Vous aimerez peut-être aussi
- Jason Statham Est Né Le 12 Septembre 1967Document1 pageJason Statham Est Né Le 12 Septembre 1967Valeriu CovalciucPas encore d'évaluation
- Gestion Demploi Du Temps Des SoutenancesDocument39 pagesGestion Demploi Du Temps Des Soutenancesachref bouadilaPas encore d'évaluation
- Solution Examen TelephonieDocument3 pagesSolution Examen Telephoniehadjer100% (2)
- Algo. D'app. Automatique - CopieDocument5 pagesAlgo. D'app. Automatique - CopieLasmer ChadiPas encore d'évaluation
- Réseau Neuronal Recurrent "Recurrent Neural Network" (RNN)Document9 pagesRéseau Neuronal Recurrent "Recurrent Neural Network" (RNN)kasmi zoubeirPas encore d'évaluation
- Séance 5 - Réseaux de Neurones 21 Avril 2014Document30 pagesSéance 5 - Réseaux de Neurones 21 Avril 2014ayoubhaouasPas encore d'évaluation
- AlgorithmDocument6 pagesAlgorithmAbdallahi SidiPas encore d'évaluation
- Micro GridDocument7 pagesMicro Gride4201Pas encore d'évaluation
- Chapitre 2Document63 pagesChapitre 2DUTERRAGE HugoPas encore d'évaluation
- Rapport Use Case Smart GridDocument10 pagesRapport Use Case Smart Gridmalek chaariPas encore d'évaluation
- TutoPython&KerasLesréseauxdeneurones-TutorielPython 1683742635968 PDFDocument23 pagesTutoPython&KerasLesréseauxdeneurones-TutorielPython 1683742635968 PDFkoudou EliePas encore d'évaluation
- Commande NeuronalDocument15 pagesCommande NeuronalÑo ÑaměPas encore d'évaluation
- Exposé PMCDocument6 pagesExposé PMCAssad DaviesPas encore d'évaluation
- APznzaahOLeMI2KTJc2BZ8PzV1qKFyUlHqpIIFNpFP5-eYyChj5CAx0fU6FNtbJyjjMGtDPGWyhvGHvRO1ynkxR7JCue9fQVklzm2HI5xxfAfl6tYBODa83HYhzLClL RbKikL1fWFxNlUkmIjMrSURQuDjjHwMNGpYHJlUo3wlLAeuhe4uzrUa8P0JupEoMCyUDDocument27 pagesAPznzaahOLeMI2KTJc2BZ8PzV1qKFyUlHqpIIFNpFP5-eYyChj5CAx0fU6FNtbJyjjMGtDPGWyhvGHvRO1ynkxR7JCue9fQVklzm2HI5xxfAfl6tYBODa83HYhzLClL RbKikL1fWFxNlUkmIjMrSURQuDjjHwMNGpYHJlUo3wlLAeuhe4uzrUa8P0JupEoMCyUDGhassen OrfPas encore d'évaluation
- Algorithmeknn 121213175830 Phpapp02Document14 pagesAlgorithmeknn 121213175830 Phpapp02SioudaPas encore d'évaluation
- Tps Data Mining (Matlab)Document14 pagesTps Data Mining (Matlab)Mohammed Amine Halbaba100% (10)
- TP AlgoknnDocument12 pagesTP AlgoknnMath BLAIZOTPas encore d'évaluation
- TP 6 Algorithme KNNDocument7 pagesTP 6 Algorithme KNNBaha BechikhPas encore d'évaluation
- TP 6 Algorithme KNNDocument7 pagesTP 6 Algorithme KNNBaha BechikhPas encore d'évaluation
- Le Perceptron Multicouche Back PropagationDocument17 pagesLe Perceptron Multicouche Back PropagationFatima AbdiPas encore d'évaluation
- Cours PerceptronDocument58 pagesCours PerceptrongraPas encore d'évaluation
- IATIC4 FBC CM2 v1.0Document24 pagesIATIC4 FBC CM2 v1.0classic.boy211Pas encore d'évaluation
- 1er Partiel De-Wps Office-4Document7 pages1er Partiel De-Wps Office-4markov dadavodounPas encore d'évaluation
- Révision Théorie-Dérrière Les Applications TPDocument8 pagesRévision Théorie-Dérrière Les Applications TPTray MinaPas encore d'évaluation
- TP3 Apprentissage Supervisé Par La ClassificationDocument2 pagesTP3 Apprentissage Supervisé Par La Classificationtoufikhamzaoui.05thPas encore d'évaluation
- Les Principes de Base de Réseaux de Neurones ArtificielsDocument5 pagesLes Principes de Base de Réseaux de Neurones Artificielsw.aissaouiPas encore d'évaluation
- Définition: Les Principes de Base de Réseaux de Neurones ArtificielsDocument3 pagesDéfinition: Les Principes de Base de Réseaux de Neurones Artificielsw.aissaouiPas encore d'évaluation
- Reseau NeroneDocument22 pagesReseau NeroneMohamed Amine Bougria100% (2)
- Data Mining Cours 7Document39 pagesData Mining Cours 7Salem AmiratPas encore d'évaluation
- I3 Algorithmique Parallele 1Document12 pagesI3 Algorithmique Parallele 1amazoz abdouPas encore d'évaluation
- Chap 3Document19 pagesChap 3Abdelfatah FerhatPas encore d'évaluation
- Projet de Machine Learning KDocument31 pagesProjet de Machine Learning KNaomie Jennifer100% (1)
- ClassificationDocument10 pagesClassificationAndré Cédric BessalaPas encore d'évaluation
- Rapport TP4 Deep LearningDocument12 pagesRapport TP4 Deep LearningSoufiane BiggiPas encore d'évaluation
- Rick - Trame de Recherche Sur Le Projet IA SantéDocument7 pagesRick - Trame de Recherche Sur Le Projet IA Santémahernajar87Pas encore d'évaluation
- Support de Cours - Deep Learning-Chapitre3-CnnDocument8 pagesSupport de Cours - Deep Learning-Chapitre3-Cnnkika boubaPas encore d'évaluation
- Résumé Deep LearningDocument15 pagesRésumé Deep LearningACHRAF KADMIRIPas encore d'évaluation
- RapportDocument16 pagesRapportFät MãPas encore d'évaluation
- Complexity Diagostic of Training Curves Interpretability Metrics of PerformanceDocument97 pagesComplexity Diagostic of Training Curves Interpretability Metrics of Performancesharifbadini07Pas encore d'évaluation
- Trait ImageDocument16 pagesTrait ImageBin ZhangPas encore d'évaluation
- 3-Big Data Exercices ISIA Partie 2 Centrale Dec2018 Janv 2019Document88 pages3-Big Data Exercices ISIA Partie 2 Centrale Dec2018 Janv 2019zaki nygmaPas encore d'évaluation
- Interprétation BenoudjitDocument4 pagesInterprétation Benoudjitsabdelmalek785Pas encore d'évaluation
- Tp1 Jia SiranDocument10 pagesTp1 Jia SiranMaryam JavadiPas encore d'évaluation
- ST M App RNDocument28 pagesST M App RNSohib LoudadjiPas encore d'évaluation
- 04 - Les Reseaux de Neurones Formels Pour Le Pilotage de Robots MobilesDocument11 pages04 - Les Reseaux de Neurones Formels Pour Le Pilotage de Robots MobilesDOTSYS DevPas encore d'évaluation
- Présentation Pfe Beciri SemraniDocument36 pagesPrésentation Pfe Beciri SemraniAdafer AdaferPas encore d'évaluation
- Cours RNNDocument28 pagesCours RNNKen ZaPas encore d'évaluation
- Algorithme Machine LearngDocument16 pagesAlgorithme Machine LearngYayaPas encore d'évaluation
- Traitement de ImagesDocument9 pagesTraitement de ImagesMohamed MidoPas encore d'évaluation
- TP 5 Les Reseaux de Neurones ArtificielsDocument6 pagesTP 5 Les Reseaux de Neurones ArtificielsBaha BechikhPas encore d'évaluation
- TP 2Document3 pagesTP 2Mariama DIOUFPas encore d'évaluation
- Les Reseaux de NeuronesDocument3 pagesLes Reseaux de Neuronesgha0% (1)
- K Plus Proches Voisions K-Nearest Neighbors KNN: Mme Hiba Lahmer 2020/2021Document14 pagesK Plus Proches Voisions K-Nearest Neighbors KNN: Mme Hiba Lahmer 2020/2021Houssayen BenouhibaPas encore d'évaluation
- Perceptron Multicouche RicheDocument7 pagesPerceptron Multicouche RicheBilou Mender100% (1)
- Leçon5 KNNDocument10 pagesLeçon5 KNNOthmane Rais100% (1)
- C'est Quoi Le CNNDocument20 pagesC'est Quoi Le CNNManuelPas encore d'évaluation
- Algorithmique FST 2023Document70 pagesAlgorithmique FST 2023L'empereur DarkalexPas encore d'évaluation
- Elaboration D'un Système Hybride Neuro-Génétique Pour Le Diagnostic MédicalDocument10 pagesElaboration D'un Système Hybride Neuro-Génétique Pour Le Diagnostic MédicalJacob ChalPas encore d'évaluation
- Chapitre2 PCADocument36 pagesChapitre2 PCAyosraghanmi23Pas encore d'évaluation
- Rapport OIA PDFDocument6 pagesRapport OIA PDFHacene DjaberPas encore d'évaluation
- CC Machine LearningDocument7 pagesCC Machine LearningNaomie JenniferPas encore d'évaluation
- Théorie Des Mécanismes - 04Document24 pagesThéorie Des Mécanismes - 04baazizw1Pas encore d'évaluation
- MANGOLINI MarcDocument183 pagesMANGOLINI MarcLasmer ChadiPas encore d'évaluation
- Atelier5 mongoDBDocument1 pageAtelier5 mongoDBLasmer ChadiPas encore d'évaluation
- Les Techniques de Collecte de DonnéesDocument3 pagesLes Techniques de Collecte de DonnéesLasmer ChadiPas encore d'évaluation
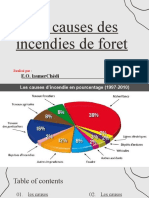
- Les Causes Des Incendies Des ForetsDocument5 pagesLes Causes Des Incendies Des ForetsLasmer ChadiPas encore d'évaluation
- Kaabi 2020toul0017Document93 pagesKaabi 2020toul0017Lasmer ChadiPas encore d'évaluation
- Les Causes Des Incendies de ForetDocument26 pagesLes Causes Des Incendies de ForetLasmer ChadiPas encore d'évaluation
- APIA 2017 Paper 8Document8 pagesAPIA 2017 Paper 8benn yassPas encore d'évaluation
- Algo. D'app. AutomatiqueDocument1 pageAlgo. D'app. AutomatiqueLasmer ChadiPas encore d'évaluation
- Supply Chain Management 1Document7 pagesSupply Chain Management 1Walid El BourakkadiPas encore d'évaluation
- Sns FR SMC Guide D Administration v2.8.1Document121 pagesSns FR SMC Guide D Administration v2.8.1Denis OuPas encore d'évaluation
- Brochure Business Communications FR 1Document10 pagesBrochure Business Communications FR 1David DecerfPas encore d'évaluation
- La Technologie Blockchain Et Les Smart Contrats - Facteurs D'évolutions de La Finance Islamique - Etude Prospective Sur Les Banques AlgeriennesDocument14 pagesLa Technologie Blockchain Et Les Smart Contrats - Facteurs D'évolutions de La Finance Islamique - Etude Prospective Sur Les Banques Algeriennesmetaoui100% (1)
- Tuo HTML - Css Site Du ZeroDocument151 pagesTuo HTML - Css Site Du ZerosondurPas encore d'évaluation
- Cours Robotique 2014 PDFDocument143 pagesCours Robotique 2014 PDFKim JkPas encore d'évaluation
- Applicationj Web de Gestion Des Réclamations Et Des Incidents - Ahmed KADMIRIDocument48 pagesApplicationj Web de Gestion Des Réclamations Et Des Incidents - Ahmed KADMIRIImane LagmiriPas encore d'évaluation
- Reactjs, Maîtriser Le Framework Javascript de Facebook: Cours Pratique de 3 Jours Réf: Tjs - Prix 2022: 2 050 HTDocument3 pagesReactjs, Maîtriser Le Framework Javascript de Facebook: Cours Pratique de 3 Jours Réf: Tjs - Prix 2022: 2 050 HTchatti SamiPas encore d'évaluation
- TD1Document2 pagesTD1brahim tzgPas encore d'évaluation
- Corrigé Type Examen Module SE1 Univ Tlemcen Promo 2015-2016Document7 pagesCorrigé Type Examen Module SE1 Univ Tlemcen Promo 2015-2016Wich RiverPas encore d'évaluation
- Exercices de RévisionsDocument3 pagesExercices de Révisionsdbmariem8Pas encore d'évaluation
- Chapitre 12 Les Threads: 1. ProcessusDocument12 pagesChapitre 12 Les Threads: 1. ProcessusYoussef OuassouPas encore d'évaluation
- Exercices Bus CAN Mod PDFDocument7 pagesExercices Bus CAN Mod PDFNarutoPas encore d'évaluation
- Protocols Utilise Avec Simatic Iot 2040Document2 pagesProtocols Utilise Avec Simatic Iot 2040kardous saif eddinePas encore d'évaluation
- Java Poo TP1Document2 pagesJava Poo TP1Omaima LyousfiPas encore d'évaluation
- MESSIR WIS Admin Manual 6f21f070Document75 pagesMESSIR WIS Admin Manual 6f21f070papa babacar DiagnePas encore d'évaluation
- Compte Rendu Système D'alarmeDocument11 pagesCompte Rendu Système D'alarmeAnass AMMARPas encore d'évaluation
- Projet Elec Max Dernier VuDocument28 pagesProjet Elec Max Dernier VuMaxime MaarekPas encore d'évaluation
- Livre BlancDocument22 pagesLivre BlanckhaireddinePas encore d'évaluation
- Récépissé de Dépôt D'une Déclaration PréalableDocument22 pagesRécépissé de Dépôt D'une Déclaration PréalableLaura Cédric BresPas encore d'évaluation
- COURS Analyse Numérique Nantes PDFDocument135 pagesCOURS Analyse Numérique Nantes PDFDjedidi Med RiadhPas encore d'évaluation
- CoursIGchap1 PDFDocument187 pagesCoursIGchap1 PDFweedxcfPas encore d'évaluation
- Cours2 - MS DOSDocument21 pagesCours2 - MS DOSAss ia100% (1)
- CV Maintenance Informatique JuniorDocument1 pageCV Maintenance Informatique JuniortPas encore d'évaluation
- Fonctions DAX de Power PivotDocument85 pagesFonctions DAX de Power PivotNoradine SAIDALI100% (1)
- Tp Mouvement Plan Incline CamionDocument5 pagesTp Mouvement Plan Incline CamionAhmed Ben YoussefPas encore d'évaluation
- K2 Scada 20130227 - FraDocument46 pagesK2 Scada 20130227 - Franabil softPas encore d'évaluation