Vous aimerez peut-être aussi
- Atelier Système D'exploitation UNIXLINUXDocument5 pagesAtelier Système D'exploitation UNIXLINUXFarah BeltaiefPas encore d'évaluation
- Cours Acoustique Page 31-65Document36 pagesCours Acoustique Page 31-65flokiPas encore d'évaluation
- Evol 3G & CdmaDocument35 pagesEvol 3G & CdmaNassim GafsiPas encore d'évaluation
- SystemTR Part1Document76 pagesSystemTR Part1Bîlâl ChabiraPas encore d'évaluation
- Cryptographie QuantiqueDocument46 pagesCryptographie Quantiquebenaouda310% (1)
- 004 Amlz Et Amhz FR 2019Document28 pages004 Amlz Et Amhz FR 2019sebicapilneanPas encore d'évaluation
- TP 3 Lubrification TitreDocument16 pagesTP 3 Lubrification TitreInass HaddaPas encore d'évaluation
- Chapitre 3 Fonctions Et ModulesDocument20 pagesChapitre 3 Fonctions Et ModulesHamoud MedPas encore d'évaluation
- Les Outils Du Maçon - Le Guide de La MaçonnerieDocument8 pagesLes Outils Du Maçon - Le Guide de La MaçonnerieAdouPas encore d'évaluation
- Micro Interrogation 3 Hakima LachgarDocument4 pagesMicro Interrogation 3 Hakima Lachgarkima lachgarPas encore d'évaluation
- Chap2 - Machine FrigorifiqueDocument3 pagesChap2 - Machine FrigorifiqueGhizlanePas encore d'évaluation
- Diagrame Faw Xiali 1.1 by MR Djalal 2021Document3 pagesDiagrame Faw Xiali 1.1 by MR Djalal 2021Cherifi Mouffaq100% (2)
- Tutoriel Etablissements Origine Adele FRDocument7 pagesTutoriel Etablissements Origine Adele FRPamela TitoPas encore d'évaluation
- Nul BesoinDocument3 pagesNul Besoinbertin kaborePas encore d'évaluation
- Vue D'ensemble Du ModèleDocument2 pagesVue D'ensemble Du ModèleAnas OuasmiPas encore d'évaluation
- La Difference Entre Foward Et Redirection en JSPDocument7 pagesLa Difference Entre Foward Et Redirection en JSPalaeben2002Pas encore d'évaluation
- Le Référentiel Du COSODocument3 pagesLe Référentiel Du COSOMohammed Amine MouloudPas encore d'évaluation
- 4 Comprendre Les Examens PDFDocument15 pages4 Comprendre Les Examens PDFkhouloud haddadPas encore d'évaluation
- Mini Projet EmbarqueDocument8 pagesMini Projet EmbarqueKhalil JbeliPas encore d'évaluation
- Examen Kali LINUX Semestre 2 (2020-2021)Document8 pagesExamen Kali LINUX Semestre 2 (2020-2021)Brazza In My VeinsPas encore d'évaluation
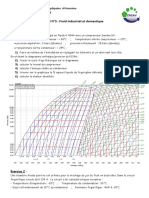
- TD 5 - FroidDocument3 pagesTD 5 - Froidi s67% (3)
- Montaje FC TOUCH (Fra) 060318Document68 pagesMontaje FC TOUCH (Fra) 060318AlexanderHuarcayaPas encore d'évaluation
- Polycope Hydraulique GI 2017 2Document77 pagesPolycope Hydraulique GI 2017 2ahmed belmadaniPas encore d'évaluation
- FR CLAD Sample Exam 1 FRDocument21 pagesFR CLAD Sample Exam 1 FRISSAM ENNABIHPas encore d'évaluation
- Traitement de Texte Exercices Non Corriges 2Document2 pagesTraitement de Texte Exercices Non Corriges 2ZAHRA FASKA100% (2)
- Optimisation Espace Stockage Vertical Marsa MarocDocument4 pagesOptimisation Espace Stockage Vertical Marsa MarocCalebtallaPas encore d'évaluation
- Activité 5.1Document3 pagesActivité 5.1Fatima zahra SabbarPas encore d'évaluation
- Publication 39Document1 pagePublication 39zanazePas encore d'évaluation
- Fiche Technique ChevilleDocument9 pagesFiche Technique Chevillejoker63000Pas encore d'évaluation
- ThymeleafDocument104 pagesThymeleafHatem MoallaPas encore d'évaluation