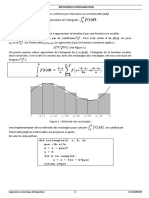
Vous aimerez peut-être aussi
- AnumII Ch3 2 SysLin PartieII ComplementsDocument11 pagesAnumII Ch3 2 SysLin PartieII ComplementsDragster TchatchouPas encore d'évaluation
- TP ScilabDocument14 pagesTP ScilabLatasha MillerPas encore d'évaluation
- Enonces tp9Document4 pagesEnonces tp9Aaissa AaissPas encore d'évaluation
- Matlab TPDocument7 pagesMatlab TPben boubaker100% (1)
- Controle 2 Epreuve Du Module Analyse Numerique Et Analyse de Donnees S1 XDocument2 pagesControle 2 Epreuve Du Module Analyse Numerique Et Analyse de Donnees S1 Xchiim 197Pas encore d'évaluation
- (TD1) ÉlectrostatiqueDocument2 pages(TD1) ÉlectrostatiquemohamedlagdafmlPas encore d'évaluation
- TP 3025Document11 pagesTP 3025ALFRED FOKOUNG DOUOPas encore d'évaluation
- TP1 Analyse NumeriqueDocument4 pagesTP1 Analyse NumeriqueYoussef_Consty_4665Pas encore d'évaluation
- TD NumDocument14 pagesTD NumSFatima-EzzahraPas encore d'évaluation
- Matlab2009 Exam2correcDocument6 pagesMatlab2009 Exam2correcAbdel DaaPas encore d'évaluation
- Fiche 8Document16 pagesFiche 8Fatma BelabedPas encore d'évaluation
- Tp1 Opt BoulmezaDocument4 pagesTp1 Opt BoulmezaRodrigue patrice Njounhassi koagnePas encore d'évaluation
- TP Informatique (Matlab)Document6 pagesTP Informatique (Matlab)Soufiane Frahtia30Pas encore d'évaluation
- TP Informatique (Matlab)Document6 pagesTP Informatique (Matlab)Soufiane Frahtia30Pas encore d'évaluation
- Une Carte Du Feu: Appe OndeDocument3 pagesUne Carte Du Feu: Appe Ondereal.mmlPas encore d'évaluation
- Methode Gauss Jordan PDFDocument2 pagesMethode Gauss Jordan PDFSadim JaponyPas encore d'évaluation
- TP5 - Les Matrices Dans Scilab: 1 Créer Et Modier Une MatriceDocument2 pagesTP5 - Les Matrices Dans Scilab: 1 Créer Et Modier Une MatriceHicham AtatriPas encore d'évaluation
- Exercices AAV v2Document8 pagesExercices AAV v2Yassinox kamal50% (2)
- Suj Corrig EF Calcul FormelDocument3 pagesSuj Corrig EF Calcul FormelsousouPas encore d'évaluation
- Feuille 2Document2 pagesFeuille 2Kélibiano FirasPas encore d'évaluation
- TP0 Initiation À MATLABDocument21 pagesTP0 Initiation À MATLABMokhles ElouaerPas encore d'évaluation
- TP1 CorrigeDocument12 pagesTP1 Corrigeguizeni ahmedPas encore d'évaluation
- Initiation MatlabDocument4 pagesInitiation MatlabFadila FEPas encore d'évaluation
- Calcul Scientifique TP1 Résolution de SEL CorrigéDocument13 pagesCalcul Scientifique TP1 Résolution de SEL CorrigéWassim BecheikhPas encore d'évaluation
- Transformation HELMERT + BAssin VersantDocument5 pagesTransformation HELMERT + BAssin VersantSab RinaPas encore d'évaluation
- TP Tds TicqDocument52 pagesTP Tds TicqHajar AdnanPas encore d'évaluation
- TP MatlabDocument18 pagesTP MatlabLakhdari BoutheinaPas encore d'évaluation
- TP MATLAB MATH 2LMD MathQuelquesSolutionsDocument9 pagesTP MATLAB MATH 2LMD MathQuelquesSolutionsAmal HentatiPas encore d'évaluation
- IntegrationsDocument3 pagesIntegrationsBoutaina BerradiPas encore d'évaluation
- Projet de PythonDocument14 pagesProjet de Pythonridwane biyaoPas encore d'évaluation
- TD Séries FourierDocument3 pagesTD Séries FourierMohamed OuaggaPas encore d'évaluation
- 2variables, Vecteurs Et MatricesDocument12 pages2variables, Vecteurs Et Matricesrdngillia1Pas encore d'évaluation
- TD TP 4Document4 pagesTD TP 4Jessica Gourdon100% (1)
- Initiation MatlabDocument17 pagesInitiation MatlabSabri AbidiPas encore d'évaluation
- Notes de Cours Fonctions RéellesDocument44 pagesNotes de Cours Fonctions Réellesyoimiya pewpewPas encore d'évaluation
- Chap7 Methode Des RotationsDocument26 pagesChap7 Methode Des RotationsMamadou BambaPas encore d'évaluation
- TP - Initiation MapleDocument7 pagesTP - Initiation Maplesakhir sarrPas encore d'évaluation
- TPautomatique TIMQ2018Document16 pagesTPautomatique TIMQ2018fatima azalmadPas encore d'évaluation
- Tpe D'outils de SimulationDocument22 pagesTpe D'outils de Simulationdjamo2 bienvenuPas encore d'évaluation
- Tutoriel MatlabDocument4 pagesTutoriel Matlabllfreaky0% (1)
- Matlab Cour Du ProfDocument42 pagesMatlab Cour Du ProfAbderrahmen HassounaPas encore d'évaluation
- Corrigé calculINtegral-1Document7 pagesCorrigé calculINtegral-1Amine KliPas encore d'évaluation
- Débuter en AlgorithmiqueDocument7 pagesDébuter en Algorithmiquelolodu61Pas encore d'évaluation
- Exercices Révisions-ConvertiDocument11 pagesExercices Révisions-ConvertiCiobanu Marius FlorinPas encore d'évaluation
- Compte Rendu TP 1.seifDocument8 pagesCompte Rendu TP 1.seifSeif GuetitiPas encore d'évaluation
- IterativeDocument3 pagesIterativeFayçal BelkessamPas encore d'évaluation
- Cours D'analyse Numérique Bac 2 Réseaux Et TélécomsDocument56 pagesCours D'analyse Numérique Bac 2 Réseaux Et TélécomsLukis Diallo100% (1)
- Chapitre2 Méthode de GAUSSDocument7 pagesChapitre2 Méthode de GAUSSمنير راميPas encore d'évaluation
- Résolution AX BDocument3 pagesRésolution AX BKhadija MachkourPas encore d'évaluation
- Maths 1ere D, Seq 4 2023-2024Document2 pagesMaths 1ere D, Seq 4 2023-2024valeryemougnolPas encore d'évaluation
- Exercices TP Systemes AlgebriquesDocument14 pagesExercices TP Systemes AlgebriquesWeam MouloudiPas encore d'évaluation
- TP MatlabDocument14 pagesTP MatlabLakhdari BoutheinaPas encore d'évaluation
- TP OssDocument5 pagesTP OssJosephine NoroPas encore d'évaluation
- MathsDocument28 pagesMathsHenschel ShadracPas encore d'évaluation
- These Bendaoud Mohamed Habib Partie 3Document21 pagesThese Bendaoud Mohamed Habib Partie 3Nabil AksilPas encore d'évaluation
- Methode Des Moindres Carres GeneralisesDocument3 pagesMethode Des Moindres Carres Generalisessokhnadiarragueye998Pas encore d'évaluation
- Exercices d'intégrales de lignes, de surfaces et de volumesD'EverandExercices d'intégrales de lignes, de surfaces et de volumesPas encore d'évaluation
- AtemengueDocument1 pageAtemengueJean Jacques Atemengue ZamePas encore d'évaluation
- AnumII-Ch5 EqNumDocument13 pagesAnumII-Ch5 EqNumJean Jacques Atemengue ZamePas encore d'évaluation
- AnumII-Ch4 IntNumDocument68 pagesAnumII-Ch4 IntNumJean Jacques Atemengue ZamePas encore d'évaluation
- Fiche 1,2,3 D'optiqueDocument9 pagesFiche 1,2,3 D'optiqueJean Jacques Atemengue ZamePas encore d'évaluation
- AnumII Ch3 - ApproxNumFunc IntroDocument34 pagesAnumII Ch3 - ApproxNumFunc IntroJean Jacques Atemengue ZamePas encore d'évaluation
- Cours Optique Chap90Document21 pagesCours Optique Chap90Jean Jacques Atemengue ZamePas encore d'évaluation
- Liste Des Applications - BUSINESSDYNAMITEDocument13 pagesListe Des Applications - BUSINESSDYNAMITEJean Jacques Atemengue ZamePas encore d'évaluation
- Exercices Deplacement Des Pièces v3Document5 pagesExercices Deplacement Des Pièces v3Jean Jacques Atemengue ZamePas encore d'évaluation
- ICihWOs7Jz0 - L ART DE LA VICTOIREDocument4 pagesICihWOs7Jz0 - L ART DE LA VICTOIREJean Jacques Atemengue ZamePas encore d'évaluation
- Outils Developpement WebDocument136 pagesOutils Developpement WebJean Jacques Atemengue ZamePas encore d'évaluation
- Livre Blanc e CommerceDocument45 pagesLivre Blanc e CommerceJean Jacques Atemengue ZamePas encore d'évaluation
- TDIntNum19 PDFDocument2 pagesTDIntNum19 PDFretsam V7Pas encore d'évaluation
- EXOS1Document2 pagesEXOS1aerraerPas encore d'évaluation
- Oraux 2016 Solutions SiteDocument109 pagesOraux 2016 Solutions SiteProcopiusPas encore d'évaluation
- PCC 8Document7 pagesPCC 8Snaiki RedaPas encore d'évaluation
- Ef Corrige Maths1 SM 2017 2018 PDFDocument4 pagesEf Corrige Maths1 SM 2017 2018 PDFRai newPas encore d'évaluation
- Calcul IntegralDocument29 pagesCalcul IntegralMame Diarra Bousso DiengPas encore d'évaluation
- Serie Dex 4 Alg 1Document3 pagesSerie Dex 4 Alg 1sidi mohamed el amine nekkalPas encore d'évaluation
- Chapitre 6Document34 pagesChapitre 6Karima AitPas encore d'évaluation
- Suite Exercices CorrigesDocument24 pagesSuite Exercices Corrigesdimbyhasina03Pas encore d'évaluation
- TD Eac 21 22 3Document1 pageTD Eac 21 22 3Kossel LeguezimPas encore d'évaluation
- Integral e 2Document47 pagesIntegral e 2TDMA2009100% (1)
- Progmaths AgregaDocument11 pagesProgmaths AgregaHaytem bossPas encore d'évaluation
- Maths Appliquées - Ch3 - PR FAJRIDocument33 pagesMaths Appliquées - Ch3 - PR FAJRIGifted MouhcinePas encore d'évaluation
- Chapitre 3Document22 pagesChapitre 3youcef mokranePas encore d'évaluation
- No16 04 Jan 2024 Sujetexa - ComDocument1 pageNo16 04 Jan 2024 Sujetexa - ComDjoukoPas encore d'évaluation
- Série 2 Vecteurs Translation 3APIC FRDocument2 pagesSérie 2 Vecteurs Translation 3APIC FRyassmineaitbaPas encore d'évaluation
- Cours de Maths 1° Année SNVDocument18 pagesCours de Maths 1° Année SNVSergio Rodríguez100% (9)
- Serie Har MoniqueDocument3 pagesSerie Har Moniqueche7tPas encore d'évaluation
- Exo RedDocument2 pagesExo Redwijdane imerPas encore d'évaluation
- Cours MGD MgiDocument37 pagesCours MGD MgiDABAKH LDEEBOYPas encore d'évaluation
- Cours de Math CompletDocument23 pagesCours de Math CompletSimo LmfaddelPas encore d'évaluation
- Examen de Rattrapge Analyse2 Avec Corrige 2018-2019Document3 pagesExamen de Rattrapge Analyse2 Avec Corrige 2018-2019zebivitePas encore d'évaluation
- Les Fonctions Exponentielles Et LogarithmesDocument12 pagesLes Fonctions Exponentielles Et LogarithmesFaïçal ZoubirPas encore d'évaluation
- Espaces PréhilbertiensDocument6 pagesEspaces PréhilbertiensEssaidi AliPas encore d'évaluation
- Fic 00055Document20 pagesFic 00055ham.karimPas encore d'évaluation
- 2 SM Les Nombres Complexes Said Koraibi (TC R) :) Introduction de L'ensembleDocument17 pages2 SM Les Nombres Complexes Said Koraibi (TC R) :) Introduction de L'ensembleZakaria BenlafqihPas encore d'évaluation
- 9782705669249Document20 pages9782705669249MolayHmadBlmPas encore d'évaluation
- Fic 00136Document9 pagesFic 00136Sandy InessPas encore d'évaluation
- Programmation Analyse Num Erique: Licence 2 - Maths InfoDocument63 pagesProgrammation Analyse Num Erique: Licence 2 - Maths InfoDavid SagePas encore d'évaluation
- Serie NumeriquesDocument105 pagesSerie NumeriqueshhhhhgPas encore d'évaluation