeddinePas encore d'évaluation
- TP 2Document3 pagesTP 2Mariama DIOUFPas encore d'évaluation
- TP3 Mi204 Santos Scardellato Pimenta FRDocument17 pagesTP3 Mi204 Santos Scardellato Pimenta FRDoente PedroPas encore d'évaluation
- TD-MapReduce 02 2024Document3 pagesTD-MapReduce 02 2024Rihane FarahPas encore d'évaluation
- TP SVMDocument8 pagesTP SVMHanane KARDIPas encore d'évaluation
- Rapport Identifecation NaitaliDocument11 pagesRapport Identifecation NaitaliEl GhafraouiPas encore d'évaluation
- CSC 241 - AlgorithmiqueDocument9 pagesCSC 241 - AlgorithmiqueshabanabdoulatifPas encore d'évaluation
- TP Modèle Linéaire - PythonDocument6 pagesTP Modèle Linéaire - PythonMarwenCherifPas encore d'évaluation
- RAPPORT RegressionDocument14 pagesRAPPORT RegressionAmal TouhamiPas encore d'évaluation
- Bts Blanc Epd 2021Document3 pagesBts Blanc Epd 2021Martin TallaPas encore d'évaluation
- K Plus Proches Voisions K-Nearest Neighbors KNN: Mme Hiba Lahmer 2020/2021Document14 pagesK Plus Proches Voisions K-Nearest Neighbors KNN: Mme Hiba Lahmer 2020/2021Houssayen BenouhibaPas encore d'évaluation
- Projet PartielDocument5 pagesProjet PartieldungPas encore d'évaluation
- TP AlgoknnDocument12 pagesTP AlgoknnMath BLAIZOTPas encore d'évaluation
- Lda CRDocument10 pagesLda CRGhanem ToumiPas encore d'évaluation
- Lda CRDocument10 pagesLda CRGhanem ToumiPas encore d'évaluation
- Ajustements D'équations Non Linéaires, Un Tutoriel Avec Des Exemples MATLABDocument14 pagesAjustements D'équations Non Linéaires, Un Tutoriel Avec Des Exemples MATLABhitchcokmanPas encore d'évaluation
- FR Tanagra PCA New ToolsDocument16 pagesFR Tanagra PCA New ToolsEl Hadji NdoyePas encore d'évaluation
- TP3 IngSIDocument5 pagesTP3 IngSITEDx UniversitéCentralePas encore d'évaluation
- tp1 DeeplDocument5 pagestp1 DeeplDr. Chekir AmiraPas encore d'évaluation
- Chapitre2 PCADocument36 pagesChapitre2 PCAyosraghanmi23Pas encore d'évaluation
- La Classification Croisée Appliquée Aux Données Textuelles UsuellesDocument44 pagesLa Classification Croisée Appliquée Aux Données Textuelles UsuellesLucas IscoviciPas encore d'évaluation
- Tutorial PCA in RDocument29 pagesTutorial PCA in RHamza BoujemelPas encore d'évaluation
- TEXTDocument4 pagesTEXTAmir LehmamPas encore d'évaluation
- Définition Mathématique: Modifier Modifier Le CodeDocument9 pagesDéfinition Mathématique: Modifier Modifier Le CodeSabah SabahPas encore d'évaluation
- Le KNNDocument14 pagesLe KNNVan BabaPas encore d'évaluation
- TP3 DMDocument7 pagesTP3 DMHamdi GdhamiPas encore d'évaluation
- Supress I OnDocument57 pagesSupress I OnADAMSPas encore d'évaluation
- Analyse Des Structures Par Éléments FinisDocument46 pagesAnalyse Des Structures Par Éléments FinisEddehbiPas encore d'évaluation
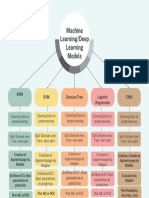
- Machine LearningDeep LearningDocument1 pageMachine LearningDeep Learningwadiâ AmaouiPas encore d'évaluation
- KNN - Découvrez Cet Algorithme de Machine Learning PDFDocument5 pagesKNN - Découvrez Cet Algorithme de Machine Learning PDFelarrouchiPas encore d'évaluation
- CC Machine LearningDocument7 pagesCC Machine LearningNaomie JenniferPas encore d'évaluation
- Exam Final-Big DataDocument3 pagesExam Final-Big DataFerdaous Hdioud100% (3)
- Cours - KNN - QKZKDocument9 pagesCours - KNN - QKZKGervais AzangaPas encore d'évaluation
- Rapport Use Case Smart GridDocument10 pagesRapport Use Case Smart Gridmalek chaariPas encore d'évaluation
- TPB03 C Recochiffres MasterSIDocument5 pagesTPB03 C Recochiffres MasterSIDjimramadji JosuéPas encore d'évaluation
- FR Tanagra LDA PythonDocument23 pagesFR Tanagra LDA PythonFako Sitcheu MichaelPas encore d'évaluation
- Apprentissage Automatique Semi - SuperviséDocument9 pagesApprentissage Automatique Semi - Supervisémichelone129925Pas encore d'évaluation
- Intelligence Artificielle Pour L'analyse de Donn Ees: Data PreprocessingDocument18 pagesIntelligence Artificielle Pour L'analyse de Donn Ees: Data PreprocessingEmmanuel MaximilienPas encore d'évaluation
- Gschwend Matthieu 3 Presentation 012023Document18 pagesGschwend Matthieu 3 Presentation 012023Sayoba GansanePas encore d'évaluation
- TP3: Déploiement Et Données Massives: Objectif(s)Document3 pagesTP3: Déploiement Et Données Massives: Objectif(s)EmmaPas encore d'évaluation
- TP4 ClassificationSupervisée StudentDocument11 pagesTP4 ClassificationSupervisée Studentmohamed anouar hassinePas encore d'évaluation
- Algorithmique 1Document181 pagesAlgorithmique 1Adrien PapsonPas encore d'évaluation
- Feuille Technique: Vitogas 050Document24 pagesFeuille Technique: Vitogas 050Oi69qEZPas encore d'évaluation
- CoursDocument93 pagesCoursPrincePas encore d'évaluation
- Cours Photoshop Avancé 2022Document1 pageCours Photoshop Avancé 2022Dnc Services100% (1)
- Exemple Document Conception AgileDocument4 pagesExemple Document Conception AgileAnouar AnassePas encore d'évaluation
- Rapport ToopooDocument10 pagesRapport Toopooazzhamza605Pas encore d'évaluation
- Simulation À Événements DiscretsDocument68 pagesSimulation À Événements DiscretsYassine YassinePas encore d'évaluation
- Chapitre 10 Correction Situation 3Document2 pagesChapitre 10 Correction Situation 3Juliana ThomasPas encore d'évaluation
- Caténaire Et Fils de ContactDocument12 pagesCaténaire Et Fils de ContactMhammedPas encore d'évaluation
- TD Electronique AnalogiqueDocument8 pagesTD Electronique AnalogiqueFreight FreightoPas encore d'évaluation
- Mode D'emploi D'une Étape: Temps LibreDocument1 pageMode D'emploi D'une Étape: Temps LibreOne Third Consulting AbroadPas encore d'évaluation
- Chap 2Document15 pagesChap 2benjunior ahmedPas encore d'évaluation
- Corrigé Analyse de Fabrication PF1 2019Document6 pagesCorrigé Analyse de Fabrication PF1 2019Dayang Dayang100% (4)
- Du Fini A Linfini PDFDocument3 pagesDu Fini A Linfini PDFwesh007Pas encore d'évaluation
- Tchaikovsky 5 II Horn Solo - Score and PartsDocument9 pagesTchaikovsky 5 II Horn Solo - Score and PartsAlisson PedrosoPas encore d'évaluation
- 2 WebServices 1upDocument86 pages2 WebServices 1updouina arouk100% (1)
- TP-production D'eau ChaudeDocument15 pagesTP-production D'eau ChaudeFatna BelabbesPas encore d'évaluation
- IntroductioN Au Système GNU PDFDocument37 pagesIntroductioN Au Système GNU PDFSteve Loïc NGANDAPas encore d'évaluation
- Présentation ACE6000 Français ONEDocument29 pagesPrésentation ACE6000 Français ONECHAHLI YounesPas encore d'évaluation
- CH MemoiresDocument71 pagesCH MemoiresN El kechaiPas encore d'évaluation
- Stages Et Pfe Book Ey 2022 2023Document120 pagesStages Et Pfe Book Ey 2022 2023Saif WarradiPas encore d'évaluation
- Limite D - Une Suite NumériqueDocument2 pagesLimite D - Une Suite NumériqueSanae SanonaPas encore d'évaluation
- Convocation TCF CANADA - Epreuves Sur OrdinateurDocument1 pageConvocation TCF CANADA - Epreuves Sur OrdinateurBill TaguigPas encore d'évaluation
- Audit Energétique ISO 50001 SOCOTEC 30 06 2015Document39 pagesAudit Energétique ISO 50001 SOCOTEC 30 06 2015ESSALIM ABDELHAKIMPas encore d'évaluation
- Plan de Montage Du Contrepoids - Stacker L21ST01 - Cbmi - 20122022 PDFDocument6 pagesPlan de Montage Du Contrepoids - Stacker L21ST01 - Cbmi - 20122022 PDFHa Kim BJPas encore d'évaluation
- Processus UnifiéDocument10 pagesProcessus UnifiéGaSton MazrouiPas encore d'évaluation
- WCM Questions and AnswersDocument26 pagesWCM Questions and Answersameer meerPas encore d'évaluation
- Cours AcpDocument18 pagesCours AcpHochi MimiPas encore d'évaluation
- Garniture Mécanique Double: Notice de Service ComplémentaireDocument12 pagesGarniture Mécanique Double: Notice de Service ComplémentaireDENOUPas encore d'évaluation
- Cahier Des Charges Relatif À La Mise en Place D'un Dispositif de VeilleDocument7 pagesCahier Des Charges Relatif À La Mise en Place D'un Dispositif de VeilleFatnassi KaisPas encore d'évaluation
- TP Fouotsap Et Pesdjock ProfesseurDocument16 pagesTP Fouotsap Et Pesdjock ProfesseurBoris FouotsapPas encore d'évaluation
- Les 10 Secrets pour une Vie Plus Heureuse avec la Maladie de ParkinsonD'EverandLes 10 Secrets pour une Vie Plus Heureuse avec la Maladie de ParkinsonPas encore d'évaluation