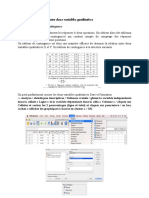
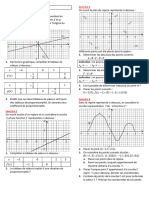
Vous aimerez peut-être aussi
- UntitledDocument35 pagesUntitledYasser El Adrazi IIPas encore d'évaluation
- CorrélationDocument13 pagesCorrélationLebossePas encore d'évaluation
- PR Mourad TOUNSI Chapitre 7 La Regression Stat'App ENCG OCT 2023Document19 pagesPR Mourad TOUNSI Chapitre 7 La Regression Stat'App ENCG OCT 2023فاطمة الزهراء حمانيPas encore d'évaluation
- Chapitre 3Document60 pagesChapitre 3GEEKGHAZIPas encore d'évaluation
- Fiche 4 Statistics Bivariées 2023Document7 pagesFiche 4 Statistics Bivariées 2023Nguyễn Mai Phước HậuPas encore d'évaluation
- Chapitre Ii 17 02 2020Document5 pagesChapitre Ii 17 02 2020Ezekiel KouassiPas encore d'évaluation
- Section 1 Corrélation Et Régression - Copie (2) - CopieDocument4 pagesSection 1 Corrélation Et Régression - Copie (2) - CopieALLAL ZAHIRPas encore d'évaluation
- Biostat4Document61 pagesBiostat4yacine koubaPas encore d'évaluation
- Cours 7Document66 pagesCours 7gizemPas encore d'évaluation
- Psy1004 12Document12 pagesPsy1004 12Mustapha ImadPas encore d'évaluation
- Chapitre 2 Theorie de La CorrelationDocument18 pagesChapitre 2 Theorie de La Correlationhoumeid barePas encore d'évaluation
- Relation Entre Deux Variables QualitativesDocument10 pagesRelation Entre Deux Variables QualitativesDantePas encore d'évaluation
- Chapitre I RLS .Document4 pagesChapitre I RLS .ABDELOUAHAB ETTAIKPas encore d'évaluation
- Stat ch4Document8 pagesStat ch4chbahimexpPas encore d'évaluation
- Chapitre 5-StatistiqueDocument8 pagesChapitre 5-Statistiqueoussema waliPas encore d'évaluation
- TD 3Document6 pagesTD 3Jingjing ShaPas encore d'évaluation
- Séance 8: La Relation Entre Deux Caractères: Corrélation Et Relation LinéaireDocument5 pagesSéance 8: La Relation Entre Deux Caractères: Corrélation Et Relation LinéaireLéa de FrémontPas encore d'évaluation
- ASDchap1 LicDocument13 pagesASDchap1 LicHafsa zianiPas encore d'évaluation
- Chapitre 3Document8 pagesChapitre 3vu huyenPas encore d'évaluation
- Analyse DonneesDocument39 pagesAnalyse DonneesSana Yassine100% (1)
- Introduction Econometrie IIDocument9 pagesIntroduction Econometrie IIClark OberaPas encore d'évaluation
- Regression MultipleDocument8 pagesRegression MultipleMahmoudAchritChefchaouenPas encore d'évaluation
- Le Coefficient de Correlation PDFDocument2 pagesLe Coefficient de Correlation PDFAndriamitombohanitra FenolianaPas encore d'évaluation
- Questions SubjectivesDocument8 pagesQuestions SubjectivesScribdTranslationsPas encore d'évaluation
- Document From Jaber KhlieDocument3 pagesDocument From Jaber Khlieoussama khatrouniPas encore d'évaluation
- Document From Jaber KhlieDocument3 pagesDocument From Jaber Khlieoussama khatrouniPas encore d'évaluation
- Chapitre Régression - Corrélation - CausalitéDocument88 pagesChapitre Régression - Corrélation - CausalitéTarik LamzouriPas encore d'évaluation
- Vecm FinDocument25 pagesVecm FinEl Zakaria100% (1)
- Module Econometrie Chap1 2 2022Document18 pagesModule Econometrie Chap1 2 2022Abdou Dodo Bohari100% (1)
- Analyse Des DonnéesDocument12 pagesAnalyse Des DonnéesHoussine MaatallahPas encore d'évaluation
- Régression MultipleDocument28 pagesRégression MultipleΙμάνε ΙμάνεPas encore d'évaluation
- Régression Linéaire SimpleDocument9 pagesRégression Linéaire SimpleIsmail AslPas encore d'évaluation
- Analyse Statistique Des Résultats Scolaires Chez Des EtudiantsDocument16 pagesAnalyse Statistique Des Résultats Scolaires Chez Des EtudiantsImane AlouiPas encore d'évaluation
- Le Data MiningDocument5 pagesLe Data MiningizmPas encore d'évaluation
- Correlation 1Document30 pagesCorrelation 1jamesPas encore d'évaluation
- Analyse BivariéDocument31 pagesAnalyse BivariéHind DekkakPas encore d'évaluation
- Regression Multiple DocumentDocument7 pagesRegression Multiple DocumentMohamed Amine EL MHASSANIPas encore d'évaluation
- CCM1Didactique. KefDocument79 pagesCCM1Didactique. KefNoomen GalmamiPas encore d'évaluation
- CH 9- droite de régression.docxDocument11 pagesCH 9- droite de régression.docxboudour.zitounPas encore d'évaluation
- Régression Linéaire Simple Et MultipleDocument13 pagesRégression Linéaire Simple Et MultipleOlivier TaonsaPas encore d'évaluation
- Colloque 20 Ansjuin 93Document18 pagesColloque 20 Ansjuin 93Danny RodriguezPas encore d'évaluation
- Serie2 CorrigeDocument12 pagesSerie2 CorrigeAhmed MessabihPas encore d'évaluation
- 3EC Thème 14Document21 pages3EC Thème 14Mellah ImadPas encore d'évaluation
- Chap 2Document14 pagesChap 2Alassane konePas encore d'évaluation
- Lissage ExponentielDocument6 pagesLissage ExponentielBrahim BoualiPas encore d'évaluation
- Cefod Analyse de DonnesDocument30 pagesCefod Analyse de DonnesStephane Phanotron MbaïammadjiPas encore d'évaluation
- CORRÉLATION LINÉAIRE (Une Variable)Document14 pagesCORRÉLATION LINÉAIRE (Une Variable)himPas encore d'évaluation
- Cours 4Document4 pagesCours 4Rachid beddaaPas encore d'évaluation
- Manuscrit StatDocument21 pagesManuscrit Statbouthainaamara6Pas encore d'évaluation
- Cours Seance 2Document14 pagesCours Seance 2François BélorgeyPas encore d'évaluation
- Chapitre 9. Analyse de La Variance: "Variance Totale Variance Intra + Variance Inter"Document36 pagesChapitre 9. Analyse de La Variance: "Variance Totale Variance Intra + Variance Inter"Zineb HatiniPas encore d'évaluation
- 2 Corrélation RegressionDocument18 pages2 Corrélation RegressionmadPas encore d'évaluation
- Cour DADDocument49 pagesCour DADRaouf BoushabaPas encore d'évaluation
- Econometrie IntroDocument10 pagesEconometrie IntrodidjwPas encore d'évaluation
- S3 Méthodes Quantitatives de GestionDocument27 pagesS3 Méthodes Quantitatives de GestionsidwhnPas encore d'évaluation
- test spycologieDocument9 pagestest spycologiefofanamgabonPas encore d'évaluation
- Méthode Des Moindres Carrés PDFDocument6 pagesMéthode Des Moindres Carrés PDFRoberto100% (1)
- Sujet TravailDocument2 pagesSujet TravaillotfiPas encore d'évaluation
- Poutre Hyperstatique Encastrée Et Uniformément Chargée: Iset KelibiaDocument7 pagesPoutre Hyperstatique Encastrée Et Uniformément Chargée: Iset KelibiaRayen ElloumiPas encore d'évaluation
- Referentiel RSE en LogistiqueDocument228 pagesReferentiel RSE en LogistiqueMarshall WilliamsPas encore d'évaluation
- Fiche D'inventaire ATEX: Informations Générales Appontement EnvironnementDocument2 pagesFiche D'inventaire ATEX: Informations Générales Appontement EnvironnementMohammed DjelailiPas encore d'évaluation
- Chap 2 Les-Climats-Et-Courants-A-La-Surface-De-La-TerreDocument16 pagesChap 2 Les-Climats-Et-Courants-A-La-Surface-De-La-Terreyanina.kolodyazhnayaPas encore d'évaluation
- Routiers: Prévention D'effondrement Liés Souterraines Solution Renforcement RemblaisDocument12 pagesRoutiers: Prévention D'effondrement Liés Souterraines Solution Renforcement RemblaisPaul Zephyrin AwonaPas encore d'évaluation
- Comment La Sociologie Explique-T-Elle Les Comportements Criminels?Document2 pagesComment La Sociologie Explique-T-Elle Les Comportements Criminels?Nicolas Nolivos100% (1)
- Livre MMCDocument172 pagesLivre MMCFRANCKY JORDAN NJOCKE NDIKIPas encore d'évaluation
- 1 - Contrôle Et ManagementDocument23 pages1 - Contrôle Et ManagementlolaPas encore d'évaluation
- Devoir SondeDocument6 pagesDevoir Sondewassime FassiPas encore d'évaluation
- CM1 L9 Ranger Des Fractions Simples 2020Document3 pagesCM1 L9 Ranger Des Fractions Simples 2020koss koss100% (1)
- Les Interjections Et Les Onomatopées - Quelle Est La Richesse Apportée Par Leur Utilisation Dans La Bande DessinéeDocument18 pagesLes Interjections Et Les Onomatopées - Quelle Est La Richesse Apportée Par Leur Utilisation Dans La Bande DessinéePinar SezerPas encore d'évaluation
- Epistémologie Des Sciences HumainesDocument2 pagesEpistémologie Des Sciences HumainesmeldimanchePas encore d'évaluation
- Formations Qshe PDFDocument4 pagesFormations Qshe PDFfieti zlatanPas encore d'évaluation
- Devoir de Contrôle N°1 - Algorithmique - Bac Informatique (2012-2013) Mme Mediha Sfar PDFDocument2 pagesDevoir de Contrôle N°1 - Algorithmique - Bac Informatique (2012-2013) Mme Mediha Sfar PDFAyoub AbidPas encore d'évaluation
- Devoir de Contrôle N°3 - Math - 3ème Math (2017-2018) MR Meddeb TarekDocument2 pagesDevoir de Contrôle N°3 - Math - 3ème Math (2017-2018) MR Meddeb TarekChaker Ben MahmoudPas encore d'évaluation
- Les Éléments Chimiques Dans L'univers - 1ère - Cours Enseignement Scientifique - KartableDocument2 pagesLes Éléments Chimiques Dans L'univers - 1ère - Cours Enseignement Scientifique - KartableHello HelloPas encore d'évaluation
- Kitchen Xtone 2023Document89 pagesKitchen Xtone 2023Murat KanberoğluPas encore d'évaluation
- Beer-Lambert Smartphone Cuso4: 1 Utilisation de 2 Smartphones Pour Analyser La Composition D'Une So-Lution - MpsDocument7 pagesBeer-Lambert Smartphone Cuso4: 1 Utilisation de 2 Smartphones Pour Analyser La Composition D'Une So-Lution - MpsJean-Serein MbendePas encore d'évaluation
- Dépannage Des Différentes Parties Des Machines ÉlectriquesDocument18 pagesDépannage Des Différentes Parties Des Machines ÉlectriquesNtui Junior71% (7)
- Vibration SystemsDocument24 pagesVibration SystemsaliPas encore d'évaluation
- Convection Forcee Dans Des Surfaces PlanDocument8 pagesConvection Forcee Dans Des Surfaces Planim enePas encore d'évaluation
- AP FonctionsDocument2 pagesAP FonctionsMarlèneAndrieuPas encore d'évaluation
- Projet de Thèse - Mamadou COULIBALYDocument5 pagesProjet de Thèse - Mamadou COULIBALYMamadou CoulibalyPas encore d'évaluation
- Activite 2 5e Semaine 1Document2 pagesActivite 2 5e Semaine 1Aboubacar KountaPas encore d'évaluation
- Méthode de Résolution de Problèmes Et Outils AssociésDocument17 pagesMéthode de Résolution de Problèmes Et Outils AssociésbinlinPas encore d'évaluation
- Compte Rendu FonderieDocument9 pagesCompte Rendu FonderiedmedmahdiPas encore d'évaluation
- SVT 3ème - L10 - La Dégradation Du SolDocument7 pagesSVT 3ème - L10 - La Dégradation Du SolYVESPas encore d'évaluation
- HTTP WWW - Electrostimulateurs-Manuels - FR Fichiers Manuels Globus Elite-S2 Elite-S2-Genesy-S2-Duo-TensDocument40 pagesHTTP WWW - Electrostimulateurs-Manuels - FR Fichiers Manuels Globus Elite-S2 Elite-S2-Genesy-S2-Duo-TensMEDARBEL AbdelkrimPas encore d'évaluation
- 2014 MAPSI Cours10Document54 pages2014 MAPSI Cours10Zack AOZPas encore d'évaluation