Vous aimerez peut-être aussi
- Transformation du radon: Dévoiler des modèles cachés dans les données visuellesD'EverandTransformation du radon: Dévoiler des modèles cachés dans les données visuellesPas encore d'évaluation
- Agenda Rosada Secretaria 1Document304 pagesAgenda Rosada Secretaria 1manuelrojasPas encore d'évaluation
- Zorro TribalDocument398 pagesZorro TribalCatherine Santibáñez SeguraPas encore d'évaluation
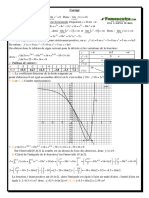
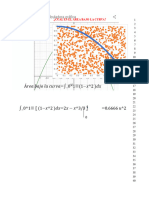
- 6129fe0cb9c85corrige Probleme 1 Etude D Une Fonction ExponentieDocument1 page6129fe0cb9c85corrige Probleme 1 Etude D Une Fonction ExponentiegbamhurbainPas encore d'évaluation
- Crampons Plaqueur: Devoir de Synthèse N°1Document6 pagesCrampons Plaqueur: Devoir de Synthèse N°1Nadia SahliPas encore d'évaluation
- PsicologoDocument673 pagesPsicologoCloset BiafPas encore d'évaluation
- Bobcat TH Első HídDocument12 pagesBobcat TH Első HídKároly VighPas encore d'évaluation
- Crossword AnimalDocument2 pagesCrossword AnimalWahcita Septiana SariPas encore d'évaluation
- Planos Hidraulicos - Raptor 55 2R - JMC-529Document10 pagesPlanos Hidraulicos - Raptor 55 2R - JMC-529jose velascoPas encore d'évaluation
- Denny ModelDocument1 pageDenny ModelTofu Winter3Pas encore d'évaluation
- Dua 2Document1 pageDua 2Marek ProchádzkaPas encore d'évaluation
- Keolis Depliant Mont ST Michel 10X21 PDFDocument2 pagesKeolis Depliant Mont ST Michel 10X21 PDFMarcus UlpiusPas encore d'évaluation
- Arts Crafts Spiderman FRDocument6 pagesArts Crafts Spiderman FRolivierPas encore d'évaluation
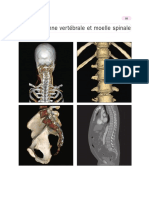
- 2 - Colonne Vert Brale Et Moelle S - 2011 - Anatomie Du Corps Humain - Atlas D IDocument12 pages2 - Colonne Vert Brale Et Moelle S - 2011 - Anatomie Du Corps Humain - Atlas D IREKIKPas encore d'évaluation
- Planos Hidraulicos - JMC-827Document10 pagesPlanos Hidraulicos - JMC-827Cinthia EspinozaPas encore d'évaluation
- Reduct Axes ConcDocument1 pageReduct Axes Concwissal khammeriPas encore d'évaluation
- PASSERELLEDocument1 pagePASSERELLEysgmn6z4vtPas encore d'évaluation
- Null 14 PDFDocument1 pageNull 14 PDFBamory BambaPas encore d'évaluation
- 2023-2024-primaireDocument1 page2023-2024-primairemauudewPas encore d'évaluation
- Tờ Số 3 - Bản Vẽ Sơ Đồ Nguyên LýDocument1 pageTờ Số 3 - Bản Vẽ Sơ Đồ Nguyên LýThành Hiệp LêPas encore d'évaluation
- 7 Monthly Work Schedule Excel Template FRDocument61 pages7 Monthly Work Schedule Excel Template FRRICHARD KISIATIPas encore d'évaluation
- Planos Hidraulicos JMC-964Document10 pagesPlanos Hidraulicos JMC-964JosuePas encore d'évaluation
- Planos Hidraulico Bolter 99 JMC-729Document12 pagesPlanos Hidraulico Bolter 99 JMC-729Hector Quispe De La TorrePas encore d'évaluation
- Planos Hidraulico Bolter 99 - JMC-733Document12 pagesPlanos Hidraulico Bolter 99 - JMC-733Jesus Pardo SalasPas encore d'évaluation
- Crossword Puzzle Numbers Crosswords Fun Activities Games Oneonone Activitie 30533Document1 pageCrossword Puzzle Numbers Crosswords Fun Activities Games Oneonone Activitie 30533Carla DalmasPas encore d'évaluation
- Day 6 - Number 0-100Document2 pagesDay 6 - Number 0-100Nguyễn Thị Thùy DungPas encore d'évaluation
- Kuis1 0620103004Document10 pagesKuis1 0620103004Bimota AresPas encore d'évaluation
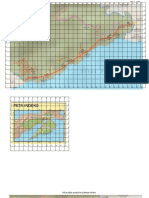
- Peta Desa HUNUTHDocument4 pagesPeta Desa HUNUTHFajria SindayaniPas encore d'évaluation
- Poznajemy-Dzielenie-8 KLASA 2Document1 pagePoznajemy-Dzielenie-8 KLASA 2polskizplusemPas encore d'évaluation
- CC - Harmoniser Un Thème DoMaj - EtudiantDocument1 pageCC - Harmoniser Un Thème DoMaj - EtudiantGARCIAPas encore d'évaluation
- Praktikum 2 GulmaDocument6 pagesPraktikum 2 GulmaRowilson Tamado BanureaPas encore d'évaluation
- PREDIOS UnaDocument7 pagesPREDIOS UnaByron Alejandro Parra MandujanoPas encore d'évaluation
- Planos Hidraulicos - JMC-1044Document10 pagesPlanos Hidraulicos - JMC-1044Rodrigo ArzapaloPas encore d'évaluation
- Ejemplo Laboratorio en ClaseDocument83 pagesEjemplo Laboratorio en ClaseAdrian Dario Muñoz UrrutiaPas encore d'évaluation
- Purple NotebookDocument327 pagesPurple NotebookFlorinela PopaPas encore d'évaluation
- Crossword GardeningDocument2 pagesCrossword GardeningWahcita Septiana SariPas encore d'évaluation
- Broyeur Capot Protection Courroie 1972004Document2 pagesBroyeur Capot Protection Courroie 1972004Alain BersonnetPas encore d'évaluation
- Hotel Basement 2Document1 pageHotel Basement 2AshiPas encore d'évaluation
- Plano Hidraulico - JMC-803Document12 pagesPlano Hidraulico - JMC-803Miguel RomoPas encore d'évaluation
- Planos Hidraulicos - Bolter 99 - JMC-777Document11 pagesPlanos Hidraulicos - Bolter 99 - JMC-777mauricioPas encore d'évaluation
- Taller 1 ProbDocument9 pagesTaller 1 ProbIVAN SEBASTIAN VARGAS NARANJOPas encore d'évaluation
- Classeur 1Document6 pagesClasseur 1amal tahirPas encore d'évaluation
- Crossword Puzzle NumbersDocument1 pageCrossword Puzzle Numbersrodrigoreis.dchivPas encore d'évaluation
- Aplicatie Statistica6 1Document13 pagesAplicatie Statistica6 1mirelachePas encore d'évaluation
- Planos Hidraulicos - Muki LHBP - Jmc-524Document8 pagesPlanos Hidraulicos - Muki LHBP - Jmc-524miguel lopezPas encore d'évaluation
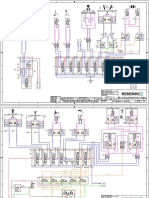
- Schéma Électrique Enrouleuse Électrique CAPÉDocument1 pageSchéma Électrique Enrouleuse Électrique CAPÉReid AllawayPas encore d'évaluation
- PixelDocument3 pagesPixelMyk MykPas encore d'évaluation
- BTC SiteDocument1 pageBTC SiteRajab SalhubPas encore d'évaluation
- Ih24h 1carm SRM PDFDocument1 pageIh24h 1carm SRM PDFramzichak7089Pas encore d'évaluation
- Itungan Drying Silinder Pejal FixxxDocument16 pagesItungan Drying Silinder Pejal FixxxTbx IyanPas encore d'évaluation
- Devoir1-Econométrie 1Document1 pageDevoir1-Econométrie 1najwa joubairiPas encore d'évaluation
- Barre de Coupe Rabatteur 1932177Document3 pagesBarre de Coupe Rabatteur 1932177Alain BersonnetPas encore d'évaluation
- Print Head Epson PLQ20Document4 pagesPrint Head Epson PLQ20Muhammad FakhruddinPas encore d'évaluation
- 2semestre L2 FB 2021-2022 - 221025 - 163925Document13 pages2semestre L2 FB 2021-2022 - 221025 - 163925Sylvie RamazaniPas encore d'évaluation
- Plan VRDDocument13 pagesPlan VRDJulien Koku Elom AWOPas encore d'évaluation
- Unnatural Selection InterludioDocument2 pagesUnnatural Selection InterludiokillokenzPas encore d'évaluation
- PtarDocument1 pagePtarFranlen VilchezPas encore d'évaluation
- 6TH Grade Practice Activity #1 Crossword-Puzzle-NumbersDocument1 page6TH Grade Practice Activity #1 Crossword-Puzzle-NumbersJessica RamirezPas encore d'évaluation
- Mi Ro Sojka T815Document3 pagesMi Ro Sojka T815Bá Ngọc Kiều LêPas encore d'évaluation
- Modele Gratuit DevisDocument2 pagesModele Gratuit DevisZaka RiaPas encore d'évaluation
- Fichier Declaration CNPS 2023Document3 pagesFichier Declaration CNPS 2023sieminan thomas d'aquinPas encore d'évaluation
- Appel A Candidature Chef de ProjetDocument2 pagesAppel A Candidature Chef de ProjetCezar DiedhiouPas encore d'évaluation
- Audit Marche GuinéeDocument75 pagesAudit Marche GuinéeCwassibley Sostherne JokenPas encore d'évaluation
- Enoncé Examen National Session Normale 20114Document4 pagesEnoncé Examen National Session Normale 20114Ali Janati IdrissiPas encore d'évaluation
- Suggestion en Matière de Questions À Poser Lors de Laudit QualitéDocument2 pagesSuggestion en Matière de Questions À Poser Lors de Laudit QualitéWahab HananiPas encore d'évaluation
- Analyse SWOTDocument11 pagesAnalyse SWOTmarwaPas encore d'évaluation
- Séance 1,2 2017 PDFDocument27 pagesSéance 1,2 2017 PDFSaad GhoummidPas encore d'évaluation
- Guide Open ConcertoDocument28 pagesGuide Open ConcertoSalim Daouda Hamani0% (1)
- 0349 Memoire Morel Desma 08Document80 pages0349 Memoire Morel Desma 08Meryem AzPas encore d'évaluation
- LicenceDocument45 pagesLicenceRobins GoutonPas encore d'évaluation
- Elements de Correction Examen de Passage 2014 Gestion Des Entreprises Tsge Synthese 1 OfpptDocument7 pagesElements de Correction Examen de Passage 2014 Gestion Des Entreprises Tsge Synthese 1 OfpptjfkfPas encore d'évaluation
- BuromaDocument13 pagesBuromaabirPas encore d'évaluation
- Les Amortissements 1Document8 pagesLes Amortissements 1Youssef IggoutPas encore d'évaluation
- Fiche Pratique Accords Cadres PDFDocument3 pagesFiche Pratique Accords Cadres PDFradoniainaPas encore d'évaluation
- Amélioration Zone AssemblageDocument55 pagesAmélioration Zone AssemblageYoussef KhaliPas encore d'évaluation
- 3.methodologie VoirieDocument27 pages3.methodologie VoiriealvaresnoubaPas encore d'évaluation
- CLEARSTONE - 14535 - Industrie Pharmaceutique, Chimique Et Cosmetique - FRDocument20 pagesCLEARSTONE - 14535 - Industrie Pharmaceutique, Chimique Et Cosmetique - FRKarim MeddebPas encore d'évaluation
- PantinDocument12 pagesPantinMarie Sarazin-DuboeufPas encore d'évaluation
- Les Acteurs Publics Du Droit Du Commerce InternationalDocument79 pagesLes Acteurs Publics Du Droit Du Commerce InternationalAniss Yaniss100% (6)
- Tableau de Bord de Suivi Des AccidentsDocument45 pagesTableau de Bord de Suivi Des Accidentsthouraya hsanPas encore d'évaluation
- Fiscalite Des Entreprises Etrangeres Au Maroc DFDocument25 pagesFiscalite Des Entreprises Etrangeres Au Maroc DFhoussine546Pas encore d'évaluation