Vous aimerez peut-être aussi
- Spring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplateD'EverandSpring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplatePas encore d'évaluation
- 06 Comprendre Utiliser Packetbeat Stack ElkDocument18 pages06 Comprendre Utiliser Packetbeat Stack ElkChristian BibouePas encore d'évaluation
- 02 - Installation-Configuration-ElkDocument9 pages02 - Installation-Configuration-ElkChristian BibouePas encore d'évaluation
- 03 - Utilisation-Stack-Elk-Logs-ApacheDocument33 pages03 - Utilisation-Stack-Elk-Logs-ApacheChristian BibouePas encore d'évaluation
- Ma ArchDocument30 pagesMa ArchBabacar Sakho100% (1)
- Sujet - TP - 4 Kibana - Tierno Oumar DIALLO Bach3 Cyber EcetechDocument19 pagesSujet - TP - 4 Kibana - Tierno Oumar DIALLO Bach3 Cyber EcetechAnonyme10Pas encore d'évaluation
- Serveur Web LINUX UbuntuDocument22 pagesServeur Web LINUX UbuntuabdelkrimoPas encore d'évaluation
- TP Réseaux 4 - Installation Et Configuration D'un Serveur Web ApacheDocument6 pagesTP Réseaux 4 - Installation Et Configuration D'un Serveur Web ApacheRigelPas encore d'évaluation
- Chapitre 9 - Commandes UtilesDocument31 pagesChapitre 9 - Commandes UtilesHamid O.A.Pas encore d'évaluation
- ITC314 - TP3 - Configuration de ServeursDocument3 pagesITC314 - TP3 - Configuration de Serveursamine.besrour5214Pas encore d'évaluation
- Redondance 2Document8 pagesRedondance 2yaya konatePas encore d'évaluation
- HTTP MysqlDocument66 pagesHTTP MysqlAwa SALLPas encore d'évaluation
- Mettre en Place Un Cluster de Base de Données Avec MariaDBDocument15 pagesMettre en Place Un Cluster de Base de Données Avec MariaDBMarouani AmorPas encore d'évaluation
- Installation Et Paramétrage de GLPI Et OCS Inventory Sous DebianDocument25 pagesInstallation Et Paramétrage de GLPI Et OCS Inventory Sous DebianS'bas ArnzPas encore d'évaluation
- Maarch RM - Procédure D'installation v2Document4 pagesMaarch RM - Procédure D'installation v2ThierryPas encore d'évaluation
- Installation Et Configuration D'oracle Sous LinuxDocument13 pagesInstallation Et Configuration D'oracle Sous Linuxanolui100% (1)
- Apache2 Sous Linux - Lasfar SalimDocument23 pagesApache2 Sous Linux - Lasfar SalimSalim LASFARPas encore d'évaluation
- Semaine6 NormalDocument14 pagesSemaine6 NormalSidi AliPas encore d'évaluation
- tp1 IRSDocument7 pagestp1 IRSZohra CHANNOUF100% (1)
- Glpi FinalDocument15 pagesGlpi Finalapi-358853016Pas encore d'évaluation
- Protection Application WebDocument16 pagesProtection Application WebtestPas encore d'évaluation
- Zimbra Samba Openvpn Manuel de DeploiementDocument20 pagesZimbra Samba Openvpn Manuel de DeploiementYv PegPas encore d'évaluation
- Virtualisation TP Xen 1Document20 pagesVirtualisation TP Xen 1Dalel Bene100% (1)
- Oracle InstalDocument6 pagesOracle InstalPapissKPas encore d'évaluation
- Apprendre MysqlDocument103 pagesApprendre MysqlNatheoPas encore d'évaluation
- DEV-02 - Log FilesDocument23 pagesDEV-02 - Log Files1m0zvrtPas encore d'évaluation
- Administration Linux Module 8 Installation ApplicationsDocument31 pagesAdministration Linux Module 8 Installation ApplicationsNoureddine EnnahnahiPas encore d'évaluation
- 1 - Installation Manuelle de Nagios Centreon - DebianDocument39 pages1 - Installation Manuelle de Nagios Centreon - DebianAndrew Fleming100% (2)
- IMS InstallDocument6 pagesIMS InstallraissmedPas encore d'évaluation
- ConfigapacheDocument25 pagesConfigapacheSalissou MoutariPas encore d'évaluation
- IptablesDocument9 pagesIptablesGhofrane FerchichiPas encore d'évaluation
- Installation de Glpi Et Ocs Inventory Sous DebianDocument14 pagesInstallation de Glpi Et Ocs Inventory Sous Debianapi-247116054Pas encore d'évaluation
- Grey Minimalist Business Project PresentationDocument25 pagesGrey Minimalist Business Project PresentationNada EllehlaissiPas encore d'évaluation
- 1 TP1 installationOpenERPDocument4 pages1 TP1 installationOpenERPAdiatta DiedhiouPas encore d'évaluation
- INSTALL-Oreon-1 3 3Document47 pagesINSTALL-Oreon-1 3 3El Khaledi NadaPas encore d'évaluation
- Générateur Alfresco Docker InstallerDocument11 pagesGénérateur Alfresco Docker InstallergnabroPas encore d'évaluation
- 06 - Backends-Workspaces-TerraformDocument25 pages06 - Backends-Workspaces-TerraformChristian BibouePas encore d'évaluation
- Rsyslog PhpsyslogngDocument11 pagesRsyslog PhpsyslogngBlin NkoukaPas encore d'évaluation
- Mise en Place Serveur WebDocument29 pagesMise en Place Serveur WebUriel OuakePas encore d'évaluation
- Compte Rendu Glpi - OcsDocument15 pagesCompte Rendu Glpi - Ocsapi-346005085Pas encore d'évaluation
- Cours VSFTPDDocument10 pagesCours VSFTPDitachitaha42Pas encore d'évaluation
- TP3 Cacti For SNMP Devices Monitoring BonDocument30 pagesTP3 Cacti For SNMP Devices Monitoring BonGedeon EtongPas encore d'évaluation
- Linux Sri2 Partie1Document67 pagesLinux Sri2 Partie1Abdedaim BabakhouyaPas encore d'évaluation
- Introduction À Laravel: by Marie-Adelphe AGUESSYDocument13 pagesIntroduction À Laravel: by Marie-Adelphe AGUESSYedhfreezPas encore d'évaluation
- ArcGis Pro TutosDocument61 pagesArcGis Pro TutosmoinahousnaPas encore d'évaluation
- NGN openIMSDocument8 pagesNGN openIMSSuley Paterson100% (1)
- Securite PHP Pour Les Tout PetitsDocument17 pagesSecurite PHP Pour Les Tout PetitsdurvelPas encore d'évaluation
- OpenNMS Installation Guide DebianDocument11 pagesOpenNMS Installation Guide Debiannfplacide100% (1)
- EasyPhp Install Config DecouverteDocument7 pagesEasyPhp Install Config DecouverteOneTXxLPas encore d'évaluation
- 08 - Utilisation-Modules-TerraformDocument17 pages08 - Utilisation-Modules-TerraformChristian BibouePas encore d'évaluation
- Introduction Freertos 2Document28 pagesIntroduction Freertos 2jtohnPas encore d'évaluation
- Partie8-Serveur Web ApacheDocument16 pagesPartie8-Serveur Web ApacheAyman TijaniPas encore d'évaluation
- Bien Debuter Projet TalendDocument23 pagesBien Debuter Projet TalendyveseonePas encore d'évaluation
- Intro Code IgniterDocument31 pagesIntro Code IgniterJaona Alimana RakotoarisonPas encore d'évaluation
- ApacheDocument11 pagesApachefehriPas encore d'évaluation
- Mon Utilisation de Sublime Text 3: À-Propos..Document8 pagesMon Utilisation de Sublime Text 3: À-Propos..Atoumane LayePas encore d'évaluation
- Tutoriel Sympa UbuntuDocument18 pagesTutoriel Sympa UbuntuVincent GatignolPas encore d'évaluation
- Resumer Colle TPDocument4 pagesResumer Colle TPrizlane korichiPas encore d'évaluation
- Administration Linux Avancée - SEQ5Document20 pagesAdministration Linux Avancée - SEQ5tall mouhamedPas encore d'évaluation
- 37 Inserer Une Zone de Texte 2 PagesDocument2 pages37 Inserer Une Zone de Texte 2 PagesChristian BibouePas encore d'évaluation
- Guide Complet Gestion Logs DevopsDocument16 pagesGuide Complet Gestion Logs Devopschristophe.forestier01Pas encore d'évaluation
- 18 - Goroutines-GolangDocument10 pages18 - Goroutines-GolangChristian BibouePas encore d'évaluation
- 14 - Interfaces-GolangDocument6 pages14 - Interfaces-GolangChristian BibouePas encore d'évaluation
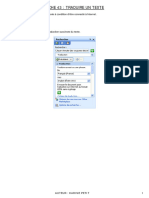
- 43 Traduire Un Texte 1 PageDocument1 page43 Traduire Un Texte 1 PageChristian BibouePas encore d'évaluation
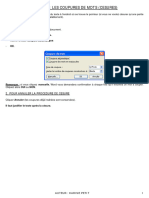
- 42 Coupure Des Mots 1 PageDocument1 page42 Coupure Des Mots 1 PageChristian BibouePas encore d'évaluation
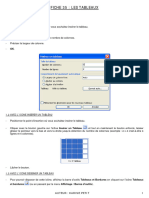
- 35 Tableaux 8 PagesDocument8 pages35 Tableaux 8 PagesChristian BibouePas encore d'évaluation
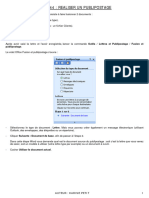
- 44 Publipostage 10 PagesDocument10 pages44 Publipostage 10 PagesChristian BibouePas encore d'évaluation
- La Programmation Orientée Objet Dans Le Langage de Programmation GODocument7 pagesLa Programmation Orientée Objet Dans Le Langage de Programmation GOFrederic SaainePas encore d'évaluation
- 08 - Tableaux-GolangDocument13 pages08 - Tableaux-GolangChristian BibouePas encore d'évaluation
- 09 - Tp-Jeu-Du-Morpions-GolangDocument9 pages09 - Tp-Jeu-Du-Morpions-GolangChristian BibouePas encore d'évaluation
- Gestion Audio SDLDocument29 pagesGestion Audio SDLnathanaelPas encore d'évaluation
- 10 - Pointeurs-GolangDocument9 pages10 - Pointeurs-GolangChristian BibouePas encore d'évaluation
- 04 - Conditions-GolangDocument11 pages04 - Conditions-GolangChristian BibouePas encore d'évaluation
- Variables Golang PDFDocument15 pagesVariables Golang PDFsouad sadkiPas encore d'évaluation
- Fonction Golang PDFDocument7 pagesFonction Golang PDFsouad sadkiPas encore d'évaluation
- Micro Pratique - Février-Mars 2024Document84 pagesMicro Pratique - Février-Mars 2024James HowlettPas encore d'évaluation
- Ench Pdf-KlyDocument52 pagesEnch Pdf-KlyChristian BibouePas encore d'évaluation
- 2-Concepts Et Principes Fondamentaux de La SIDocument17 pages2-Concepts Et Principes Fondamentaux de La SIChristian BibouePas encore d'évaluation
- 00 - Cours-Introduction-Sdl-2Document3 pages00 - Cours-Introduction-Sdl-2Christian BibouePas encore d'évaluation
- 00 - Cours-Apprendre-Langage-Programmation-GoDocument6 pages00 - Cours-Apprendre-Langage-Programmation-GoChristian BibouePas encore d'évaluation
- Eyrolles Chatgpt Le Guide Du DebutantDocument286 pagesEyrolles Chatgpt Le Guide Du DebutantChristian BibouePas encore d'évaluation
- 01 - Telechargement-Compilation-Projet-SdlDocument10 pages01 - Telechargement-Compilation-Projet-SdlChristian BibouePas encore d'évaluation
- Git Cmds BranchsDocument4 pagesGit Cmds BranchsChristian BibouePas encore d'évaluation
- Etude Et Mise en Place Dune Solution de Monitoring Open Source SlidesDocument52 pagesEtude Et Mise en Place Dune Solution de Monitoring Open Source SlidesChristian BibouePas encore d'évaluation
- Git Cmds BaseDocument7 pagesGit Cmds BaseChristian BibouePas encore d'évaluation
- Profession Photographe IndépendantDocument383 pagesProfession Photographe IndépendantChristian BibouePas encore d'évaluation
- Ench Pdf-KlyDocument56 pagesEnch Pdf-KlyChristian BibouePas encore d'évaluation
- TP 2 Admin Reseaux-1Document10 pagesTP 2 Admin Reseaux-1Weslati AminPas encore d'évaluation
- L'Overdose: FentanylDocument48 pagesL'Overdose: FentanylLegrandPas encore d'évaluation
- Manuel-BD-4eme-si (1) (001-270)Document270 pagesManuel-BD-4eme-si (1) (001-270)attar ablaPas encore d'évaluation
- Amrane SamiaDocument113 pagesAmrane SamiaLokmane ElhakimPas encore d'évaluation
- ConcoursM2I 14-15Document5 pagesConcoursM2I 14-15FreddyGuenengafoPas encore d'évaluation
- Les Defenses MateriellesDocument11 pagesLes Defenses MateriellesJean Louis KacouPas encore d'évaluation
- Nfs (Network File System) : 1 Abdellah Ezzati FST SettatDocument23 pagesNfs (Network File System) : 1 Abdellah Ezzati FST Settataicha al horamiPas encore d'évaluation
- Chapitre 1 - Planification Et PreparationDocument32 pagesChapitre 1 - Planification Et PreparationMohamed El HaoudiPas encore d'évaluation
- Fiche 3 - Exercice Bobo Dioulasso 3Document3 pagesFiche 3 - Exercice Bobo Dioulasso 3BADOLOPas encore d'évaluation
- Cours Langage C Et C++ - Partie 1Document35 pagesCours Langage C Et C++ - Partie 1kouemoPas encore d'évaluation
- ChapitreDocument25 pagesChapitreyassmineelbessiPas encore d'évaluation
- TALBI IBRAHIM HtcondorDocument25 pagesTALBI IBRAHIM HtcondorIbrahim TalbiPas encore d'évaluation
- Processus Unifie UP and 2TUPDocument50 pagesProcessus Unifie UP and 2TUPSerge OngoloPas encore d'évaluation
- Python - DS 1 55Document55 pagesPython - DS 1 55مريم جميعيPas encore d'évaluation
- Comment Sécuriser Un Site WebDocument22 pagesComment Sécuriser Un Site WebWâssim HlélPas encore d'évaluation
- Présentation de Projet - Licence PFEDocument38 pagesPrésentation de Projet - Licence PFEYasmine TounsiPas encore d'évaluation
- J2EE ServletDocument60 pagesJ2EE Servlethajar razikPas encore d'évaluation
- Parcours Avenir 11 ClermontDocument2 pagesParcours Avenir 11 ClermontEnzo DurandPas encore d'évaluation
- Synthese Module 1 ReseauDocument8 pagesSynthese Module 1 ReseauQuentin LambertPas encore d'évaluation
- ERP MES - Chapitre5 - Etudiants PDFDocument7 pagesERP MES - Chapitre5 - Etudiants PDFkhelif hendPas encore d'évaluation
- Conception Et Réalisation D'un Système D'information Pour VoitureDocument64 pagesConception Et Réalisation D'un Système D'information Pour Voitureqsdfghjkl100% (1)
- Gestion Des Droits D'accès: Impératifs de Sécurité Sécurité Des Bases de DonnéesDocument7 pagesGestion Des Droits D'accès: Impératifs de Sécurité Sécurité Des Bases de DonnéesDionguePas encore d'évaluation
- Activité 2-Document - SourceDocument2 pagesActivité 2-Document - SourceSOUHA CHAARPas encore d'évaluation
- JLH A Exercices Resolus PDFDocument128 pagesJLH A Exercices Resolus PDFhanaaaaaaaaaePas encore d'évaluation
- Exercice 1Document4 pagesExercice 1Toto Le boPas encore d'évaluation
- Python3 A Garder CommeDocument56 pagesPython3 A Garder Commetemporeda487Pas encore d'évaluation
- OLAPDocument14 pagesOLAPAvatar AmranePas encore d'évaluation
- NormalisationDocument49 pagesNormalisationArmand Muteb AmkPas encore d'évaluation
- Vie 7064397 PDFDocument1 pageVie 7064397 PDFjaPas encore d'évaluation
- Prog Parallel eDocument82 pagesProg Parallel eEmmanuel FokaPas encore d'évaluation
- Rapport Greencom Fin-1Document56 pagesRapport Greencom Fin-1Souhail GhalimPas encore d'évaluation
- React and ReduxDocument28 pagesReact and ReduxAmagana SagaraPas encore d'évaluation