Vous aimerez peut-être aussi
- UPL1718565880135151131 Cours1 College2019Document28 pagesUPL1718565880135151131 Cours1 College2019Soulayma GazzehPas encore d'évaluation
- Jata WaliDocument1 pageJata WaliTeam Architects JaipurPas encore d'évaluation
- DEVOIRE 01-ConvertiDocument4 pagesDEVOIRE 01-ConvertiIlu SionPas encore d'évaluation
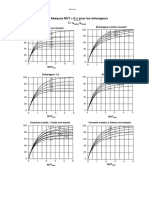
- Abaques NUT F (H) Pour Les ÉchangeursDocument1 pageAbaques NUT F (H) Pour Les ÉchangeursaberranePas encore d'évaluation
- Note de Calcul EU-EV-EP V3Document6 pagesNote de Calcul EU-EV-EP V3abdessamad CHADDOUPas encore d'évaluation
- Serie Des Exercices Point de CommandeDocument3 pagesSerie Des Exercices Point de Commandehassan etberPas encore d'évaluation
- CORDocument1 pageCORRafael LeongPas encore d'évaluation
- PhotopileDocument3 pagesPhotopileSlah HamdyPas encore d'évaluation
- Abaques NUT F (E)Document1 pageAbaques NUT F (E)aberranePas encore d'évaluation
- Ejercicio2Document1 pageEjercicio2henry patricioPas encore d'évaluation
- compt rendu TP PVDocument33 pagescompt rendu TP PVChady LahbibPas encore d'évaluation
- Ulangan Harian Tema 5 Kelas 4 SDN 1 BomertoDocument4 pagesUlangan Harian Tema 5 Kelas 4 SDN 1 BomertoHafidAL-beckhamCahzobopanserSaklawasePas encore d'évaluation
- Mo Hinh 5 TBA 1 Pha Tren 01 Cot Ly TamDocument12 pagesMo Hinh 5 TBA 1 Pha Tren 01 Cot Ly TamnguyenvantrucPas encore d'évaluation
- Plan de Cotation EtageDocument1 pagePlan de Cotation EtageKONAN KOFFI DESIREPas encore d'évaluation
- Doc1 LucasDocument3 pagesDoc1 LucasLucas KonanPas encore d'évaluation
- PuntosDocument25 pagesPuntosJose RafaelPas encore d'évaluation
- Petit NoelDocument2 pagesPetit NoelSophieGrallPas encore d'évaluation
- PETADocument1 pagePETAAhmad AbdullahPas encore d'évaluation
- COV Et Coefficient de CorrelationDocument8 pagesCOV Et Coefficient de CorrelationMatin CalmePas encore d'évaluation
- Ulangan Harian Tema 4 Kelas 4 SDN 1 BomertoDocument4 pagesUlangan Harian Tema 4 Kelas 4 SDN 1 BomertoHafidAL-beckhamCahzobopanserSaklawasePas encore d'évaluation
- Oxe175 FR 2023Document2 pagesOxe175 FR 2023Bibene MakitaPas encore d'évaluation
- Axe CMGDocument1 pageAxe CMGLara BousselmiPas encore d'évaluation
- Corrigé TD 2 PST USTO 2020-21Document4 pagesCorrigé TD 2 PST USTO 2020-21mayar mimiPas encore d'évaluation
- Suivi de Tresorerie Entres Et SortiesDocument6 pagesSuivi de Tresorerie Entres Et SortiespromepromessePas encore d'évaluation
- Methode Simplexe.Document3 pagesMethode Simplexe.lm10 MedPas encore d'évaluation
- Orange Money - DistributeurDocument1 pageOrange Money - DistributeurRaoul YodoPas encore d'évaluation
- Каталог TCK фирмы EastelDocument3 pagesКаталог TCK фирмы EastelAndrii ZubrytskyiPas encore d'évaluation
- 03-1 - TD Fiabilité - Etude Empyrique Des DéfaillancesDocument11 pages03-1 - TD Fiabilité - Etude Empyrique Des DéfaillancesAhmed MohamedPas encore d'évaluation
- Ars 15Document1 pageArs 15tomPas encore d'évaluation
- 16-Support de ColonneDocument1 page16-Support de ColonneHaythem JameiPas encore d'évaluation
- Eurusd MaxDocument1 pageEurusd Maxbeetge94Pas encore d'évaluation
- MolesDocument19 pagesMolesJhonattan NiñoPas encore d'évaluation
- PluviométrieDocument1 pagePluviométrieNicolas MaminiainaPas encore d'évaluation
- Ejercicio 6.23Document8 pagesEjercicio 6.23Emiliano Francisco TroncosoPas encore d'évaluation
- SFC36204 TD 5e71eaed6d558Document5 pagesSFC36204 TD 5e71eaed6d558aaddouzPas encore d'évaluation
- Dm-Mica Malp Ishani PanchalDocument9 pagesDm-Mica Malp Ishani PanchalScribdTranslationsPas encore d'évaluation
- Eviews1 Ulpgl CorrigeDocument11 pagesEviews1 Ulpgl Corrigenono hodariPas encore d'évaluation
- ETATS JOURNALIER290723Document2 pagesETATS JOURNALIER290723fotso kamgaPas encore d'évaluation
- GRDocument1 pageGRsofianePas encore d'évaluation
- Dimensionnement Instalation PneumatiqueDocument2 pagesDimensionnement Instalation PneumatiqueAhmed LabidiPas encore d'évaluation
- Teoria Del Consumidor PDFDocument2 pagesTeoria Del Consumidor PDFANDRESPas encore d'évaluation
- CHAP1SER2Document2 pagesCHAP1SER2Eduardo EspinoPas encore d'évaluation
- Analyse Granulométrique Des GranulatsDocument3 pagesAnalyse Granulométrique Des GranulatsbensatorPas encore d'évaluation
- Le Prix Psychologique Ou Prix DDocument2 pagesLe Prix Psychologique Ou Prix DSALMA LAMGHAIRBATPas encore d'évaluation
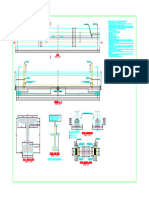
- Plan de Ferraillage Type Longrine 25x50Document1 pagePlan de Ferraillage Type Longrine 25x50FrancklinMeunierM'ondoPas encore d'évaluation
- 5H PDFDocument1 page5H PDFPaul Cedric FokoPas encore d'évaluation
- Plan de Ferraillage Type Longrine 25X50Document1 pagePlan de Ferraillage Type Longrine 25X50FrancklinMeunierM'ondoPas encore d'évaluation
- Hotel Los InkasDocument4 pagesHotel Los InkasEVER RUIZ RUBIOPas encore d'évaluation
- Zarovicka Malicka - KopieDocument3 pagesZarovicka Malicka - KopiemacintoslolPas encore d'évaluation
- Audio Tonale Modele BisDocument5 pagesAudio Tonale Modele BisndongopilorPas encore d'évaluation
- 2 - Dimensionnement ChéneauDocument8 pages2 - Dimensionnement Chéneauayoub elhallani100% (3)
- Proj MedROE V UHFDocument6 pagesProj MedROE V UHFElmo Dutra FilhoPas encore d'évaluation
- Girder 1Document1 pageGirder 1alpegambarliPas encore d'évaluation
- STG DDV Testing Report 2022 DualDocument17 pagesSTG DDV Testing Report 2022 DualONMPlanning EngineerPT. GPOSKPSitePas encore d'évaluation
- Challenge Chauffeur Grille de Points New - 2020Document2 pagesChallenge Chauffeur Grille de Points New - 2020Nkodia Prince maviePas encore d'évaluation
- Corrige Geipi QCM 2006Document7 pagesCorrige Geipi QCM 2006la physique selon le programme FrançaisPas encore d'évaluation
- Dimensões EstufaDocument1 pageDimensões EstufaAlailson FeitosaPas encore d'évaluation
- Lab Vial TamicesDocument6 pagesLab Vial Tamicesespe.olivaresbPas encore d'évaluation
- TD Corr 1 - 4.4Document19 pagesTD Corr 1 - 4.4Trésor DINPas encore d'évaluation
- TD Modélisation Statistique Des Valeurs Extrêmes: Exercice 1Document3 pagesTD Modélisation Statistique Des Valeurs Extrêmes: Exercice 1Trésor DINPas encore d'évaluation
- Caractérisation Des Distributions À Queue Lourde Pour L'Analyse Des CruesDocument82 pagesCaractérisation Des Distributions À Queue Lourde Pour L'Analyse Des CruesTrésor DINPas encore d'évaluation
- Cours ExtremesDocument40 pagesCours ExtremesTrésor DINPas encore d'évaluation
- TD Statistique Chap 8Document4 pagesTD Statistique Chap 8MEHDIPas encore d'évaluation
- StatistiqueDocument24 pagesStatistiqueLylawPas encore d'évaluation
- Fascicule Exercices GesEnt 22-23Document79 pagesFascicule Exercices GesEnt 22-23Lieve EmielPas encore d'évaluation
- Examen Final INF BIOS 2022Document2 pagesExamen Final INF BIOS 2022Ghizu ChPas encore d'évaluation
- EJAYDocument24 pagesEJAYromuald calpasPas encore d'évaluation
- Slide SondageDocument16 pagesSlide SondageSpouche PackPas encore d'évaluation
- AFC CoursDocument6 pagesAFC CoursPptdPas encore d'évaluation
- Statistique TMSéries 6 Et 7Document4 pagesStatistique TMSéries 6 Et 7Bacha Amal100% (1)
- Chapter 1 Part 1Document10 pagesChapter 1 Part 1SOUFIANE BEN YAALAPas encore d'évaluation
- Chapitre 2 Les Analyses Univariées Et Bivariées 2LNSGDocument21 pagesChapitre 2 Les Analyses Univariées Et Bivariées 2LNSGSouad Bouabana100% (1)
- Statistique SDocument3 pagesStatistique SLine Hustling Dollar100% (3)
- Td1: Exercices de Statistiques Descriptives: DD DD D D Nna DDDocument4 pagesTd1: Exercices de Statistiques Descriptives: DD DD D D Nna DDMalincov MandatPas encore d'évaluation
- RÉSUMÉ DE COURS STAT ST 2ème Année PDFDocument5 pagesRÉSUMÉ DE COURS STAT ST 2ème Année PDFMiloud Timmaoui UniqePas encore d'évaluation
- StatistDocument4 pagesStatistsamiraPas encore d'évaluation
- Stat Correction Serie 3Document17 pagesStat Correction Serie 3Clay Iip100% (1)
- Cours Statistique MR - El Haddaoui 21-22Document33 pagesCours Statistique MR - El Haddaoui 21-22abraham LincolnPas encore d'évaluation
- Statistique DescriptiveDocument19 pagesStatistique Descriptivemed elhaddadPas encore d'évaluation
- Corrigé TD 2Document20 pagesCorrigé TD 2Mohamed BoujnahPas encore d'évaluation
- TP4 StatistiqueDocument4 pagesTP4 Statistiqueimane anejjarPas encore d'évaluation
- Stat 2e An ReserveDocument48 pagesStat 2e An ReserveYaye Ndew ThiaoPas encore d'évaluation
- TP6 - VariogrammeVarianceBlocDocument9 pagesTP6 - VariogrammeVarianceBlocarachidPas encore d'évaluation
- TD 2.2 Eléments de CorrectionDocument5 pagesTD 2.2 Eléments de CorrectionAMINE HABBOUCHPas encore d'évaluation
- La CovarianceDocument6 pagesLa CovarianceCarmen DelrPas encore d'évaluation
- A02-Analyses Statistiques de Base 181001Document50 pagesA02-Analyses Statistiques de Base 181001Fernando Jorge BadePas encore d'évaluation
- Econometrie PanelsDocument67 pagesEconometrie PanelsMØha MédPas encore d'évaluation
- Exercices StatistiqueDocument4 pagesExercices StatistiqueabdelwahabPas encore d'évaluation
- Leçon 7 - Théorie Financiere - Titres Et PortefeuillesDocument9 pagesLeçon 7 - Théorie Financiere - Titres Et PortefeuilleshatemPas encore d'évaluation
- Chapitre 1Document102 pagesChapitre 1Ayyoub MerouanePas encore d'évaluation
- TP 6 Mag CorrectionDocument16 pagesTP 6 Mag CorrectionYacine MoussaouiPas encore d'évaluation
- Presentation1 - PROBA-STAT-GEGM 2022-2023Document80 pagesPresentation1 - PROBA-STAT-GEGM 2022-2023ليس مهم الاسمPas encore d'évaluation
- Les LES TRUCS MATHEMATIQUES AU PRIMAIRE: et si on leur donnait du sens!D'EverandLes LES TRUCS MATHEMATIQUES AU PRIMAIRE: et si on leur donnait du sens!Évaluation : 2 sur 5 étoiles2/5 (1)
- Petit guide d'aromatherapie: ou de l'usage des huiles essentielles et de la phytothérapieD'EverandPetit guide d'aromatherapie: ou de l'usage des huiles essentielles et de la phytothérapiePas encore d'évaluation
- Epistémologie de la gravité expérimentale: Rationalité scientifiqueD'EverandEpistémologie de la gravité expérimentale: Rationalité scientifiquePas encore d'évaluation
- Les Êtres Vivants Dépendent De La Mécanique QuantiqueD'EverandLes Êtres Vivants Dépendent De La Mécanique QuantiquePas encore d'évaluation
- Enjeux contemporains de l'éducation scientifique et technologiqueD'EverandEnjeux contemporains de l'éducation scientifique et technologiqueAbdelkrim HasniPas encore d'évaluation
- Les 10 Secrets pour une Vie Plus Heureuse avec la Maladie de ParkinsonD'EverandLes 10 Secrets pour une Vie Plus Heureuse avec la Maladie de ParkinsonPas encore d'évaluation
- Je me prépare aux examens du ministère en mathématiques: Es-tu prêt à passer le test ?D'EverandJe me prépare aux examens du ministère en mathématiques: Es-tu prêt à passer le test ?Évaluation : 4 sur 5 étoiles4/5 (1)
- Le médecin quantique: Un docteur en physique quantique explique l’efficacité thérapeutique de la médecine intégraleD'EverandLe médecin quantique: Un docteur en physique quantique explique l’efficacité thérapeutique de la médecine intégralePas encore d'évaluation
- La LA RECHERCHE EN DIDACTIQUE DES MATHEMATIQUES ET LES ELEVES EN DIFFICULTE: Quels enjeux et quelles perspectives?D'EverandLa LA RECHERCHE EN DIDACTIQUE DES MATHEMATIQUES ET LES ELEVES EN DIFFICULTE: Quels enjeux et quelles perspectives?Pas encore d'évaluation
- Pour une intervention précoce: Dépister, repérer, identifier les difficultés et les troubles d'apprentissage - guideD'EverandPour une intervention précoce: Dépister, repérer, identifier les difficultés et les troubles d'apprentissage - guidePas encore d'évaluation
- La particule de temps: Une approche quantique du tempsD'EverandLa particule de temps: Une approche quantique du tempsPas encore d'évaluation
- Représenter pour mieux raisonner - Résolution de problèmes écrits de multiplication et de divisionD'EverandReprésenter pour mieux raisonner - Résolution de problèmes écrits de multiplication et de divisionPas encore d'évaluation
- Mathématiques ludiques pour les enfants de 4 à 8 ansD'EverandMathématiques ludiques pour les enfants de 4 à 8 ansPas encore d'évaluation
- Se SE PREPARER A ENSEIGNER LES MATHEMATIQUES AU PRIMAIRED'EverandSe SE PREPARER A ENSEIGNER LES MATHEMATIQUES AU PRIMAIREPas encore d'évaluation
- Représenter pour mieux raisonner: Résolution de problèmes écrits d'addition et de soustractionD'EverandReprésenter pour mieux raisonner: Résolution de problèmes écrits d'addition et de soustractionPas encore d'évaluation
- Les premiers apprentissages scolaires à la loupe: Des liens entre énumération, oralité et littératieD'EverandLes premiers apprentissages scolaires à la loupe: Des liens entre énumération, oralité et littératiePas encore d'évaluation
- Quand 7 x 6 = 37: Partir des connaissances des élèves pour enseigner les mathématiquesD'EverandQuand 7 x 6 = 37: Partir des connaissances des élèves pour enseigner les mathématiquesPas encore d'évaluation
- Évaluations nationales des acquis scolaires, Volume 4: Analyser les données issues d'une évaluation nationale des acquis scolairesD'EverandÉvaluations nationales des acquis scolaires, Volume 4: Analyser les données issues d'une évaluation nationale des acquis scolairesPas encore d'évaluation