Académique Documents
Professionnel Documents
Culture Documents
Analysededonnaesavecspss
Transféré par
N AbderrahimTitre original
Copyright
Formats disponibles
Partager ce document
Partager ou intégrer le document
Avez-vous trouvé ce document utile ?
Ce contenu est-il inapproprié ?
Signaler ce documentDroits d'auteur :
Formats disponibles
Analysededonnaesavecspss
Transféré par
N AbderrahimDroits d'auteur :
Formats disponibles
Année universitaire 2021 – 2022
Master Ingénierie de la décision
Semestre 3
Outils logiciels d'analyse de données : SPSS
Pr. A. ELOUARDIGHI
Analyse de données avec SPSS 1
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
PARTIE 1:
PRESENTATION ET MANIPULATION DE BASE DE
SPSS
Analyse de données avec SPSS 2
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
1 Présentation Rapide de SPSS
SPSS est un système complet d’analyse de données. SPSS peut utiliser les données de presque tout type
de fichier pour générer des rapports mis en tableau, des diagrammes de distributions et de tendances, des
statistiques descriptives et des analyses statistiques complexes.
1.1 Les fenêtres
Il existe sept types de fenêtres dans SPSS :
• Editeur de données : Cette fenêtre affiche le contenu du fichier de données. Cette fenêtre
s’ouvre automatiquement lorsqu’on lance SPSS. A partir de la version 14 On peut ouvrir
plusieurs sources de données en même temps.
• Navigateur : Toutes les résultats statistiques, tableaux et graphiques s’affichent dans le
navigateur. Cette fenêtre s’ouvre automatiquement la première fois qu’on exécute une
procédure qui génère des résultats.
• Editeur de tableaux pivotants : Les résultats affichés dans les tableaux pivotants peuvent être
modifiés de diverses manières grâce à cet éditeur.
• Editeur de graphiques : On peut modifier les graphiques et diagramme dans cette fenêtre.
• Editeur de résultats : Les résultats qui ne sont pas affichés dans le tableau pivotants peuvent
être modifiés grâce à cet éditeur.
• Editeur de syntaxe : On peut modifier la syntaxe de commande pour utiliser les fonctions
spéciales de SPSS qui ne sont pas disponible dans la boîte de dialogue. On peut aussi les
enregistrer dans un fichier pour une utilisation ultérieure.
• Editeur de script : Permet de personnaliser et d’automatiser de nombreuses tâches de SPSS.
1.2 Les menus
Un grand nombre de tâches qu’on peut effectuer avec SPSS commence par des choix dans des menus.
Chaque fenêtre a sa propre barre de menus avec les sélections de menus propres à ce type de fenêtre.
1.3 Barres d’outils
Chaque fenêtre a sa propre barre d’outils offrant un accès rapide aux tâches courantes. Les info-bulles
donnent une brève description de chaque outil lorsqu’on place le pointeur de la souris sur l’outil.
1.4 Boîtes de dialogue
Dans SPSS, la plupart des options des menus ouvrent des boîtes de dialogue. Elles permettent de
sélectionner des variables et des options pour effectuer des analyses.
Chacune des boîtes de dialogue comporte plusieurs éléments :
• Liste des variables sources : Liste de variables du fichier de travail.
• Liste des variables cibles : Une ou plusieurs listes indiquant les variables choisies pour
l’analyse.
• Boutons de commande : Boutons qui demandent à SPSS de procéder à une action.
Analyse de données avec SPSS 3
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
La plupart des boîtes de dialogue présentent cinq boutons de commande standard :
• OK : Exécute la procédure.
• Coller : Génère la syntaxe de la commande.
• Réinitialiser : Désélectionne les variables sélectionnées.
• Annuler : Annule les modifications apportées aux paramètres et ferme la boîte de dialogue.
• Aide : Permet d’accéder à un écran d’aide qui contient les informations sur la boite de dialogue
courante.
Les boutons dont le nom est suivi de points de suspension (…) indiquent qu’une sous-boîte de dialogue
peut s’afficher.
La plupart des sous-boîtes de dialogue présentent trois boutons de commande standard :
• Poursuivre: Sauve les sélections et ferme la sous-boîte.
• Annuler : Annule tous les changements intervenus dans la sous-boîte de dialogue et ferme
celle-ci.
• Aide : Fournit une aide contextuelle pour cette sous-boite de dialogue.
Pour sélectionner une variable, il suffi de la mettre en sur brillance dans la liste des variables sources et
de cliquer sur la flèche droite à côté de la liste des variables cibles.
1.5 Procédure de base dans l’analyse de données
• Entrer les données dans SPSS : On peut ouvrir un fichier de données SPSS existant, importer
des données d’une autre source ou introduire directement les données dans l’Editeur de
données.
• Sélectionner une procédure : Sélectionner une procédure dans les menus
• Sélectionner les variables à l’analyse : Les variables du fichier de données s’affichent dans
une boîte de dialogue.
• Exécuter la procédure et examiner les résultats : Les résultats s’affiche dans le Navigateur.
1.6 Les différentes formats de données
Les données caractérisent les différents aspects des exemples. Une donnée a un type et des valeurs
possibles pour ce type. Les différents formats de données:
• Données Quantitatives ou Echelle (Continue ou discrète)
o Exemple : salaire, âge, nombre d’enfants …
• Données Qualitatives ou Ensemble
o Nominale, avec deux ou plusieurs modalités. Exemple: sexe, couleur, profession…
o Ordinale, avec deux ou plusieurs modalités mais ordonnées. Exemple (chaud, tiède,
froid)
Analyse de données avec SPSS 4
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
1.7 Ouverture d’un fichier de données
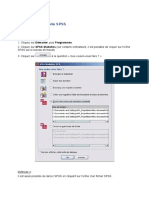
A partir des menus, sélectionnez : Fichier > Ouvrir > Données
Ouvrir le fichier demo.sav.
C:\Program Files\IBM\SPSS\Statistics\19\Samples\English\demo.sav.
Le fichier de données apparaît dans l’Editeur de données.
Figure 1.1 Fichier demo.sav dans l’Editeur de données
Par défaut, les valeurs de données réelles sont affichées. Pour afficher les étiquettes :
A partir des menus, sélectionnez : Affichage > Etiquettes de valeurs
On peut utiliser aussi le bouton Etiquettes de valeurs dans la barre d’outils :
Des étiquettes de valeurs descriptives s’affichent pour faciliter l’interprétation des réponses.
Analyse de données avec SPSS 5
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Figure 1.2 : Etiquettes de valeurs affichées dans l’éditeur de données
1.8 Exécution d’une analyse
A partir des menus, sélectionnez : Analyse > Statistiques descriptives > Effectifs
La boîte de dialogue Effectifs s’affiche.
Figure 1.3 : Boîte de dialogue Effectifs
Analyse de données avec SPSS 6
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Une icône à côté de chaque variable fournit des informations sur le type de données et le niveau de
mesure.
Vous pouvez obtenir des informations supplémentaires en cliquant avec le bouton droit sur tout nom de
variable dans la liste.
Cliquez avec le bouton droit de la souris sur la variable Income category et sélectionnez
Informations de la variable.
Cliquez sur la flèche vers le bas dans la liste déroulante Etiquettes de valeurs.
Figure 1.4 : Etiquettes définies pour les variables de revenus
Analyse de données avec SPSS 7
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Cliquez sur Gender dans la liste des variables source, puis faites glisser la variable dans la liste
cible Variable(s).
Cliquez sur la variable Income category dans la liste source, puis faites-la glisser vers la liste
cible.
Figure 1.5 : Variables sélectionnées pour l’analyse
Cliquez sur OK pour exécuter la procédure.
Figure 1.6 : Fenêtre du Résultats
Analyse de données avec SPSS 8
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2. Saisie de données dans SPSS
2.1 Saisie de données dans SPSS
Cette opération s’effectue en deux étapes :
• Définir les variables et leurs propriétés ;
• Saisir les données.
Définir les variables et leurs propriétés
Double-cliquer sur le titre de la colonne « var » qui contiendra la première variable Ou sur
Affichage des variables.
La zone Nom sert à nommer la variable. Les règles suivantes s’appliquent pour les noms des
variables :
• Chaque nom de variable doit être unique
• Les noms de variable peuvent contenir jusqu’à 64 octets, le premier caractère étant une
lettre ou l’un des caractères suivants : @, # ou $.
• Les noms de variable ne doivent pas contenir d’espaces.
• Le point, le trait de soulignement et les caractères $, # et @ peuvent être utilisés dans les
noms de variable. Par exemple, A._$@#1 est un nom de variable valide.
• Evitez les noms de variable se terminant par un point ou des traits de soulignement
• Les mots-clés réservés ne peuvent pas être utilisés pour les noms de variables : Les
mots-clés réservés sont ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO et
WITH.
• Les noms de variables peuvent être définis par n’importe quelle combinaison de
majuscules et de minuscules. La casse est respectée pour des raisons d’affichage.
La zone Type permet de définir le type de variable. Les types de données disponibles sont les
suivants :
• Numérique : Variable dont les valeurs sont des nombres.
• Virgule : Variable numérique dont les valeurs sont affichées avec des virgules toutes les
trois positions, le point servant de séparateur décimal.
• Point : Variable numérique dont les valeurs sont affichées avec des points toutes les
trois positions, la virgule servant de séparateur décimal.
• Notation scientifique : Variable numérique dont les valeurs sont affichées avec un E
intégré et un exposant de puissance dix avec signe.
• Date : Variable numérique dont les valeurs sont affichées dans l’un des formats de date
ou d’heure possibles.
• Dollar : Variable numérique affichée avec le signe dollar ($), avec des virgules toutes
les trois positions, le point servant de séparateur décimal. Vous pouvez entrer des
valeurs de données avec ou sans le signe dollar.
• Symbole monétaire : Variable numérique dont les valeurs sont affichées dans l’un des
formats monétaires personnalisés que vous avez définis dans l’onglet Devise de la boîte
de dialogue Options.
• Chaîne : Variable dont les valeurs ne sont pas numériques et ne sont donc pas utilisées
pour les calculs. Ces valeurs peuvent contenir n’importe quel caractère, dans la limite
de la longueur définie. Les majuscules et les minuscules sont différenciées.
Analyse de données avec SPSS 9
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
La zone Largeur permet de spécifier le nombre de caractères définissant la largeur des
colonnes. Vous pouvez également modifier la largeur des colonnes dans Affichage des données
en cliquant et en tirant les bords des colonnes. La largeur des colonnes affecte seulement
l’affichage des valeurs dans l’éditeur de données. Modifier la largeur de la colonne ne change
pas la largeur définie d’une variable.
La zone Décimales permet de spécifier le nombre de chiffre après la virgule.
La zone Etiquette permet de donner une identification plus explicite à la variable. Vous pouvez
attribuer des étiquettes de variables descriptives dont le nombre de caractères ne dépasse pas
256. Les étiquettes de variable peuvent contenir des espaces et des caractères réservés qui ne
sont pas autorisés dans les noms de variable.
La zone Valeur permet d’affecter des étiquettes descriptives de valeur pour chaque valeur d'une
variable (par exemple, les codes 1 et 2 pour homme et femme). Ce processus se révèle
particulièrement utile si votre fichier de données utilise des codes numériques pour représenter
des modalités non numériques (par exemple, les codes 1 et 2 pour homme et femme).
La zone manquant permet de définir les valeurs de données spécifiées comme valeurs
manquantes spécifiées par l’utilisateur. Les valeurs des données définies comme valeurs
utilisateur manquantes sont repérées par un indicateur en vue d’un traitement spécial et sont
exclues de la plupart des calculs. Vous pouvez entrer jusqu’à trois valeurs manquantes de votre
choix, un intervalle de valeurs manquantes ou un intervalle plus une valeur de votre choix.
Figure 2.1 : Boîte de dialogue Valeurs manquantes
La zone Colonne permet de spécifier le nombre de colonne pour les variables.
La zone Aligner permet de spécifier l’alignement des variables.
La zone Mesure permet de spécifier les types d’échelle de mesure des variables. Vous pouvez
spécifier un niveau de mesure d’échelle (données numériques), ordinal ou nominal Les données
nominales et ordinales peuvent être des chaînes de caractères (alphanumériques) ou numériques.
• Nominal. Une variable peut être traitée comme étant nominale si ses valeurs représentent
des modalités sans classement intrinsèque (par exemple, le service de la société dans lequel
travaille un employé). La région, le code postal ou l’appartenance religieuse sont des
exemples de variables nominales.
• Ordinal. Une variable peut être traitée comme étant ordinale si ses valeurs représentent des
modalités associées à un classement intrinsèque (par exemple, des niveaux de satisfaction
allant de Très mécontent à Très satisfait). Exemples de variable ordinale : des scores
d’attitude représentant le degré de satisfaction ou de confiance, et des scores de classement
des préférences.
Analyse de données avec SPSS 10
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
• Echelle. Une variable peut être traitée comme une variable d’échelle (continue) si ses
valeurs représentent des modalités ordonnées avec une mesure significative. L’âge en
années et le revenu en milliers sont des exemples de variable d’échelle.
La zone Rôle permet d’attribuer des rôles prédéfinis pouvant être utilisés pour présélectionner
les variables pour l’analyse. Les rôles disponibles sont :
• Entrée. La variable sera utilisée comme une valeur d’entrée (valeur prédite ou variable
indépendante).
• Cible. La variable sera utilisée comme une variable de destination ou variable cible
(variable dépendante).
• Les deux. La variable sera utilisée aussi bien comme variable d’entrée que variable de
destination.
• Aucune : Aucun rôle n’a été affecté à la variable.
• Partition. La variable sera utilisée pour partitionner les données en échantillons
d’apprentissage, de test et de validation.
• Séparation. Inclus pour la compatibilité.
2.2 Saisie de données numériques
Les données peuvent être saisies dans l’éditeur de données, qui peut s’avérer utile pour traiter
les fichiers de données peu volumineux ou pour apporter de légères modifications à des fichiers
de données plus volumineux.
Lancer IBM SPSS Statistics
Cliquez sur l’onglet Affichage des variables en bas de la fenêtre de l’éditeur de données.
Vous devez définir les variables qui seront utilisées.
Dans cet exemple, seules trois variables sont nécessaires : age, situation et revenu.
Figure 2.2 : Noms de variable dans l’affichage des variables
Dans la première ligne de la première colonne, saisissez age.
Dans la deuxième ligne, saisissez situation.
Dans la troisième ligne, saisissez revenu.
Analyse de données avec SPSS 11
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Un type de données numérique est automatiquement attribué aux nouvelles variables.
Cliquez sur l’onglet Affichage des données pour continuer à saisir des données.
Les noms saisis dans l’affichage des variables sont à présent les en-têtes des trois premières
colonnes de l’affichage des données.
Commencez à saisir des données dans la première ligne, en commençant par la première
colonne.
Dans la colonne age, saisissez 55 ; 53.
Dans la colonne situation, saisissez 1 ; 0.
Dans la colonne revenu, saisissez 72000 ; 153000.
Figure 2.3 : Valeurs entrées dans l’affichage des données
Les colonnes age et situation affichent actuellement un séparateur décimal alors que les valeurs
sont des entiers. Pour masquer le séparateur décimal de ces variables :
Cliquez sur l’onglet Affichage des variables en bas de la fenêtre de l’éditeur de données.
Dans la colonne Décimales de la ligne âge, saisissez 0 pour masquer la décimale.
Dans la colonne Décimales de la ligne situation, saisissez 0 pour masquer la décimale.
Analyse de données avec SPSS 12
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Figure 2.4 : Propriété Décimales des variables age et situation mise à jour
2.3 Saisie de données chaîne
Des données non numériques, telles que des chaînes de texte, peuvent également être saisies
dans l’éditeur de données.
Cliquez sur l’onglet Affichage des variables en bas de la fenêtre de l’éditeur de données.
Dans la première cellule de la première ligne vide, saisissez sexe comme nom de variable.
Cliquez sur la cellule Type à côté.
Cliquez sur le bouton à droite de la cellule Type pour ouvrir la boîte de dialogue Type de
variable.
Figure 2.5 : Boîte de dialogue Type de variable
Sélectionnez Chaîne pour indiquer le type de variable.
Cliquez sur OK pour enregistrer votre sélection et revenir dans l’Editeur de données.
Analyse de données avec SPSS 13
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.4 Définition de données
Outre les données, vous pouvez aussi définir des étiquettes de variables descriptives et des
étiquettes de valeurs pour les noms de variables et les valeurs de données. Ces étiquettes
descriptives sont utilisées dans les rapports statistiques et les diagrammes.
Ajout des étiquettes de variables
Les étiquettes fournissent une description des variables. Elles peuvent s’élever jusqu’à 255
caractères.
Ces étiquettes sont utilisées dans les résultats pour identifier les variables différentes.
Cliquez sur l’onglet Affichage des variables en bas de la fenêtre de l’éditeur de données.
Dans la colonne Etiquette de la ligne age, saisissez l'âge du répondant.
Dans la colonne Etiquette de la ligne situation, saisissez la situation familiale.
Dans la colonne Etiquette de la ligne revenu, saisissez revenu du ménage.
Dans la colonne Etiquette de la ligne sexe, saisissez le sexe.
Figure 2.6 : Etiquettes de variable entrées dans l’affichage des variables
Ajout d’étiquettes de valeur pour les variables numériques
Les étiquettes de valeur correspondent à une façon d’associer aux valeurs de variable des
étiquettes de chaîne.
Dans cet exemple, il y a deux valeurs possibles pour la variable situation. La valeur 0 signifie
que le sujet est célibataire et la valeur 1 qu’il est marié.
Cliquez sur la cellule Valeurs de la ligne situation, puis sur le bouton à droite de la cellule pour
ouvrir la boîte de dialogue Etiquettes de valeur.
o Le champ Valeur correspond à la valeur numérique réelle.
o Le champ Etiquette de valeur correspond à l’étiquette de chaîne appliquée à la valeur
numérique indiquée.
Saisissez 0 dans le champ Valeur.
Saisissez Célibataire dans le champ Etiquette.
Cliquez sur Ajouter pour ajouter l’étiquette à la liste.
Saisissez 1 dans le champ Valeur, puis Marié dans le champ Etiquette.
Analyse de données avec SPSS 14
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Cliquez sur Ajouter, puis sur OK pour enregistrer vos modifications et revenir dans l’éditeur de
données.
Figure 2. 7 : Boîte de dialogue Etiquettes de valeurs
Ajout d’étiquettes de valeur pour les variables chaîne
Les variables chaîne peuvent également nécessiter des étiquettes de valeur. Par exemple, les
lettres M ou F sont utilisées pour identifier le sexe du sujet. Les étiquettes de valeur peuvent
être utilisées pour préciser que M signifie Masculin et F pour Féminin.
Cliquez sur l’onglet Affichage des variables en bas de la fenêtre de l’éditeur de données.
Cliquez sur la cellule Valeurs de la ligne sexe, puis sur le bouton à droite de la cellule pour
ouvrir la boîte de dialogue Etiquettes de valeur.
Saisissez F dans le champ Valeur, puis Féminin dans le champ Etiquette.
Cliquez sur Ajouter pour ajouter l’étiquette au fichier de données.
Figure 2.8: Boîte de dialogue Etiquettes de valeurs
Saisissez M dans le champ Valeur, puis Masculin dans le champ Etiquette.
Cliquez sur Ajouter, puis sur OK pour enregistrer vos modifications et revenir dans l’éditeur de
données.
Les valeurs de chaîne font la distinction entre les majuscules et les minuscules. Le m minuscule
est différent du M majuscule.
Analyse de données avec SPSS 15
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Utilisation des étiquettes de valeurs pour la saisie de données
Vous pouvez utiliser des étiquettes de valeurs pour la saisie de données.
Cliquez sur l’onglet Affichage des données en bas de la fenêtre de l’éditeur de données.
Dans la première ligne, sélectionnez la cellule pour sexe.
Cliquez sur le bouton à droite de la cellule et choisissez Masculin dans la liste déroulante.
Dans la seconde ligne, sélectionnez la cellule pour sexe.
Cliquez sur le bouton à droite de la cellule et choisissez Féminin dans la liste déroulante.
Figure 2.9 : Utilisation d’étiquettes de variable pour sélectionner des valeurs
2.5 Application : Saisie des données
1. Saisissez les données du tableau 1
Salaire Expérience Sexe Evaluation
38000 2 H 2
41000 5 F 1
35000 1 H 2
37000 1 F 3
58000 3 H 1
47000 9 H 2
45000 7 F 3
39000 4 H 3
43000 9 F 3
39000 2 F 2
36000 1 H 2
49000 9 F 1
35000 1 H 2
41000 7 F 1
45000 6 H 2
41000 8 F 1
Tableau 2.1 : Exemple de données
2. Ajouter des étiquettes pour les variables :
• Salaire : « Salaire de l’employé »
• Expérience : « Nombre d’années d’expérience »
• Sexe : « Sexe de l’employé »
• Evaluation : « Evaluation de l’employé »
Analyse de données avec SPSS 16
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3. Ajouter les étiquettes suivantes pour les valeurs des variables sexe et Evaluation
• Sexe : F = Femme ; H = Homme
• Evaluation : 1= Note Faible ; 2= Note moyenne ; 3=Bonne note
2.6 Saisie d’un tableau croisé ou de contingence
Il n’est pas possible de saisir un tableau de contingence directement dans SPSS. Pour remédier à ce
problème, le tableau de contingence sera saisi « à plat » sous la forme de 3 variables : les deux variables
qualitatives et une troisième variable effectif représentant l’effectif de la classe définie par les valeurs
des deux variables. On obtient donc un tableau (SPSS) du type :
Sexe Indice de Effectif
satisfaction
Femme Très satisfait 1
Femme Satisfait 2
Femme Peut satisfait 4
Femme Pas satisfait 1
Homme Très satisfait 2
Homme Satisfait 4
Homme Peut satisfait 2
Homme Pas satisfait 1
Il faut pondérer chaque couple de modalités (chaque ligne du tableau) par l’effectif associé.
Pour cela, on utilise la commande : Données > Pondérer les observations...
Sélectionnez Pondérer les observations par
Déplacez Effectif dans Variable d’effectif et cliquer sur OK
Figure 2.10: Boîte de dialogue Pondérer les observations
Application : L’indice de satisfaction en fonction de sexe :
Satisfaction
Très Satisfait Satisfait Peut satisfait Pas satisfait Total
SEXE Femme 1 2 4 1 8
Homme 2 4 2 1 9
Total 3 6 6 2 17
Tableau 2.2 : Tableau croisé: Sexe*Indice de satisfaction
Analyse de données avec SPSS 17
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3. Lecture des données externes
Les données peuvent être saisies directement ou importées à partir de sources différentes. Ce chapitre
traite des processus de lecture de données dans des applications de feuilles de calcul telles que Microsoft
Excel, dans les applications de base de données telles que Microsoft Access et dans des fichiers texte.
3.1 Lecture d’un fichier texte
L'Assistant de texte permet de lire des fichiers de données texte formatés de différentes façons
• Fichiers délimités par des tabulations
• Fichiers délimités par des espaces
• Fichiers délimités par des virgules
• Fichiers de format fixe
Dans le cas des fichiers délimités, vous pouvez choisir d'autres caractères en guise de séparateurs entre
les valeurs et spécifier plusieurs séparateurs.
Procédure
A partir du menu, sélectionnez : Fichier, puis Lire les données du texte
Sélectionnez le fichier texte dans la boîte de dialogue d'ouverture.
Suivez les étapes de l'Assistant de texte pour définir le mode de lecture du fichier de données.
Application : Ouvrir le fichier texte demo.txt
C:\Program Files\IBM\SPSS\Statistics\19\Samples\English\demo.txt.
L’Assistant d’importation de texte vous guide tout au long du processus permettant de définir le
mode d’impression du fichier texte indiqué.
Figure 3.1 : Assistant d’importation de texte : Etape 1 sur 6
Analyse de données avec SPSS 18
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
A l’étape 1, vous pourrez sélectionner un format prédéfini ou créer un format dans l’Assistant.
Sélectionnez Non pour indiquer qu’un nouveau format doit être créé.
Cliquez sur Suivant pour continuer.
Figure 3.2 : Assistant d’importation de texte : Etape 2 sur 6
Sélectionnez Délimité pour indiquer que les données utilisent une structure de format délimité.
Sélectionnez Oui pour indiquer que les noms de variable doivent être lus à partir du début du
fichier.
Cliquez sur Suivant pour continuer.
Saisissez 2 dans la section supérieure de la boîte de dialogue suivante pour indiquer que la
première ligne de données commence sur la deuxième ligne du fichier texte.
Figure 3.3 : Assistant d’importation de texte : Etape 3 sur 6
Conservez les valeurs par défaut des autres champs de cette boîte de dialogue et cliquez sur
Suivant pour continuer.
Analyse de données avec SPSS 19
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
L’aperçu des données de l’étape 4 vous offre un moyen rapide de vérifier que vos données ont été lues
correctement.
Figure 3.4 : Assistant d’importation de texte : Etape 4 sur 6
Sélectionnez Tab et désélectionnez les autres options.
Cliquez sur Suivant pour continuer.
Etant donné que des noms de variable peuvent avoir été tronqués pour des raisons de formatage, cette
boîte de dialogue vous permet de modifier les noms superflus.
Figure 3.5 : Assistant d’importation de texte : Etape 5 sur 6
Analyse de données avec SPSS 20
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Vous pouvez également définir les types de données dans cette boîte de dialogue. Par exemple,
nous pouvons supposer que la variable de revenus doit contenir une certaine somme en dollars.
Pour modifier un type de données :
Sous l’aperçu de données, sélectionnez la variable à modifier, c’est-à-dire Revenu dans cet
exemple.
Sélectionnez Dollar dans la liste déroulante Format des données.
Figure 3.6 : Sélectionnez le type de données.
Cliquez sur Suivant pour continuer.
Figure 3.7 : Assistant d’importation de texte : Etape 6 sur 6
Conservez les sélections par défaut dans cette boîte de dialogue et cliquez sur Terminer pour
importer les données.
Analyse de données avec SPSS 21
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3.2 Lecture d’un fichier Excel
Au lieu de saisir toutes vos données directement dans l’éditeur de données, vous pouvez les lire
à partir d’applications telles que Microsoft Excel.
Procédure :
A partir du menu, sélectionnez : Fichier > Ouvrir > Données
Dans la boîte de dialogue Ouvrir un fichier, sélectionnez le fichier à ouvrir, en spécifiant le type
du fichier dans notre cas Excel (*.xls)
Cliquez sur Ouvrir.
Vous pouvez :
• lire les noms de variables à partir de la première ligne dans le cas des feuilles de calcul et des
fichiers délimités par des tabulateurs ;
• spécifier une plage de cellules à lire dans le cas de fichiers de feuilles de calcul.
• spécifier une feuille à lire dans un fichier Excel.
Application : Ouvrir dans le fichier demo.xls
C:\Program Files\IBM\SPSS\Statistics\19\Samples\English\demo.xls.
A partir des menus, sélectionnez : Fichier > Ouvrir > Données
Sélectionnez Excel (*:xls) comme type de fichier à afficher.
Ouvrez demo.xls.
La boîte de dialogue Ouvrir la source de données Excel apparaît ; elle permet de choisir si les noms de
variable doivent être inclus dans la feuille de calcul, et d’indiquer les cellules à importer.
Figure 3.8 : Boîte de dialogue Ouvrir la source de données Excel
Vérifiez que la case Lire le nom des variables à partir de la première ligne de données est sélectionnée.
Cette option lit les en-têtes de colonne comme des noms de variable.
Cliquez sur OK pour lire le fichier Excel.
Les données apparaissent à présent dans l’Editeur de données, les en-têtes de colonne étant
utilisés comme noms de variable.
Analyse de données avec SPSS 22
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3.3 Lecture d’une base de données
Les données issues de sources de bases de données peuvent facilement être importées à l’aide de
l’Assistant de base de données. Toute base de données utilisant des pilotes ODBC (Open Database
Connectivity) peut être lue directement une fois ces pilotes installés.
Application : Ouvrir dans le fichier demo.mdb
C:\Program Files\IBM\SPSS\Statistics\19\Samples\English\demo.mdb.
A partir des menus, sélectionnez : Fichier > Ouvrir la base de données > Nouvelle requête...
Figure 3.9 : Boîte de dialogue Ouvrir la source de données Base de données
Sélectionnez Base de données MS Access dans la liste des sources de données et cliquez sur
Suivant.
Cliquez sur Parcourir pour accéder au fichier de base de données Access à ouvrir.
Ouvrez demo.mdb.
Cliquez sur OK dans la boîte de dialogue de connexion.
Figure 3.10 : Boîte de dialogue Connexion au pilote ODBC
Analyse de données avec SPSS 23
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
A l’étape suivante, on indique les tables et les variables qu’on souhaite importer.
Figure 3.11 : Etape Sélectionner des données
Faites glisser le tableau demo vers la liste Récupérer les champs dans cet ordre.
E Cliquez sur Suivant.
A l’étape 4, sélectionnez les enregistrements (observations) à importer. Si on ne souhaite pas importer
toutes les observations, on peut :
Sélectionner un sous-ensemble d’observations (par exemple, les hommes de plus de 30 ans)
Un échantillon aléatoire d’observations dans la source de données.
Pour les sources de données volumineuses, on peut limiter le nombre d’observations à un
échantillon restreint et représentatif afin de réduire la durée du traitement.
Figure 3.12 : Etape Limiter les observations récupérées
Cliquez sur Suivant pour continuer.
Analyse de données avec SPSS 24
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Les noms de champ permettent de créer des noms de variable. Si nécessaire. Les noms de
champ d’origine sont conservés en tant qu’étiquettes de variable. On peut également modifier
les noms de variable avant d’importer la base de données.
Figure 3.12 : Etape Définir variables
Cliquez sur la cellule Recoder en numérique dans le champ Sexe. Cette option convertit
les variables chaîne en variables numériques (entiers) et conserve la valeur d’origine
comme étiquette de valeur de la nouvelle variable.
Cliquez sur Suivant pour continuer.
Analyse de données avec SPSS 25
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
L’instruction SQL créée à partir de vos sélections dans l’Assistant de base de données apparaît à
l’étape Résultats. Cette instruction peut être exécutée immédiatement ou enregistrée dans un
fichier pour une utilisation ultérieure.
Figure 3.13 : Etape Résultats
Cliquez sur Terminer pour importer les données.
Toutes les données de la base de données Access sélectionnées pour l’importation sont à
présent disponibles dans l’éditeur de données.
Figure 3 .14 : Données importées à partir d’une base de données Access
Analyse de données avec SPSS 26
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
4. Exemples de préparation et transformation de données
4.1 Les fonctions de tri
La fonction tri est identique à toutes les fonctions tri que l’on peut trouver sur des logiciels comme
Excel, à savoir qu’il suffit de définir l’ordre (croissant ou décroissant). On peut trier les variables ou les
observations.
Pour Trier les observations :
A partir du menu Données choisisse trier les observations
On obtient la boîte de dialogue Trier les observations
Figure 4.1 : Boîte de dialogue Trier les observations
Déplacer la variable à trier et choisissez l’ordre de tri
Pour Trier les variables:
A partir du menu Données choisisse trier les variables
On obtient la boîte de dialogue Trier les variables
Figure 4.2 : Boîte de dialogue Trier les variables
Choisissez Une colonne d’affichage des variables et l’ordre de tri
Analyse de données avec SPSS 27
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
4.2 Sélectionner des observations
Sélectionner les observations propose une série de méthodes pour sélectionner un sous-groupe
d’observations en fonction de certains critères qui incluent variables et expressions complexes. Vous
pouvez également sélectionner un échantillon aléatoire d’observations. L’utilisation de cette fonction
génère une nouvelle variable « filter_$ » binaire (1 si l’observation est considérée, 0 si elle est exclue).
Les critères utilisés pour définir un sous-groupe comprennent :
Toutes les observations. Désactive le filtrage d’observation et utilise toutes les observations.
Selon une condition logique. Utilise une expression conditionnelle pour sélectionner les observations.
Si le résultat de l’expression conditionnelle est vrai, l’observation est sélectionnée.
Si le résultat est faux ou manquant, l’observation n’est pas sélectionnée.
Par échantillonnage aléatoire. Sélectionne un échantillon aléatoire basé sur un pourcentage
approximatif ou un nombre exact d’observations.
Dans un intervalle de temps ou d’observations. Sélectionne des observations selon un intervalle de
numéros d’observations ou un intervalle de dates/heures.
Selon une variable filtre. Utilise comme variable de filtre la variable numérique sélectionnée dans le
fichier de données. Les observations dont la valeur de la variable filtre est autre que manquante ou nulle
sont sélectionnées.
Pour Sélectionner les observations
A partir du menu Données choisissez sélectionner les observations
On obtient la boîte de dialogue Sélectionner les observations
Figure 4.3 : Boîte de dialogue Sélectionner les observations
Choisissez le critère de sélection des observations
Analyse de données avec SPSS 28
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
4.3 Recodage automatique des variables
Le recodage automatique convertit les valeurs numériques et les valeurs alphanumériques en entiers
consécutifs.
Les nouvelles variables créées par le Recodage automatique conservent toute variable définie et les
étiquettes de valeurs de l’ancienne variable.
Les valeurs de chaîne sont recodées dans l’ordre alphabétique, les majuscules précédant leurs
équivalents minuscules. Les valeurs manquantes sont recodées en valeurs manquantes supérieures à
toutes valeurs non manquantes, en conservant leur ordre.
A partir du menu Transformer sélectionner Recoder automatiquement…
Figure 4.4 : Boîte de dialogue Recoder automatiquement
Sélectionnez les variables à recoder.
Dans le champ « Nouveau nom », taper un nom pour la nouvelle variable, puis cliquez sur
Ajouter un nouveau nom.
Application : Recoder automatiquement la variable gender du fichier demo.sav
Analyse de données avec SPSS 29
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
5. Exporter des résultats
On peut exporter les résultats vers un fichier Microsoft Word, PowerPoint, PDF ou Excel. On peut
exporter les éléments sélectionnés ou tous les éléments de la fenêtre résultats.
Procédure :
A partir du menu, sélectionnez : Fichier puis Exporter...
Entrez un nom de fichier et sélectionnez un format d'exportation
Figure 4.1 : Export des résultats vers un document PDF
Application :
Exporter des résultats vers un document PDF, HTML, Texte et Excel
Analyse de données avec SPSS 30
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
PARTIE 2:
ANALYSE DE DONNEES AVEC SPSS
Analyse de données avec SPSS 31
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
TP 1
Classification Hiérarchique et non Hiérarchique
Définition du problème et des objectifs
Quelles villes ont des profils météo similaires ?
Sources de données
• Fichier source Température.sav
o 15 Individus : villes de France
o 12 Variables : températures mensuelles moyennes sur 30 ans.
Elaboration du modèle
✓ Appliquer la classification Hiérarchique et non hiérarchique (Nuée dynamique) sur ces données
permettant d'identifier des groupes de villes similaires
✓ Comparer les résultats obtenus avec les deux méthodes
✓ En utilisant la classification ascendante hiérarchique, Construire l'arbre hiérarchique sur ces
données permettant d'identifier des groupes de villes similaires
✓ Caractériser les groupes de villes
Analyse de données avec SPSS 32
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
I- Classification non Hiérarchique : Nuée dynamique
1 Présentation
Classer les objets du jeu de données sont groupés en k clusters
Étant donnée une valeur k, trouver une partition de k clusters qui optimise le critère de partitionnement
(fonction de similarité)
Chaque cluster est représenté par son centre de gravité
2 Les procédures de base
2.1 Obtenir une analyse de Nuées dynamiques
A partir des menus, sélectionnez :
Analyse > Classification > Nuées dynamique
2.2 Nuées dynamique
Sélectionnez les variables à utiliser dans l’analyse.
Spécifiez le nombre de classes. Le nombre de classes doit être au moins de deux et ne doit pas
être supérieur au nombre d’observations contenues dans le fichier de données.
Analyse de données avec SPSS 33
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.3 Itérer
Cette boîte de dialogue permet de fixer le nombre maximum des itérations et le critère de convergence
2.4 Enregistrer
Classe(s) d’affectation : Crée une nouvelle variable indiquant la classe d’affectation finale de chaque
observation. Les valeurs de la nouvelle variable vont de 1 au nombre de classes.
Distance au centre de classe : Crée une nouvelle variable indiquant la distance euclidienne entre chaque
nouvelle variable et son centre de classification.
2.5 Options
Statistiques. Vous pouvez sélectionner les statistiques suivantes : Centres de classes initiaux, Tableau
ANOVA, et Affectation et distances au centre.
Analyse de données avec SPSS 34
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Résultats obtenus de la classification des nuées dynamiques avec 3
classes
Affiche les centres des classes de départ
Affiche l'historique des itérations
La méthode à converger en 2 itérations
Analyse de données avec SPSS 35
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Affiche l'appartenance et la distance de chaque ville à chaque classe
Affiche le centre des classes finales
Permet de caractériser chaque classe
Affiche le nombre d'observation de chaque classe
Analyse de données avec SPSS 36
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
II- Classification Hiérarchique
1 Présentation
Production d'une structure (arborescence) permettant :
• La mise en évidence de liens hiérarchique entre individus ou groupe d'individus
• La détection d'un nombre de classes au sein de la population
• En définissant un point de coupure, en définit une partition
2 Les procédures de base
2.1 Obtenir une classification hiérarchique
A partir des menus, sélectionnez :
Analyse > Classification > Classification hiérarchique
2.2 Classification hiérarchique
Sélectionnez au moins une variable numérique
Si c'est possible sélectionner une variable d’identification pour étiqueter les observations.
2.3 Statistique
Chaîne des agrégations : Affiche les observations ou les classes combinées à chaque étape
Matrice des distances : Indique les distances ou les similarités entre éléments.
Classe(s) d’affectation : Affiche le groupe auquel chaque observation appartient lors d’une ou plusieurs
étapes de la combinaison de classes
Analyse de données avec SPSS 37
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.4 Diagramme
Arbre hiérarchique : Affiche un dendrogramme. Les arbres hiérarchiques peuvent être utilisés pour
évaluer la cohésion des groupes formés et ils fournissent des renseignements sur le nombre approprié de
groupes à conserver.
Stalactites : Affiche un diagramme en stalactite, incluant tous les groupes ou une plage de groupes
spécifiée
Analyse de données avec SPSS 38
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.5 Méthode
Méthode d’agrégation : Les choix disponibles sont : la Distance moyenne entre classes, la Distance
moyenne dans les classes, l’Agrégation suivant le saut minimum, l’Agrégation suivant le diamètre, les
Barycentres, la Médiane et la Méthode de Ward.
Mesure : Il permet de spécifier la mesure de distance ou de similarité devant être utilisée pour la
classification
2.6 Enregistrer
Classe(s) d’affectation : Vous permet de sauvegarder les classes d’affectation pour une ou plusieurs ou
aucune partition(s). Les variables sauvegardées peuvent alors être utilisées pour des analyses ultérieures
pour explorer d’autres différences entre groupes.
Analyse de données avec SPSS 39
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Arbre Hiérarchique obtenu
Analyse de données avec SPSS 40
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
TP 2
Analyse en Composante Principale
1 Présentation
1.1 Analyse factorielle
L'analyse factorielle essaie d'identifier des variables sous-jacentes, ou facteurs, qui permettent
d'expliquer le patron des corrélations à l'intérieur d'un ensemble de variables observées. L'analyse
factorielle est souvent utilisée pour réduire un ensemble de données. L'analyse factorielle est souvent
utilisée dans la factorisation, en identifiant un petit nombre de facteurs qui expliquent la plupart des
variances observées dans le plus grand nombre de variables manifestes.
2 Les procédures de base
2.1 Pour obtenir une analyse factorielle
Cliquez sur la commande Analyse puis glissez le pointeur de la souris sur Réduction des dimensions
puis sur Analyse factorielle.... Nous obtenons la boîte de dialogue Analyse factorielle
Sélectionnez les variables pour l'analyse factorielle.
Analyse de données avec SPSS 41
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.2 Caractéristiques d'analyse factorielle
Dans la boîte de dialogue Analyse factorielle, cliquez sur Descriptive
On obtient la boîte de dialogue Analyse Factorielle : Caractéristiques
Statistiques. Les statistiques univariées incluent la moyenne, l'écart-type, et le nombre d'observations
valides pour chaque variable. La structure initiale affiche la qualité de représentation initiale, les valeurs
propres, et le pourcentage de variance expliqué.
Matrice de corrélation. Les options disponibles sont les coefficients, les seuils de signification, les
déterminants, les inverses, les reproduits, l'anti-image et l'indice KMO et le test de sphéricité de Bartlett.
2.3 Extraction d'analyse factorielle
Dans la boîte de dialogue Analyse factorielle, cliquez sur Extraction….
On obtient la boîte de dialogue Analyse Factorielle : Extraction
Analyse de données avec SPSS 42
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Méthode. Vous permet de spécifier la méthode d'extraction de facteur. Les méthodes disponibles sont
les Composantes principales, les Moindres carrés non pondérés, les Moindres carrés généralisés, le
Maximum de vraisemblance, la Factorisation en axes principaux, l'Alpha-maximisation, et la
Factorisation en projections.
Analyse. Vous permet de spécifier si l'analyse porte sur une matrice de corrélation ou sur une matrice
de covariance.
Extraire. Vous pouvez retenir tous les facteurs dont les valeurs propres dépassent une valeur spécifique
ou retenir un nombre spécifique de facteurs.
Afficher. Vous permet de demander la solution factorielle avant rotation et un diagramme des valeurs
propres.
Maximum des itérations pour converger. Vous permet de spécifier le nombre maximum de pas que
l'algorithme peut prendre pour estimer la solution.
2.4 Rotation d'analyse factorielle
Dans la boîte de dialogue Analyse factorielle, cliquez sur Rotation….
On obtient la boîte de dialogue Analyse Factorielle : Rotation
Méthode. vous permet de sélectionner la méthode de rotation des facteurs. Les méthodes disponibles
sont Varimax, Oblimin directe, Quartimax, Equamax ou Promax.
Afficher. vous permet d'inclure le résultat de la structure après rotation, et également d'afficher les
cartes factorielles sur le premier, le second et le troisième facteur (Cartes factorielles).
Maximum des itérations pour converger. vous permet de spécifier le nombre maximum de pas que
l'algorithme peut utiliser pour réaliser la rotation.
Analyse de données avec SPSS 43
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.5 Les options de facteurs
Dans la boîte de dialogue Analyse factorielle, cliquez sur Facteurs…
On obtient la boîte de dialogue Analyse Factorielle : Facteurs
Enregistrer dans des variables. vous permet de créer une nouvelle variable pour chaque facteur selon
la structure finale. Sélectionnez une des méthodes alternatives suivantes pour calculer les facteurs :
Régression, Bartlett, ou Anderson-Rubin.
Afficher la matrice des coefficients factoriels. vous permet de montrer les coefficients par lesquels les
variables sont multipliées pour obtenir les facteurs. Cela permet également de montrer les corrélations
entre les facteurs.
2.6 Options d'analyse factorielle
Dans la boîte de dialogue Analyse factorielle, cliquez sur Options…
On obtient la boîte de dialogue Analyse Factorielle : Options
Valeurs manquantes. Vous permet de spécifier comment traiter les valeurs manquantes. Les options
disponibles sont d'Exclure toute observation incomplète, d'Exclure seulement les composantes non
valides, ou de les Remplacer par la moyenne.
Format d’affichage des coefficients. Vous permet de contrôler le format des matrices de résultat. Triez
les coefficients par leur taille (option Classement des variables par taille) et supprimez les coefficients
dont la valeur absolue est inférieure à la valeur spécifiée.
Analyse de données avec SPSS 44
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3 Analyse d’une ACP
Analyser les résultats d’une ACP, c’est répondre à trois questions :
1. Les données sont-elles factorisables ?
2. Combien de facteurs retenir ?
3. Comment interpréter les résultats ?
3.1 Les données sont-elles factorisables ?
Pour répondre à cette question, dans un premier temps, il convient d’observer la matrice des
corrélations. Si plusieurs variables sont corrélées (> 0.5), la factorisation est possible. Si non, la
factorisation n’a pas de sens.
Dans un deuxième temps, il faut observer l’indice de KMO (Kaiser-Meyer-Olkin) qui doit tendre vers 1.
si ce n’est pas le cas, la factorisation n’est pas conseillée. Pour juger de l’indice de KMO, on peut
utiliser l’échelle suivante :
• 0,50 et moins est misérable
• entre 0,60 et 0,70, c’est médiocre
• entre 0,70 et 0,80 c’est moyen
• entre 0,80 et 0,90 c’est méritoire
• et plus 0,9 c’est merveilleux.
Enfin, on utilise le test de sphéricité de Bartlett. :
• si la signification (Sig.) tend vers 0.000, c’est très significatif,
• inférieur à 0.05 significatif,
• entre 0.05 et 0.10 acceptable
• et au dessus de 0.10, on rejette.
Analyse de données avec SPSS 45
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Si au moins deux de ces trois conditions sont satisfaites, l’ACP est justifiable.
3.2 Combien de facteurs retenir ?
Trois règles sont applicables :
• 1ère règle : la règle de Kaiser qui veut qu’on ne retienne que les facteurs aux valeurs propres
supérieures à 1(Règle choisie par défaut).
• 2ème règle : on choisit le nombre d’axe en fonction de la restitution minimale d’information que
l’on souhaite. Par exemple, on veut que le modèle restitue au moins 80% de l’information.
Pour ces deux premières règles, on examine le tableau « Variance totale expliqué».
Variance totale expliquée
Valeurs propres initiales Extraction Sommes des carrés des facteurs retenus
% de la % de la
Composante Total variance % cumulés Total variance % cumulés
1 4,761 79,343 79,343 4,761 79,343 79,343
2 ,989 16,487 95,831 ,989 16,487 95,831
3 ,202 3,365 99,196
4 ,035 ,576 99,772
5 ,009 ,151 99,923
6 ,005 ,077 100,000
• 3ème méthode : le test du coude. On observe le graphique des valeurs propres et on ne retient que
les valeurs qui se trouvent à gauche du point d’inflexion. Graphiquement, on part des
composants qui apportent le moins d’information (qui se trouvent à droite), on relie par une
droite les points presque alignés et on ne retient que les axes qui sont au dessus de cette ligne.
3.3 Interprétation des résultats
C’est la phase la plus délicate de l’analyse. On donne un sens à un axe grâce à une recherche lexicale
(ou recherche de mots) à partir des coordonnées des variables et des individus. Ce sont les éléments
extrêmes qui concourent à l’élaboration des axes.
Matrice des composantes
Composante
1 2
prix -,903 ,390
gout ,988 ,056
legerte ,930 ,132
disponi ,454 ,876
emballag ,952 -,220
image ,995 -,014
Si la variance expliquée est trop faible, on peut choisir d’exclure certaines variables. Pour choisir les
variables à éliminer, on observe leur qualité de représentation : plus la valeur associée à la ligne «
Extraction » est faible, moins la variable explique la variance.
Analyse de données avec SPSS 46
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Il faut également tenir compte du positionnement de chaque variable sur chaque axe :
Les variables à éliminer sont les variables qui sont :
• Soit proches du centre sur l’ensemble des axes retenus.
• Soit au milieu d’un quart de cercle sur les axes retenus.
• Soit les variables qui forment un axe à elles toute seule.
Analyse de données avec SPSS 47
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
4 Applications
Manipulation 1
L’objectif de cette manipulation est relatif à une étude de marché pour le positionnement de 10 marques
d’un produit alimentaire. On a retenu 6 caractéristiques : prix, goût, légèreté, disponibilité, emballage et
l’image de marque.
Travail à faire
1. Réaliser l'ACP des individus et des variables des données Produits.sav.
2. Ces données sont-il factorisable ? Justifier votre réponse.
3. Combien de facteurs retenir ?
4. Analyser et interpréter les résultats obtenus
Manipulation 2
L’agence locale de la banque « LCBANK » veut entreprendre une étude visant à mieux connaître la
situation et le comportement bancaire de sa clientèle. Elle souhaite notamment définir des types
homogènes de clients afin de pouvoir élaborer des politiques différenciées pour chacun d’eux. Elle vous
demande de mener cette étude.
Vous utilisez pour cela les données figurant dans ses fichiers de gestion en constituant un
échantillon de 30 titulaires d’un compte courant.
Les variables utilisées sont :
SOLD : Solde moyen du compte courant (en DH).
NDEC : Nombre de mois avec découvert courant lors de l’année précédente.
MDEC : Montant cumulé des découvert sur le compte courant lord de l’année précédente(en
milliers de DH).
NEMP : Nombre total des emprunts divers effectués lors des 5 dernières années.
MEMP : Montant total des emprunts divers effectués lors des 5 dernières années.
VADD : % de variation des dépôts d’épargne (pour les 12 derniers mois).
DEPO : Montant total des dépôts sur le compte d’épargne effectués lors de l’année précédente
(en milliers de DH).
RETR : Montant total des retraits sur les comptes d’épargne effectués lors de l’année
précédente (en milliers de DH).
Travail à faire
1. Ouvrer le fichier Banque.sav
2. Réaliser l'ACP des individus et des variables des données fournies.
3. Ces données sont-il factorisable ? Justifier votre réponse.
4. Combien de composantes doit-on conserver au minimum, afin d'avoir un taux d'inertie supérieur à
80% ?
5. Dans cette question, nous allons analyser les données sans les variables MEMP et SOLD.
a. Réaliser une ACP et comparer à la situation précédente en termes de taux d'inertie.
b. Donner une représentation graphique des individus et des variables dans le plan des deux
premières composantes.
c. Interpréter les résultats obtenus
Analyse de données avec SPSS 48
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
TP3
Analyse Factorielle des correspondances (AFC)
1 Présentation de l’AFC
L'une des fonctions de l'analyse des correspondances consiste à décrire les relations existant entre deux
variables nominales dans un tableau croisé en décrivant simultanément les relations entre les modalités
de chaque variable.
Pour chacune des variables, les distances séparant les points des modalités d'un diagramme reflètent les
relations existant entre ces modalités : plus les modalités sont similaires, plus elles sont proches les unes
des autres.
2 Les procédures de base
2.1 Pour obtenir une analyse factorielle des correspondances
Cliquez sur la commande Analyse puis glissez le pointeur de la souris sur Réduction
des dimensions puis sur Analyse des correspondances....
Nous obtenons la boîte de dialogue Analyse des correspondances
Analyse de données avec SPSS 49
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.2 Définir l’intervalle de la variable
Vous devez définir une plage pour la variable de ligne et la variable de colonne. Une valeur de
modalité se situant hors de la plage spécifiée sera ignorée dans l'analyse.
Dans la boîte de dialogue Analyse des correspondances cliquer sur le bouton : Définir
intervalles…
Spécifier les plages des valeurs de la variable Ligne et cliquer sur Mettre à jours
Même procédure pour la variable colonne
Analyse de données avec SPSS 50
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.3 Modèle d'analyse des correspondances
La boîte de dialogue Modèle vous permet de définir le nombre de dimensions, la mesure de
distance, la méthode de standardisation et la méthode de normalisation.
Dans la boîte de dialogue Analyse factorielle des correspondances cliquer sur le
bouton : Modèle …
• Dimensions de la solution : Nombre d’axes factoriels retenus. Commencer avec 2 puis
modifier selon la qualité de représentation (inertie expliquée).
• Mesure de distance : distance utilisée pour mesurer l’écart entre deux points. Choisir
Khi-deux (2).
• Méthode de normalisation : Le choix de la méthode de standardisation n’a d’influence
que sur les calculs des coordonnées des points (profils), en modifiant les échelles des
axes.
2.4 Statistiques de l'analyse des correspondances
La boîte de dialogue Statistiques vous permet de définir les résultats numériques que vous
souhaitez obtenir.
Dans la boîte de dialogue Analyse factorielle des correspondances cliquer sur le
bouton : Statistiques …
Analyse de données avec SPSS 51
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
• Tableau des correspondances : imprime le tableau de contingence.
• Caractéristiques des profils-lignes/colonnes : imprime le tableau des contributions, CO2
et QLT.
• Profils-lignes/colonnes : imprime le tableau des profils-lignes ou colonnes.
2.5 Diagrammes de l'analyse des correspondances
La boîte de dialogue Diagrammes vous permet de définir les diagrammes que vous souhaitez
créer.
Dans la boîte de dialogue Analyse factorielle des correspondances cliquer sur le
bouton : Graphiques…
• Diagrammes de dispersion : profils-lignes seuls, profils-colonnes seuls, les deux
superposés (diagramme double).
• Courbes : Trace les courbes des coordonnées des modalités des profils-lignes et/ou
colonnes sur chacun des axes.
Analyse de données avec SPSS 52
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3 Résultats d’une AFC
3.1 Tableau des correspondances
Il s’agit du tableau de contingence. Une lecture rapide permet de déceler des classes sous ou sur
représentées. On retiendra surtout l’effectif global (k) à l’intersection des deux marges actives.
3.2 Récapitulatif
• Présente le résultat de la diagonalisation de la matrice d’inertie. Le programme présente
l’ensemble des axes (il y en a inf(n − 1, p − 1)). Les axes retenus pour l’analyse sont
ceux ayant un écart-type (calculé).
• La dernière ligne (total) permet de connaître l’écart à l’indépendance 2 des deux
variables et le 2 = k*2, où k est le nombre observation :
Une signification (Sig.) inférieure à 0.05 assure de l’existence d’un lien entre les
deux variables.
• Pour chaque axe, la valeur singulière (coefficient de corrélation canonique) correspond
à la racine carrée de l’inertie.
Analyse de données avec SPSS 53
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3.3 Caractéristiques des points lignes/colonnes
• La masse correspond à la fréquence marginale de la modalité.
• Les scores dans la dimension sont les coordonnées dans les axes factoriels des
projections des points modalités.
• L’inertie représente l’inertie apportée au nuage par le point.
• Les contributions des points à l’inertie de la dimension sont les contributions classiques
alors que les contributions des dimensions à l’inertie du point correspondent aux CO2.
• Le total de ces dernières contributions représente donc les QLT.
3.4 Points de lignes ou de colonnes pour. . .
• Les graphiques points de lignes, points de colonnes ou les deux, correspondent aux
projections dans le plan factoriel des points modalités.
Analyse de données avec SPSS 54
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
4.5 Points de lignes et de colonnes
Cette représentation n’a d’intérêt que lors d’une méthode de normalisation symétrique
(biplot). Il est possible d’interpréter la proximité d’une modalité avec une modalité de
l’autre variable, si ces deux dernières se trouvent à la périphérie du nuage.
4 Analyse d’une AFC
4.1 Intérêt de l’AFC
• Il est d’abord nécessaire de déterminer s’il existe une liaison significative entre les deux
variables. On utilise pour cela le test du affiché en bas du Récapitulatif.
4.2 Nombre d’axes à retenir - Inertie expliquée
• On détermine ensuite le nombre d’axes à retenir en tenant compte de la proportion
d’inertie expliquée par les premiers axes.
• Une proportion cumulée supérieure à 70 % ou 80 % est en général suffisante.
• Rappelons que le nombre maximum d’axes est inférieur ou égal au plus petit nombre de
modalités des variables moins 1.
Analyse de données avec SPSS 55
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
5 Applications de l’AFC
Exemple1 : L'analyse des correspondances peut être utilisée pour représenter graphiquement les
relations existant entre le niveau de diplôme d’une personne de référence et le type de ménage.
Autrement dit, a t ont le même nombre d’enfant si l’on est titulaire d’un CAP ou si l’on a effectué des
études supérieurs ? Le pourcentage de personnes seules ou le pourcentage de couples avec un enfant est-
il plus important chez les bacheliers que chez les titulaires d’un CAP ? C’est à ce type de questions que
l’AFC apporte des réponses, en synthétisant l’information contenue dans le tableau de contingence.
Manipulation 1
Cette application traite les relations entre le niveau de diplôme de la personne de référence et le type de
ménage.
X1 X2 X3 X4 X5 X6 X7
Y1 444 481 245 246 232 108 128
Y2 410 732 252 204 120 84 155
Y3 189 396 401 530 321 91 107
Y4 172 169 178 258 124 81 36
Y5 46 91 90 95 51 25 12
Y6 193 184 89 91 42 32 30
Y7 319 353 237 350 198 66 45
Tableau 1 : Tableau de contingence Diplôme /Ménage
Description des variables
Variable Ménage :
• X1 : Personne seule
• X2 : Couple sans enfants
• X 3 : Couple avec un enfant
• X4 : Couple avec deux enfants
• X5 : Couple avec trois enfants ou plus
• X6 : Famille monoparentale
• X7 : Autre ménage
Variable diplôme
• Y1 : Pas de diplôme
• Y2 : CEP ou BEP
• Y3 : CAP ou BEP
• Y4 : BEPC
• Y5 : Baccalauréat technique
• Y6 : Baccalauréat général
• Y7 : Etude supérieures
Travail à effectuer
1. Saisissez le tableau de contingence dans SPSS
2. Effectuez une AFC pour ces données
3. Analysez les résultats obtenus
Analyse de données avec SPSS 56
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
TP4
Analyse Factorielle des Correspondances Multiples (AFCM)
Définition du problème et des objectifs
Effectuer une Analyse factorielle des correspondances multiples sur un ensemble de races
de chiens caractérisé par 7 variables qualitatives et identifier la variabilité entre ces races
Sources de données
• Fichier source race.sav
• Les données rassemblées portent sur 27 observations (27 Races de chiens) , 6 variables
(actives) et une supplémentaire (illustrative)
Les variables actives :
• Taille (Taille-, Taille+, Taille++)
• Poids (Poids-, Poids +, Poids ++)
• Velocite (Veloc-, Veloc +, Veloc ++)
• Intelligence (Intell-, Intell +, Intell ++)
• Affection (Affect-, Affect +)
• Agressivite (Agress-, Agress +)
La variable illustrative
• Fonction (Chasse, Compagnie, Utilite)
Elaboration du modèle
✓ Effectuer une Analyse Factorielle des correspondances multiples aux données race.sav
✓ Quelles sont les chiens qui se ressemblent ? (proximité entre les individus)
✓ Sur quelles caractéristiques sont fondées les ressemblances / dissemblances
✓ Quelles sont les relations entre les modalités.
Analyse de données avec SPSS 57
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
1 Présentation de l’AFCM
L’AFCM décrit les relations deux à deux entre p variables qualitatives à travers une représentation des
groupes d’individus correspondant aux diverses modalités.
L’AFCM est la méthode factorielle adaptée aux tableaux Individus * Variables qualitatives
Cette méthode est particulièrement bien adaptée à l’analyse des enquêtes.
2 Les procédures de base
2.1 Obtenir une analyse factorielle des correspondances multiples
A partir des menus, sélectionnez :
Analyse > Réduction des dimensions > Codage optimal
2.1 Codage optimal
Dans cette boîte de dialogue :
Sélectionnez "Toutes les variables sont nominales multiples" (selon le type des variables
disponibles)
Sélectionnez "Analyse des correspondances multiples" (Type de l'analyse souhaité)
Analyse de données avec SPSS 58
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
2.2 Analyse de correspondance multiple
Cette boîte permet de choisir :
Les variables d'analyse (actives) et la pondération des variables
Les variables supplémentaires (illustratives)
Dimensions de la solution
o Maximum P-M, avec P la somme des modalités de chaque variable d'analyse, M
nombre de variables d'analyse
La variable d'étiquetage des variables
2.3 Analyse de correspondance multiple : Discrétisation
Analyse de données avec SPSS 59
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3.4 Analyse de correspondance multiple : manquante
Cette boîte permet de définir la stratégie de traitement des valeurs manquantes
3.5 Analyse de correspondance multiple : Option
Cette boîte permet de définir des options supplémentaires de l'AFCM
Analyse de données avec SPSS 60
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3.6 Analyse de correspondance multiple : Résultats
Cette boîte permet d'obtenir les résultats suivants :
o Tableaux des coordonnées des individus, des mesures de discrimination, les corrélations
des variables d'origine ou transformées et l'historique des itérations
3.7 Analyse de correspondance multiple : Enregistrer
Cette boîte permet d’enregistrer :
o Les variables transformées dans le fichier actif ou dans un nouveau fichier de données
o Les coordonnées des individus dans le fichier actif ou dans un nouveau fichier de
données
Analyse de données avec SPSS 61
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3.8 Analyse de correspondance multiple : Digrammes d'objets
Cette boîte permet d'obtenir le diagramme des individus et le diagramme doubles (individus et
modalités des variables)
Analyse de données avec SPSS 62
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
3.9 Analyse de correspondance multiple : Digrammes de variables
Cette boîte permet d'obtenir le diagramme des modalités des variables
Analyse de données avec SPSS 63
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Résultats obtenu de l'application de l'analyse factorielle des correspondances
multiples aux données race.sav
Affiche le test le coefficient d'Alpha de Cronbach. Il est généralement utilisé pour déterminer la
cohérence de l'ensemble de questions composant un test psychologique. Le test satisfaisant dès
lors que le coefficient alpha de Cronbach atteint au moins 0,7.
Affiche les valeurs propres (colonne Inertie) et le pourcentage d'inertie (10*Total (valeur
propre). Avec 2 Dimension on obtient un pourcentage d'inertie de 51,98%
Tableau Affichant les mesures de discrimination de chaque variable
o Les variables Taille, Poids et Velocite contribuent fortement aux deux premiers axes
factoriels.
Analyse de données avec SPSS 64
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Diagramme représentant les mesures de discrimination des variables d'analyse
Analyse de données avec SPSS 65
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Digramme des modalités des variables qualitatives dans le premier plan factoriel et les
modalités de la variable supplémentaire
Analyse de données avec SPSS 66
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Diagrammes des individus dans le premier plan factoriel
Analyse de données avec SPSS 67
Pr. A. ELOUARDIGHI
Année universitaire 2021 – 2022
Digramme doubles des Individu * Variables dans le premier plan factoriel
o Un individu est au barycentre des modalités qu’il possède
o Une modalité est au barycentre des individus qui la possèdent
Analyse de données avec SPSS 68
Pr. A. ELOUARDIGHI
Vous aimerez peut-être aussi
- Les tableaux croisés dynamiques avec Excel: Pour aller plus loin dans votre utilisation d'ExcelD'EverandLes tableaux croisés dynamiques avec Excel: Pour aller plus loin dans votre utilisation d'ExcelPas encore d'évaluation
- Excel, remise à niveau et perfectionnement: Pour aller plus loin dans votre utilisation d'ExcelD'EverandExcel, remise à niveau et perfectionnement: Pour aller plus loin dans votre utilisation d'ExcelPas encore d'évaluation
- 1 - Cours SPSS PDFDocument147 pages1 - Cours SPSS PDFMohamed Bensaid81% (31)
- Chapitre 3 L'imputation Rationelle Des Charges FixesDocument5 pagesChapitre 3 L'imputation Rationelle Des Charges Fixesghassen Ben hlimaPas encore d'évaluation
- Surveillance Des Machines Par Analyse Des VibrationsDocument337 pagesSurveillance Des Machines Par Analyse Des VibrationsIdren9792% (12)
- Analyse Des DonnéesDocument183 pagesAnalyse Des DonnéesNOUHA DACHRAOUIPas encore d'évaluation
- Rapport SPSSDocument44 pagesRapport SPSSBassma El GhalbzouriPas encore d'évaluation
- L'analyse des données de sondage avec SPSS: Un guide d'introductionD'EverandL'analyse des données de sondage avec SPSS: Un guide d'introductionPas encore d'évaluation
- SpssDocument47 pagesSpssMousTarham AminePas encore d'évaluation
- Atelier Spss Réussir Vos Statistiques Sur SPSS DR Tarek BarhoumiDocument61 pagesAtelier Spss Réussir Vos Statistiques Sur SPSS DR Tarek BarhoumiTarek Barhoumi100% (1)
- Formation SPSSDocument37 pagesFormation SPSSAbdelatif HrPas encore d'évaluation
- Stat SPSSDocument8 pagesStat SPSSMAAATIPas encore d'évaluation
- Cours - DOUMI SPSS 2013 2014 PDFDocument94 pagesCours - DOUMI SPSS 2013 2014 PDFTsuhellPas encore d'évaluation
- PPT2 Introduction Traitement Donnees SPSS PNIN NigerDocument26 pagesPPT2 Introduction Traitement Donnees SPSS PNIN NigerJihan SahimPas encore d'évaluation
- Initiation Au Logiciel SPSS 18Document35 pagesInitiation Au Logiciel SPSS 18Méd Senhaji100% (1)
- Connaissance de La Mecanique Des Sols BTP-TSCTDocument43 pagesConnaissance de La Mecanique Des Sols BTP-TSCTprincessesara100% (3)
- IBM SPSS Statistics Brief GuideDocument182 pagesIBM SPSS Statistics Brief GuideFaiçal YahiaPas encore d'évaluation
- 01 - A La Découverte de SPSSDocument22 pages01 - A La Découverte de SPSSWahid Kiade100% (1)
- Séance 01Document20 pagesSéance 01ayoubhaouasPas encore d'évaluation
- Note TP - Informatique 5Document27 pagesNote TP - Informatique 5NoureddineLahouelPas encore d'évaluation
- Cours SPSSDocument14 pagesCours SPSSZakaria Kabore0% (1)
- SPSS 1Document11 pagesSPSS 1AhlemPas encore d'évaluation
- Informatique - Présentation de Logiciel D'analyse de Données StatistiquesDocument4 pagesInformatique - Présentation de Logiciel D'analyse de Données StatistiquesSerigne Saliou DioufPas encore d'évaluation
- Cours 1Document3 pagesCours 1balomiPas encore d'évaluation
- Guide SPSS Version 2010Document72 pagesGuide SPSS Version 2010Mohamed YazidPas encore d'évaluation
- Cours Spss 2012Document2 pagesCours Spss 2012Khalid MalinPas encore d'évaluation
- Cours SPSS - Docx - CopieDocument52 pagesCours SPSS - Docx - CopieMangala FistonPas encore d'évaluation
- Statistica 2004 - Version6Document19 pagesStatistica 2004 - Version6hindPas encore d'évaluation
- SpssDocument69 pagesSpssTaha KhsibPas encore d'évaluation
- Atelier 1Document12 pagesAtelier 1KHAOULA ESSAKHIPas encore d'évaluation
- COURS Et TD1 SPSSDocument3 pagesCOURS Et TD1 SPSSShop InPas encore d'évaluation
- SPSS Statistic Cours (Analyse Variée Et Bivariee)Document35 pagesSPSS Statistic Cours (Analyse Variée Et Bivariee)karoke musicPas encore d'évaluation
- Chapitre 1Document36 pagesChapitre 1GEEKGHAZIPas encore d'évaluation
- Chap1 IntroductionDocument18 pagesChap1 IntroductionAsma Sallemi100% (1)
- Chap1 IntroductionDocument18 pagesChap1 IntroductionHoussem MezliniPas encore d'évaluation
- Resume de SpssDocument6 pagesResume de SpssFadiPas encore d'évaluation
- Epi InfoDocument4 pagesEpi InforostandtchangouePas encore d'évaluation
- Statistique Computationnelle Avec SpssDocument62 pagesStatistique Computationnelle Avec SpssLOKOSSOU DURANDPas encore d'évaluation
- Travail À RendreDocument19 pagesTravail À RendreYounes El hachmiPas encore d'évaluation
- Acfrogdcs1m Iaxjxnv-Akufrxiwmtgemfp9d6 D5hqyydoq-Eoruthoemacy60lp3hdebamigh99y70tb4o0 Kqd00xrxyycl9v6gk-Dyqqlyqgfgm2y6nhb0ozqqnavmcvwiqkkg6jt38qqhvDocument21 pagesAcfrogdcs1m Iaxjxnv-Akufrxiwmtgemfp9d6 D5hqyydoq-Eoruthoemacy60lp3hdebamigh99y70tb4o0 Kqd00xrxyycl9v6gk-Dyqqlyqgfgm2y6nhb0ozqqnavmcvwiqkkg6jt38qqhvmazen tombaryPas encore d'évaluation
- L S (SPSS) FSRDocument97 pagesL S (SPSS) FSRKhadijetou ThiamPas encore d'évaluation
- Cahier SpssDocument44 pagesCahier SpssMedo ZnPas encore d'évaluation
- Intro SpssDocument4 pagesIntro SpssHarrys Ignace RamarolahyPas encore d'évaluation
- TP OADM Décision MulticritèresDocument19 pagesTP OADM Décision MulticritèresAyoub KARROUM100% (2)
- Cours Informatique SPSSDocument2 pagesCours Informatique SPSSOumaima ChahbounePas encore d'évaluation
- Initiation Au Logiciel SPSS 18Document35 pagesInitiation Au Logiciel SPSS 18Tarik LamzouriPas encore d'évaluation
- TP. SPSS + CorrigéDocument20 pagesTP. SPSS + CorrigéTechno Info100% (1)
- Cours Analyse Des Donnee Avec SPSSDocument47 pagesCours Analyse Des Donnee Avec SPSSrey.payne12Pas encore d'évaluation
- Support SpssDocument41 pagesSupport SpssAmirdine ToyibouPas encore d'évaluation
- Econometrie Des Donnees de Panel PDFDocument46 pagesEconometrie Des Donnees de Panel PDFKhaled AmriPas encore d'évaluation
- 1ere Serie de TP SPSSDocument32 pages1ere Serie de TP SPSSmounamajri80Pas encore d'évaluation
- CartONG Tutorial KoboToolBox DataAnalyser FRDocument14 pagesCartONG Tutorial KoboToolBox DataAnalyser FRYoussoupha SarrPas encore d'évaluation
- Featuredengineering Ebook - FINAL FRDocument16 pagesFeaturedengineering Ebook - FINAL FRZAKARIAPas encore d'évaluation
- TP #1. Analyse Des Données Avec Le Logiciel SPSSDocument10 pagesTP #1. Analyse Des Données Avec Le Logiciel SPSSYasmine NedjamPas encore d'évaluation
- Codification VariablesDocument8 pagesCodification VariablesfifoliaPas encore d'évaluation
- Traitement Des Données Avec Microsoft EXCEL 2016Document9 pagesTraitement Des Données Avec Microsoft EXCEL 2016MunezeroPas encore d'évaluation
- Fiche1 Applications 2021 SPSSDocument6 pagesFiche1 Applications 2021 SPSSnamePas encore d'évaluation
- JASP Partie 1Document16 pagesJASP Partie 1mohamedazemri1Pas encore d'évaluation
- Comment Définir Une Plage de Données Pour Utiliser Fonctions de Filtres Et de TrisDocument10 pagesComment Définir Une Plage de Données Pour Utiliser Fonctions de Filtres Et de TrisPiloupilouPas encore d'évaluation
- Herve Aide Memoire QueDocument126 pagesHerve Aide Memoire QueRachiidPas encore d'évaluation
- Ses Pegase PDFDocument22 pagesSes Pegase PDFAme NiiPas encore d'évaluation
- Bien débuter avec Keynote: Vos présentations avec le MacD'EverandBien débuter avec Keynote: Vos présentations avec le MacPas encore d'évaluation
- Estimation IncertitudesDocument35 pagesEstimation IncertitudesBacem Chaabane100% (1)
- TrigonometrieDocument3 pagesTrigonometrieSafaePas encore d'évaluation
- Cihm 92121Document261 pagesCihm 92121AlexandreSidantPas encore d'évaluation
- Qu'est Donc Le SpinDocument1 pageQu'est Donc Le SpinQPas encore d'évaluation
- Bac Blanc (Lycée Pilote El Kef) - Mathématiques - Bac Math (2007-2008) 2Document3 pagesBac Blanc (Lycée Pilote El Kef) - Mathématiques - Bac Math (2007-2008) 2Seif Souid80% (5)
- CryptographieDocument42 pagesCryptographieYoussef AlsabekPas encore d'évaluation
- CiscoDocument7 pagesCiscoma llekPas encore d'évaluation
- TD DHCPDocument2 pagesTD DHCPomrani.ahmed2002Pas encore d'évaluation
- Cours Vprocess PDFDocument47 pagesCours Vprocess PDFMohamed LaliouiPas encore d'évaluation
- Audrey Roig-L'Adjectivité Approches Descriptives de La Linguistique Adjectivale-JerichoDocument518 pagesAudrey Roig-L'Adjectivité Approches Descriptives de La Linguistique Adjectivale-JerichoKi WiPas encore d'évaluation
- BelghiniDocument14 pagesBelghiniElmehdi BenhmidiPas encore d'évaluation
- Devoir de Synthèse N°1 2019 2020 (MR Foued Bahlous)Document5 pagesDevoir de Synthèse N°1 2019 2020 (MR Foued Bahlous)Abdelkader HamdaPas encore d'évaluation
- PythagoreDocument13 pagesPythagorelemoga75yahoo.frPas encore d'évaluation
- 07 Decouverte Utilisation ElasticsearchDocument33 pages07 Decouverte Utilisation ElasticsearchChristian BibouePas encore d'évaluation
- TD1 Algorithme - 1 PDFDocument1 pageTD1 Algorithme - 1 PDFmaherhamdiPas encore d'évaluation
- Chapitre 5 SuiteDocument5 pagesChapitre 5 Suitelilia RabhiPas encore d'évaluation
- Panneaux Avec Portées-Web-PapDocument24 pagesPanneaux Avec Portées-Web-PapchouaibPas encore d'évaluation
- Arduino - Use A Shift Register (74HC595) and A Transistor Array (ULN2803) Erwan's BlogDocument3 pagesArduino - Use A Shift Register (74HC595) and A Transistor Array (ULN2803) Erwan's BlogapofviewPas encore d'évaluation
- Support Cours 2018-2019-STUDENT - CopieDocument96 pagesSupport Cours 2018-2019-STUDENT - Copierémi ParatPas encore d'évaluation
- MAT2023 Chapitre0Document10 pagesMAT2023 Chapitre0KamPas encore d'évaluation
- AnouarDocument6 pagesAnouarAnouar Mca DebbabiPas encore d'évaluation
- Cours VB - Net 2023 - 100537Document96 pagesCours VB - Net 2023 - 100537Paulin KABEYAPas encore d'évaluation
- Langage Sas EnsaeDocument124 pagesLangage Sas EnsaeMohamedPas encore d'évaluation
- Session 1 2013 2014Document8 pagesSession 1 2013 2014Yc YacinePas encore d'évaluation
- Integral 18 Complet PDFDocument28 pagesIntegral 18 Complet PDFBouazizi HechmiPas encore d'évaluation
- Calcul D'un Volant D'inertieDocument19 pagesCalcul D'un Volant D'inertieNathan KibilaPas encore d'évaluation
- TP Access 2017Document5 pagesTP Access 2017Amine MénPas encore d'évaluation