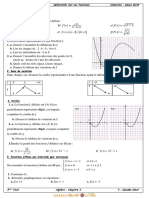
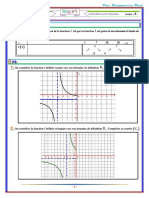
Vous aimerez peut-être aussi
- Programme Terminales - A (Ok)Document38 pagesProgramme Terminales - A (Ok)BAMALJoseph FirminPas encore d'évaluation
- Exercices Corrigés Recherche OpérationnelleDocument17 pagesExercices Corrigés Recherche OpérationnelleAbdelouadoud Samery0% (1)
- Technicien Commercial D3TQ (2002 3100)Document120 pagesTechnicien Commercial D3TQ (2002 3100)api-3732641Pas encore d'évaluation
- Sujet Zero Ou Sujet 0 en Spe Maths Specialite Mathematiques Bac 2021Document9 pagesSujet Zero Ou Sujet 0 en Spe Maths Specialite Mathematiques Bac 2021BELLE GABRIELPas encore d'évaluation
- TPOMI3A22Document18 pagesTPOMI3A22Arthur DubijeonPas encore d'évaluation
- Exercices Corrigés Recherche OpérationnelleDocument21 pagesExercices Corrigés Recherche OpérationnelleAnouar Bh100% (1)
- Cours ApprentissageDocument49 pagesCours ApprentissageRoufida SAADALLAHPas encore d'évaluation
- EfficientNet B3Document4 pagesEfficientNet B3Yasmina RadouaniPas encore d'évaluation
- Integration CoursDocument13 pagesIntegration CoursakramamairaPas encore d'évaluation
- Fctusuelle 1Document8 pagesFctusuelle 1TARIQ BARKIPas encore d'évaluation
- INSA Toulouse 1A Maths IntegrationDocument51 pagesINSA Toulouse 1A Maths Integrationpurplera1n100% (1)
- Chapitre6 04Document12 pagesChapitre6 04Kacou FatimPas encore d'évaluation
- .Cours Intégration Num ResmaDocument16 pages.Cours Intégration Num ResmaOmar MenichiPas encore d'évaluation
- Fiche TD Analyse 2017Document4 pagesFiche TD Analyse 2017Kacou FatimPas encore d'évaluation
- Fonct 2Document8 pagesFonct 2Ousmane TRAORE100% (1)
- Elnum TD2Document3 pagesElnum TD2aniriPas encore d'évaluation
- Chap - Programmation LinéaireDocument8 pagesChap - Programmation Linéairetest maestroPas encore d'évaluation
- 09.calcul IntegralDocument11 pages09.calcul Integralyassirmohamed306Pas encore d'évaluation
- TP AutomatiqueDocument63 pagesTP AutomatiqueNabil BounouPas encore d'évaluation
- 09.calcul IntegralDocument11 pages09.calcul IntegralIsmail ait talebPas encore d'évaluation
- Presentation TP1Document21 pagesPresentation TP1Emmanuel PuatiPas encore d'évaluation
- IntegrationDocument22 pagesIntegrationHicham WadiPas encore d'évaluation
- Chapitre II: La Récursivité: ObjectifsDocument13 pagesChapitre II: La Récursivité: ObjectifsEttaoufik AbdelazizPas encore d'évaluation
- Série D'exercices - Math Generalites Sur Les Fonctions - 3ème Technique (2012-2013) MR Guedda OmarDocument3 pagesSérie D'exercices - Math Generalites Sur Les Fonctions - 3ème Technique (2012-2013) MR Guedda OmarnassimossPas encore d'évaluation
- ch4 BDDocument15 pagesch4 BDSa MuelPas encore d'évaluation
- CH01 Int GalDocument27 pagesCH01 Int GalPatrick NgakouPas encore d'évaluation
- Chapitre II OptimisationDocument4 pagesChapitre II Optimisationbabasidi AbderazakPas encore d'évaluation
- TP 1Document3 pagesTP 1yves1ndriPas encore d'évaluation
- Bac Math 2010Document2 pagesBac Math 2010Adama MaigaPas encore d'évaluation
- Analyse Juin 21 SolutionsDocument10 pagesAnalyse Juin 21 Solutionsh8gsmgkn9bPas encore d'évaluation
- Teba 2010Document2 pagesTeba 2010Koro Alpha DialloPas encore d'évaluation
- AlgoavanceeDocument50 pagesAlgoavanceeRaou NekPas encore d'évaluation
- TP 1 A RendreDocument6 pagesTP 1 A RendreDia Mouhamadou NabyPas encore d'évaluation
- Série4 - RécursivitéDocument1 pageSérie4 - RécursivitéissabaloutaPas encore d'évaluation
- Chap 4 PL CompletDocument26 pagesChap 4 PL CompletLamziouaq ZakariaPas encore d'évaluation
- TP de Traitement D'images Séance 2: Conversion D'espace Couleur/manipulations D'histogramme/ Filtrage Des ImagesDocument5 pagesTP de Traitement D'images Séance 2: Conversion D'espace Couleur/manipulations D'histogramme/ Filtrage Des ImagesOThmane CheyadmiPas encore d'évaluation
- Chapitre 4Document32 pagesChapitre 4ayissi jeanPas encore d'évaluation
- Analyse Chp2Document17 pagesAnalyse Chp2Di-Enilson ÉtiennePas encore d'évaluation
- Presentation ERA Matlab SimulinkDocument82 pagesPresentation ERA Matlab SimulinkАднан Бен АзузPas encore d'évaluation
- PB - Programmation Modulaire Avec PythonDocument21 pagesPB - Programmation Modulaire Avec PythonNourchene BensmayaPas encore d'évaluation
- M Co Int JMFDocument20 pagesM Co Int JMFvalderamadurkheimPas encore d'évaluation
- Avant ProposDocument194 pagesAvant ProposFlora AkePas encore d'évaluation
- Chapitre 5 Généralités Sur Les Fonctions: SommaireDocument12 pagesChapitre 5 Généralités Sur Les Fonctions: SommaireJohan FaberPas encore d'évaluation
- Chapitre 3 Fonctions Et ModulesDocument20 pagesChapitre 3 Fonctions Et ModulesHamoud MedPas encore d'évaluation
- INITIATION Au Logiciel MATLABDocument6 pagesINITIATION Au Logiciel MATLABabdelhadi ennajihPas encore d'évaluation
- Serie N1 Etude Des Fonctions BAC WWW - EtudeDocument3 pagesSerie N1 Etude Des Fonctions BAC WWW - EtudeSachi BuridanaPas encore d'évaluation
- Generalites Sur Les Fonctions Exercices Non Corriges 1 3Document8 pagesGeneralites Sur Les Fonctions Exercices Non Corriges 1 3Mounir BarakaPas encore d'évaluation
- Travaux Pratiques Sur La Partie Algorithme GenetiqueDocument5 pagesTravaux Pratiques Sur La Partie Algorithme GenetiqueCEM Yelle N centrePas encore d'évaluation
- TP1 PythonDocument3 pagesTP1 PythonFranck Jordan NOZAKAP FOSSIPas encore d'évaluation
- Devoir de Synthèse N°1 2002 2003Document1 pageDevoir de Synthèse N°1 2002 2003Aziz ShiliPas encore d'évaluation
- ch4 BDDocument15 pagesch4 BDKhadidiatou SARRPas encore d'évaluation
- Les Fonctions Linéaires Et Affines: Cours de Maths en 3Document3 pagesLes Fonctions Linéaires Et Affines: Cours de Maths en 3PhilippePas encore d'évaluation
- Cours MécaniqueDocument11 pagesCours Mécaniquewass princePas encore d'évaluation
- Tp4matlab1 141224114014 Conversion Gate02 PDFDocument4 pagesTp4matlab1 141224114014 Conversion Gate02 PDFABDELHAKIMPas encore d'évaluation
- SI ExosDocument5 pagesSI ExosCyrille LamasséPas encore d'évaluation
- Débruitage Multifractal Par Évolution Interactive: RésuméDocument4 pagesDébruitage Multifractal Par Évolution Interactive: RésuméAbdelkader RabahPas encore d'évaluation
- Fon 1Document2 pagesFon 1فضاء منبر المعرفةPas encore d'évaluation
- TP1 OanDocument20 pagesTP1 Oanhupselle bitassiPas encore d'évaluation
- 04 Chap 4 Exos 1Document3 pages04 Chap 4 Exos 1KAIS TABOUBIPas encore d'évaluation
- Résumé Practica 3 2Document6 pagesRésumé Practica 3 2alexandre.gentil49Pas encore d'évaluation
- Modélisation et rendu basés sur l'image: Explorer le réalisme visuel : techniques de vision par ordinateurD'EverandModélisation et rendu basés sur l'image: Explorer le réalisme visuel : techniques de vision par ordinateurPas encore d'évaluation
- Excel TCDDocument7 pagesExcel TCDméthode RMarcPas encore d'évaluation
- Loan Risk Prediction - Part 1Document31 pagesLoan Risk Prediction - Part 1méthode RMarcPas encore d'évaluation
- Appli Android Pour Enquête de TerrainDocument39 pagesAppli Android Pour Enquête de Terrainméthode RMarcPas encore d'évaluation
- Fonction DataTableProxy RDocument3 pagesFonction DataTableProxy Rméthode RMarcPas encore d'évaluation
- Séries Temporelles - Kouadio Charles EmmanuelDocument19 pagesSéries Temporelles - Kouadio Charles Emmanuelméthode RMarcPas encore d'évaluation
- Series TemporellesDocument19 pagesSeries Temporellesméthode RMarcPas encore d'évaluation
- AndroidDocument11 pagesAndroidméthode RMarcPas encore d'évaluation
- Machine Learning H2oDocument99 pagesMachine Learning H2ométhode RMarcPas encore d'évaluation
- Astuce Excel !Document22 pagesAstuce Excel !méthode RMarcPas encore d'évaluation
- Tuto Data BaseDocument9 pagesTuto Data Baseméthode RMarcPas encore d'évaluation
- STT 4230Document47 pagesSTT 4230méthode RMarcPas encore d'évaluation
- YAMLDocument17 pagesYAMLméthode RMarcPas encore d'évaluation
- STT 4230Document18 pagesSTT 4230méthode RMarcPas encore d'évaluation
- Une Introduction À H2O Avec R - R-BlogueursDocument9 pagesUne Introduction À H2O Avec R - R-Blogueursméthode RMarcPas encore d'évaluation
- Déployer Une Application Shiny Sur AWS - Charles BordetDocument34 pagesDéployer Une Application Shiny Sur AWS - Charles Bordetméthode RMarcPas encore d'évaluation
- Qu'est-Ce Que YAML ?Document10 pagesQu'est-Ce Que YAML ?méthode RMarcPas encore d'évaluation
- YamlDocument12 pagesYamlméthode RMarcPas encore d'évaluation
- TP3 PDFDocument4 pagesTP3 PDFZeineb HoumanPas encore d'évaluation
- Serie - N - 2Document2 pagesSerie - N - 2jobPas encore d'évaluation
- Apple MacBook Pro 13.3'' Touch Bar 512 Go SSD 16 Go RAM Intel Core I7 Quadricœur À 2,7 GHZ Gris Sidéral Sur-Mesure - MacBook - ADocument1 pageApple MacBook Pro 13.3'' Touch Bar 512 Go SSD 16 Go RAM Intel Core I7 Quadricœur À 2,7 GHZ Gris Sidéral Sur-Mesure - MacBook - AAdonPas encore d'évaluation
- ADD - Chap IV ClusteringDocument18 pagesADD - Chap IV ClusteringNihal DakkounePas encore d'évaluation
- Linux 8 Ème ÉditionDocument191 pagesLinux 8 Ème ÉditionMouez ChebbiPas encore d'évaluation
- Chapitre-3 Partie 1Document27 pagesChapitre-3 Partie 1brezzy mira100% (3)
- Guide Des Solutions de Stockage PDFDocument16 pagesGuide Des Solutions de Stockage PDFJaouad M'hamdiPas encore d'évaluation
- Electronique HF PDFDocument45 pagesElectronique HF PDFVladimir Mar Roüchköff DioufPas encore d'évaluation
- Manuel A2 M78Document28 pagesManuel A2 M78derbalijalelPas encore d'évaluation
- Cours 01 AutomatismeDocument20 pagesCours 01 AutomatismenadirPas encore d'évaluation
- Chapter 1Document6 pagesChapter 1Aissam ChebbahPas encore d'évaluation
- D4B803E9CC9-Generic Scan ToolDocument537 pagesD4B803E9CC9-Generic Scan ToolGeorge PonparauPas encore d'évaluation
- Chapitre 3 - Evaluation - SDFDocument48 pagesChapitre 3 - Evaluation - SDFMohaman Gonza100% (1)
- Chapitre 03Document7 pagesChapitre 03houda bensalahPas encore d'évaluation
- UE-R&S EssentialsDocument5 pagesUE-R&S EssentialsPFEPas encore d'évaluation
- IC1 Poly 2007Document204 pagesIC1 Poly 2007AIIPas encore d'évaluation
- Cours INF102Document68 pagesCours INF102DegbeviPas encore d'évaluation
- DjelloutMessaoud DjaroumBrahimDocument57 pagesDjelloutMessaoud DjaroumBrahimGaël King'sPas encore d'évaluation
- TP 1 - Switch Cisco (Tuto)Document7 pagesTP 1 - Switch Cisco (Tuto)julesPas encore d'évaluation
- Autotest - PMBoK & OPM3Document3 pagesAutotest - PMBoK & OPM3Carlos Humberto Munar MonsalvePas encore d'évaluation
- Ordo ChapI - IntroDocument59 pagesOrdo ChapI - Introsaif boukraia2Pas encore d'évaluation
- React Native, Applications Mobiles Natives Pour iOS Et AndroidDocument2 pagesReact Native, Applications Mobiles Natives Pour iOS Et AndroidSimon MuemboPas encore d'évaluation
- Torrent FR-ENDocument2 pagesTorrent FR-ENapi-12310603Pas encore d'évaluation
- These Mounir PDFDocument234 pagesThese Mounir PDFHanane Rimi100% (1)
- Serie 1 - Les Bases de LalgorithmiqueDocument2 pagesSerie 1 - Les Bases de LalgorithmiqueTarek BlfPas encore d'évaluation
- Comprendre Les Tensions TconDocument4 pagesComprendre Les Tensions TconJdidi Adel100% (1)
- Aide CANECO MulhouseDocument15 pagesAide CANECO MulhousemoezborchaniPas encore d'évaluation
- Examen 4Document6 pagesExamen 4Mouhcine RomaniPas encore d'évaluation