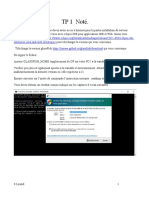
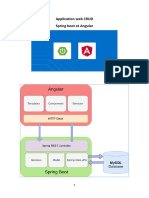
Vous aimerez peut-être aussi
- Réalisation D'un Microprocesseur Avec LogisimDocument22 pagesRéalisation D'un Microprocesseur Avec Logisimyoucef moualkiaPas encore d'évaluation
- Zoncare-Q3 FRDocument4 pagesZoncare-Q3 FRd_abdos67% (3)
- TP N°5 - Devpt - Web - Coté - ServeurDocument3 pagesTP N°5 - Devpt - Web - Coté - Serveurnawel amaraPas encore d'évaluation
- La Fonction AttrDocument5 pagesLa Fonction AttrBenny BavPas encore d'évaluation
- Cours AjaxDocument36 pagesCours AjaxIlyass HalimiPas encore d'évaluation
- Api HTML5Document12 pagesApi HTML5ovesmichelPas encore d'évaluation
- TP Composants Java ME - Java EE. Le Serveur GereCompteBancaireServletDocument7 pagesTP Composants Java ME - Java EE. Le Serveur GereCompteBancaireServletOUMAIMA ELMEJGARIPas encore d'évaluation
- Utilisation Du Crochet D'effetDocument12 pagesUtilisation Du Crochet D'effetskittouPas encore d'évaluation
- Chapitre05 - Seance02 - Créer Un Servelet BonDocument6 pagesChapitre05 - Seance02 - Créer Un Servelet BonBrayann DiePas encore d'évaluation
- Comment Devélopper Une Application Basée Sur La Blockchain Ethereum Et VueJS Mise A JourDocument19 pagesComment Devélopper Une Application Basée Sur La Blockchain Ethereum Et VueJS Mise A Jourfatoumata konePas encore d'évaluation
- React Redux Tutoriel 1Document9 pagesReact Redux Tutoriel 1hachemfstPas encore d'évaluation
- TP Serv LetsDocument21 pagesTP Serv LetsIsmail IfakirPas encore d'évaluation
- PromessesDocument4 pagesPromessesYesmine MakkesPas encore d'évaluation
- Cours 5 React - 2ème PartieDocument27 pagesCours 5 React - 2ème PartiesunnyblueproPas encore d'évaluation
- WebservletDocument46 pagesWebservlethafsa ladhassePas encore d'évaluation
- TP1 IhmDocument6 pagesTP1 IhmAmira JbaraPas encore d'évaluation
- TP Servlet 2010Document11 pagesTP Servlet 2010Zakaria IgarramenPas encore d'évaluation
- Cours JEE 4Document27 pagesCours JEE 4Dorsaf Ben AlayaPas encore d'évaluation
- LOG660 Labo2 ServletsDocument9 pagesLOG660 Labo2 ServletsKingofrai AbdelPas encore d'évaluation
- Langage InformatiqueDocument37 pagesLangage InformatiqueStachis MadiambaPas encore d'évaluation
- Mise en Place D'une API Rest Avec SpringDocument6 pagesMise en Place D'une API Rest Avec Springjean rudelPas encore d'évaluation
- AndroidDocument11 pagesAndroidméthode RMarcPas encore d'évaluation
- Gestion Des ErreursDocument13 pagesGestion Des ErreursAngele NguiakamPas encore d'évaluation
- Tp2jee 2023Document22 pagesTp2jee 2023azouzimohamed068Pas encore d'évaluation
- JavascriptDocument67 pagesJavascriptSerge OngoloPas encore d'évaluation
- React Cours Intensif 2020Document90 pagesReact Cours Intensif 2020Philippe ARRASPas encore d'évaluation
- JavascriptDocument24 pagesJavascriptMohamed MeskiPas encore d'évaluation
- Module Web Avance 1Document51 pagesModule Web Avance 1iaqowefsccydbebytvPas encore d'évaluation
- Javascript Tome Xxiii - Promises en JavaScriptDocument97 pagesJavascript Tome Xxiii - Promises en JavaScriptDoct Jean-Dadet DiasolukaPas encore d'évaluation
- Spring Pour Les NulsDocument16 pagesSpring Pour Les NulsPablo Sene100% (1)
- Chapitre06 - Seance02 - Associer Une Vue À Un Servlet BonDocument11 pagesChapitre06 - Seance02 - Associer Une Vue À Un Servlet BonBrayann DiePas encore d'évaluation
- Exo Web ServicesDocument21 pagesExo Web Servicesbenben08Pas encore d'évaluation
- TP5 J2eeDocument19 pagesTP5 J2eeYasmine BenomarPas encore d'évaluation
- Services Web Nextjs Tips v2Document5 pagesServices Web Nextjs Tips v2thibault.barral3347Pas encore d'évaluation
- React Cours Intensif 2020Document90 pagesReact Cours Intensif 2020Philippe ARRASPas encore d'évaluation
- Devstory Net 12129 Methodes Dans Le Cycle de Vie React Compo RemovedDocument16 pagesDevstory Net 12129 Methodes Dans Le Cycle de Vie React Compo RemovedNouha DaagiPas encore d'évaluation
- Esp AjaxDocument24 pagesEsp AjaxFabrice FotsoPas encore d'évaluation
- Javascript Partie1Document66 pagesJavascript Partie1saidi rouaPas encore d'évaluation
- Partie JEEDocument37 pagesPartie JEEits.youssef.jabriPas encore d'évaluation
- TP N°2 - Exemple Word Count Avec HadoopDocument12 pagesTP N°2 - Exemple Word Count Avec HadoopinesPas encore d'évaluation
- WWW - Cours Gratuit - Com Coursinformatique Id3269Document37 pagesWWW - Cours Gratuit - Com Coursinformatique Id3269Hela WederniPas encore d'évaluation
- Devstory Net 12125 React Props State RemovedDocument12 pagesDevstory Net 12125 React Props State RemovedNouha DaagiPas encore d'évaluation
- Reactjs Cours GPTDocument18 pagesReactjs Cours GPTChamson Alphonse VahanjakotoPas encore d'évaluation
- Cours AjaxDocument40 pagesCours Ajaxmoussaaliabdelkerim7Pas encore d'évaluation
- Reėsumeė JEEDocument7 pagesReėsumeė JEEzackkillz20Pas encore d'évaluation
- JavaEE EpDocument5 pagesJavaEE EpWilfreed Minfoundi ManguelePas encore d'évaluation
- Mapping Objet Relationnel Avec Hibernate Vers 4Document90 pagesMapping Objet Relationnel Avec Hibernate Vers 4nabilovic01Pas encore d'évaluation
- Pres - Java - ServletDocument30 pagesPres - Java - Servletabdelhafid ammariPas encore d'évaluation
- Correction Série1Document9 pagesCorrection Série1أمانيPas encore d'évaluation
- TP 1 ExtensifDocument16 pagesTP 1 ExtensifBENYAHIA NESRINEPas encore d'évaluation
- Les Servlets Pour EtudiantsDocument32 pagesLes Servlets Pour EtudiantsDwight AldridgePas encore d'évaluation
- Atelier 1 - Projet Spring BootDocument10 pagesAtelier 1 - Projet Spring BootJouhaina NasriPas encore d'évaluation
- Manipulation ServeurDocument7 pagesManipulation ServeurftftPas encore d'évaluation
- Chapitre 2Document14 pagesChapitre 2marie najPas encore d'évaluation
- TP 1Document12 pagesTP 1dhaouadi hazemPas encore d'évaluation
- 2016 Js React PDFDocument12 pages2016 Js React PDFHéla Ben KhalfallahPas encore d'évaluation
- Cours Spring MVCDocument82 pagesCours Spring MVCnabilovic01Pas encore d'évaluation
- Support Cours Jquery 16 12 21Document23 pagesSupport Cours Jquery 16 12 21borisdoua15Pas encore d'évaluation
- TP JMS NoteDocument20 pagesTP JMS NoteInèsPas encore d'évaluation
- Créer Une Application Bootstrap Avec Le MkframeworkDocument27 pagesCréer Une Application Bootstrap Avec Le MkframeworkMohamed OubenalPas encore d'évaluation
- WWW - Cours Gratuit - Com CoursAjax Id1918Document9 pagesWWW - Cours Gratuit - Com CoursAjax Id1918xavierPas encore d'évaluation
- cours JavaScriptDocument37 pagescours JavaScriptPro RayanPas encore d'évaluation
- Cours D Informatique Initiation Au Langage CDocument52 pagesCours D Informatique Initiation Au Langage CKenneth KodjoPas encore d'évaluation
- 267088J Manual PrimeTecB PrimeScanB FR HiResDocument4 pages267088J Manual PrimeTecB PrimeScanB FR HiResYacine Mesnata100% (1)
- Tableau Compétences Et Savoirs - CAP - MMVFDocument4 pagesTableau Compétences Et Savoirs - CAP - MMVFblancPas encore d'évaluation
- WordDocument21 pagesWordMAIZIA SARAHPas encore d'évaluation
- Les Sièges À Suspension Pour Chariots Élévateurs - Fiche PratiqueDocument4 pagesLes Sièges À Suspension Pour Chariots Élévateurs - Fiche PratiqueLamia ould amerPas encore d'évaluation
- Fiche de Poste GéomaticienDocument2 pagesFiche de Poste Géomaticienidris.cookPas encore d'évaluation
- Manuel D'utilisation: Betriebsanleitung Operating Instructions Manual de Servicio Istruzioni Per L'usoDocument36 pagesManuel D'utilisation: Betriebsanleitung Operating Instructions Manual de Servicio Istruzioni Per L'usoMohammed Yassine GarrebPas encore d'évaluation
- ManuelDocument149 pagesManuelKhaoula OuennichePas encore d'évaluation
- TP9 Protocoles-RoutageDocument5 pagesTP9 Protocoles-RoutageQueen LeiPas encore d'évaluation
- Exposé TQMDocument20 pagesExposé TQMJawad BhmPas encore d'évaluation
- Concepton Actice DirectoryDocument70 pagesConcepton Actice DirectorySidy CoulibalyPas encore d'évaluation
- Bimbtp01 155201764Document204 pagesBimbtp01 155201764H-ràf NabiilPas encore d'évaluation
- RLIDocument332 pagesRLIbetbet00Pas encore d'évaluation
- Propositon Commercial Laboratoire Al KhawarizmiDocument11 pagesPropositon Commercial Laboratoire Al KhawarizmihananenPas encore d'évaluation
- Architectures Des OrdinateursDocument74 pagesArchitectures Des OrdinateursmrzakPas encore d'évaluation
- Code Principale 1Document26 pagesCode Principale 1Kaoutar HOUZAIRANEPas encore d'évaluation
- Systèmes Temps Réel Et EmbarquésDocument28 pagesSystèmes Temps Réel Et Embarquésmoussaid.aPas encore d'évaluation
- Présentation Usinage 2022-CoursDocument67 pagesPrésentation Usinage 2022-Courssimo jinPas encore d'évaluation
- Catalogue Complet HFS SERV FR 2010Document64 pagesCatalogue Complet HFS SERV FR 2010ELODIAPas encore d'évaluation
- Présentation de Projet Industriel: Révision Du Système Qualité Du Centre Cegelec Infra Bassin de LoireDocument20 pagesPrésentation de Projet Industriel: Révision Du Système Qualité Du Centre Cegelec Infra Bassin de LoireAlex TchuentePas encore d'évaluation
- Stage 1Document9 pagesStage 1B R O U S QU ÉPas encore d'évaluation
- Flyer Tunnel Brazza WEBDocument3 pagesFlyer Tunnel Brazza WEBAliAnisPas encore d'évaluation
- Update ELSA 510 FRDocument17 pagesUpdate ELSA 510 FRgarga_cata1983Pas encore d'évaluation
- Sesión 14Document5 pagesSesión 14Dante Draco VirgilioPas encore d'évaluation
- CV Arij Haidri 2Document2 pagesCV Arij Haidri 2arij haidriPas encore d'évaluation
- Automatisme Avec Siemens API (PDFDrive)Document89 pagesAutomatisme Avec Siemens API (PDFDrive)Emmanuel SotongbePas encore d'évaluation
- 02 TD Automatisation DEBOURRAGEDocument2 pages02 TD Automatisation DEBOURRAGEKarishma NelaupePas encore d'évaluation