Vous aimerez peut-être aussi
- Spring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplateD'EverandSpring Boot par la pratique: Développer les services Rest avec Spring-Boot et Spring-RestTemplatePas encore d'évaluation
- 04 - Comprendre-Utiliser-Filebeat-Stack-ElkDocument27 pages04 - Comprendre-Utiliser-Filebeat-Stack-ElkChristian BibouePas encore d'évaluation
- 1 TP1 installationOpenERPDocument4 pages1 TP1 installationOpenERPAdiatta DiedhiouPas encore d'évaluation
- Collect Logs Kafka Graylog2Document34 pagesCollect Logs Kafka Graylog2Ala Ben BrahimPas encore d'évaluation
- ArcGis Pro TutosDocument61 pagesArcGis Pro TutosmoinahousnaPas encore d'évaluation
- Rsyslog PhpsyslogngDocument11 pagesRsyslog PhpsyslogngBlin NkoukaPas encore d'évaluation
- 02 - Installation-Configuration-ElkDocument9 pages02 - Installation-Configuration-ElkChristian BibouePas encore d'évaluation
- TP Réseaux 4 - Installation Et Configuration D'un Serveur Web ApacheDocument6 pagesTP Réseaux 4 - Installation Et Configuration D'un Serveur Web ApacheRigelPas encore d'évaluation
- 06 Comprendre Utiliser Packetbeat Stack ElkDocument18 pages06 Comprendre Utiliser Packetbeat Stack ElkChristian BibouePas encore d'évaluation
- Sujet - TP - 4 Kibana - Tierno Oumar DIALLO Bach3 Cyber EcetechDocument19 pagesSujet - TP - 4 Kibana - Tierno Oumar DIALLO Bach3 Cyber EcetechAnonyme10Pas encore d'évaluation
- Procedure GlpiDocument10 pagesProcedure GlpiMohssin FsjesPas encore d'évaluation
- Apache CamelDocument12 pagesApache CamelmouradPas encore d'évaluation
- ITC314 - TP3 - Configuration de ServeursDocument3 pagesITC314 - TP3 - Configuration de Serveursamine.besrour5214Pas encore d'évaluation
- Gray LogDocument9 pagesGray LogElwan NdiayePas encore d'évaluation
- Maarch RM - Procédure D'installation v2Document4 pagesMaarch RM - Procédure D'installation v2ThierryPas encore d'évaluation
- Support Dinstallation de GraylogDocument18 pagesSupport Dinstallation de GraylogHdia Mouhamed AliPas encore d'évaluation
- Ma ArchDocument30 pagesMa ArchBabacar Sakho100% (1)
- INSTALL FRDocument3 pagesINSTALL FRDem GagatamPas encore d'évaluation
- Serveur Web LINUX UbuntuDocument22 pagesServeur Web LINUX UbuntuabdelkrimoPas encore d'évaluation
- Travaux Pratique-Serveur ApacheDocument13 pagesTravaux Pratique-Serveur ApacheJay MenonPas encore d'évaluation
- ApacheDocument10 pagesApachedenzelsPas encore d'évaluation
- Analyser Les Performances Du SystèmeDocument4 pagesAnalyser Les Performances Du SystèmeRajae EllPas encore d'évaluation
- Rsyslog 2021Document42 pagesRsyslog 2021youssoufibrahimtraorePas encore d'évaluation
- OpenNMS Installation Guide DebianDocument11 pagesOpenNMS Installation Guide Debiannfplacide100% (1)
- TP3 DjangoDocument5 pagesTP3 Djangoradhia saidanePas encore d'évaluation
- Protection Application WebDocument16 pagesProtection Application WebtestPas encore d'évaluation
- ConfigapacheDocument25 pagesConfigapacheSalissou MoutariPas encore d'évaluation
- Gestion Mémoire Avec PostgreSQLDocument12 pagesGestion Mémoire Avec PostgreSQLMoïse KouadioPas encore d'évaluation
- DEV-02 - Log FilesDocument23 pagesDEV-02 - Log Files1m0zvrtPas encore d'évaluation
- MRTG - Documentation Ubuntu Franc Op HoneDocument3 pagesMRTG - Documentation Ubuntu Franc Op HonelebbadoPas encore d'évaluation
- Securiser ApacheDocument14 pagesSecuriser Apachelydia_lamiaPas encore d'évaluation
- Couplage Apache TomcatDocument8 pagesCouplage Apache TomcattotobubuPas encore d'évaluation
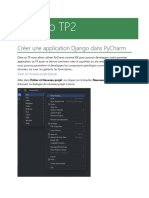
- Django Tp2: Créer Une Application Django Dans PycharmDocument13 pagesDjango Tp2: Créer Une Application Django Dans PycharmLobna SidiaPas encore d'évaluation
- LINUXDocument59 pagesLINUXrianasontsiravaPas encore d'évaluation
- 2 ConfigurationOpenERpDocument9 pages2 ConfigurationOpenERpJihanePas encore d'évaluation
- IptablesDocument9 pagesIptablesGhofrane FerchichiPas encore d'évaluation
- Implementation de La Securite Linux LPI 102Document8 pagesImplementation de La Securite Linux LPI 102NGOMPas encore d'évaluation
- HTTP MysqlDocument66 pagesHTTP MysqlAwa SALLPas encore d'évaluation
- 1 - Installation Manuelle de Nagios Centreon - DebianDocument39 pages1 - Installation Manuelle de Nagios Centreon - DebianAndrew Fleming100% (2)
- Chapitre 9 - Commandes UtilesDocument31 pagesChapitre 9 - Commandes UtilesHamid O.A.Pas encore d'évaluation
- 12 - Deboguer-Vos-Conteneurs-Et-Images-DockersDocument14 pages12 - Deboguer-Vos-Conteneurs-Et-Images-DockersChristian BibouePas encore d'évaluation
- Serveur WebDocument9 pagesServeur WebArmel NguetaPas encore d'évaluation
- 0577 Documentation Sur NginxDocument7 pages0577 Documentation Sur NginxOussama MahmoudiPas encore d'évaluation
- Mise en Place Serveur WebDocument29 pagesMise en Place Serveur WebUriel OuakePas encore d'évaluation
- Installation Nagios 4.4.6 Debian 10Document4 pagesInstallation Nagios 4.4.6 Debian 10itachi uchihaPas encore d'évaluation
- Mon Utilisation de Sublime Text 3: À-Propos..Document8 pagesMon Utilisation de Sublime Text 3: À-Propos..Atoumane LayePas encore d'évaluation
- Securite PHP Pour Les Tout PetitsDocument17 pagesSecurite PHP Pour Les Tout PetitsdurvelPas encore d'évaluation
- Chapitre 2 - Utiliser SparkDocument11 pagesChapitre 2 - Utiliser Sparksyslinux2000Pas encore d'évaluation
- Guide Iinstallation Odoo8Document8 pagesGuide Iinstallation Odoo8agrimaABDELLAHPas encore d'évaluation
- Tutoriel Import Donnees IGN Postgresql v1Document7 pagesTutoriel Import Donnees IGN Postgresql v1herizorazanajaoPas encore d'évaluation
- Introduction À Laravel - CoursDocument21 pagesIntroduction À Laravel - CoursJean marc KonanPas encore d'évaluation
- Dennis-De-Swart - Php-Stanford-Nlp-Datastore - PackagistDocument5 pagesDennis-De-Swart - Php-Stanford-Nlp-Datastore - PackagistKamer ProgramerPas encore d'évaluation
- Installation PhpMyAdminDocument7 pagesInstallation PhpMyAdminFares Ych16Pas encore d'évaluation
- Glpi FinalDocument15 pagesGlpi Finalapi-358853016Pas encore d'évaluation
- Chap 7Document25 pagesChap 7syslinux2000Pas encore d'évaluation
- Introduction A Apache Sous Gnulinux crc11 c19Document21 pagesIntroduction A Apache Sous Gnulinux crc11 c19Jeff De BrugesPas encore d'évaluation
- Linux - Intégration de Fichiers Logs À QRadarDocument3 pagesLinux - Intégration de Fichiers Logs À QRadarHarris DPas encore d'évaluation
- Analyse de Fichiers LogDocument3 pagesAnalyse de Fichiers LogFlorent BakaPas encore d'évaluation
- Cours Nagios 3 - Installation Et Premiere Configuration de NagiosDocument19 pagesCours Nagios 3 - Installation Et Premiere Configuration de NagiosLyes StiviGiPas encore d'évaluation
- 37 Inserer Une Zone de Texte 2 PagesDocument2 pages37 Inserer Une Zone de Texte 2 PagesChristian BibouePas encore d'évaluation
- Guide Complet Gestion Logs DevopsDocument16 pagesGuide Complet Gestion Logs Devopschristophe.forestier01Pas encore d'évaluation
- 18 - Goroutines-GolangDocument10 pages18 - Goroutines-GolangChristian BibouePas encore d'évaluation
- 14 - Interfaces-GolangDocument6 pages14 - Interfaces-GolangChristian BibouePas encore d'évaluation
- 43 Traduire Un Texte 1 PageDocument1 page43 Traduire Un Texte 1 PageChristian BibouePas encore d'évaluation
- 42 Coupure Des Mots 1 PageDocument1 page42 Coupure Des Mots 1 PageChristian BibouePas encore d'évaluation
- 35 Tableaux 8 PagesDocument8 pages35 Tableaux 8 PagesChristian BibouePas encore d'évaluation
- 44 Publipostage 10 PagesDocument10 pages44 Publipostage 10 PagesChristian BibouePas encore d'évaluation
- La Programmation Orientée Objet Dans Le Langage de Programmation GODocument7 pagesLa Programmation Orientée Objet Dans Le Langage de Programmation GOFrederic SaainePas encore d'évaluation
- 08 - Tableaux-GolangDocument13 pages08 - Tableaux-GolangChristian BibouePas encore d'évaluation
- 09 - Tp-Jeu-Du-Morpions-GolangDocument9 pages09 - Tp-Jeu-Du-Morpions-GolangChristian BibouePas encore d'évaluation
- Gestion Audio SDLDocument29 pagesGestion Audio SDLnathanaelPas encore d'évaluation
- 10 - Pointeurs-GolangDocument9 pages10 - Pointeurs-GolangChristian BibouePas encore d'évaluation
- 04 - Conditions-GolangDocument11 pages04 - Conditions-GolangChristian BibouePas encore d'évaluation
- Variables Golang PDFDocument15 pagesVariables Golang PDFsouad sadkiPas encore d'évaluation
- Fonction Golang PDFDocument7 pagesFonction Golang PDFsouad sadkiPas encore d'évaluation
- Micro Pratique - Février-Mars 2024Document84 pagesMicro Pratique - Février-Mars 2024James HowlettPas encore d'évaluation
- Ench Pdf-KlyDocument52 pagesEnch Pdf-KlyChristian BibouePas encore d'évaluation
- 2-Concepts Et Principes Fondamentaux de La SIDocument17 pages2-Concepts Et Principes Fondamentaux de La SIChristian BibouePas encore d'évaluation
- 00 - Cours-Introduction-Sdl-2Document3 pages00 - Cours-Introduction-Sdl-2Christian BibouePas encore d'évaluation
- 00 - Cours-Apprendre-Langage-Programmation-GoDocument6 pages00 - Cours-Apprendre-Langage-Programmation-GoChristian BibouePas encore d'évaluation
- Eyrolles Chatgpt Le Guide Du DebutantDocument286 pagesEyrolles Chatgpt Le Guide Du DebutantChristian BibouePas encore d'évaluation
- 01 - Telechargement-Compilation-Projet-SdlDocument10 pages01 - Telechargement-Compilation-Projet-SdlChristian BibouePas encore d'évaluation
- Git Cmds BranchsDocument4 pagesGit Cmds BranchsChristian BibouePas encore d'évaluation
- Etude Et Mise en Place Dune Solution de Monitoring Open Source SlidesDocument52 pagesEtude Et Mise en Place Dune Solution de Monitoring Open Source SlidesChristian BibouePas encore d'évaluation
- Git Cmds BaseDocument7 pagesGit Cmds BaseChristian BibouePas encore d'évaluation
- Profession Photographe IndépendantDocument383 pagesProfession Photographe IndépendantChristian BibouePas encore d'évaluation
- Ench Pdf-KlyDocument56 pagesEnch Pdf-KlyChristian BibouePas encore d'évaluation
- TP 2 Admin Reseaux-1Document10 pagesTP 2 Admin Reseaux-1Weslati AminPas encore d'évaluation
- L'Overdose: FentanylDocument48 pagesL'Overdose: FentanylLegrandPas encore d'évaluation
- Etude Et Mise en Oeuvre Du WebRTCDocument42 pagesEtude Et Mise en Oeuvre Du WebRTCkylian donateloPas encore d'évaluation
- Rapport Pfe MobileDocument56 pagesRapport Pfe MobileAmir MesbehPas encore d'évaluation
- TP3 - BeanDocument3 pagesTP3 - BeanBrahim Ben SaadaPas encore d'évaluation
- Rapport Projet Service Push SmsDocument50 pagesRapport Projet Service Push SmsDSTEL100% (2)
- Cours Programmation Objet Avec TD CorrigésDocument115 pagesCours Programmation Objet Avec TD CorrigésLaila NakkaiiPas encore d'évaluation
- HTML CssDocument118 pagesHTML CssFATIMA ZAHRA MACHKOUR100% (1)
- ReactJS - NodeJS - Authentification Et SécuritéDocument56 pagesReactJS - NodeJS - Authentification Et SécuritéAmine NafidPas encore d'évaluation
- TP METASPLOIT CEH-SYSTEM HACKING-esaDocument17 pagesTP METASPLOIT CEH-SYSTEM HACKING-esaoriane YakinPas encore d'évaluation
- Cours - Technologies WEB2.0 - Ch2 - JAVASCRIPT - Partie1Document32 pagesCours - Technologies WEB2.0 - Ch2 - JAVASCRIPT - Partie1maryemPas encore d'évaluation
- Problèmes Et Solutions Rencontrés Avec DIAGRAMMESDocument3 pagesProblèmes Et Solutions Rencontrés Avec DIAGRAMMESمسك الختامPas encore d'évaluation
- FWK TP 01Document6 pagesFWK TP 01Hamza AbdouliPas encore d'évaluation
- TP1 openSSL CryptoSym PDFDocument3 pagesTP1 openSSL CryptoSym PDFHanen BouhaddaPas encore d'évaluation
- Mémoire en MATHEMATIQUES ET INFORMATIQUEDocument72 pagesMémoire en MATHEMATIQUES ET INFORMATIQUETHIERNO ABDOURAHMANE NIANGPas encore d'évaluation
- Espaces de NomsDocument18 pagesEspaces de NomsMaella AdjPas encore d'évaluation
- Cours 7Document23 pagesCours 7sedkaouiwassilaPas encore d'évaluation
- Rapport de StageDocument23 pagesRapport de Stagewafae elmakhyariPas encore d'évaluation
- Commandes LinuxDocument24 pagesCommandes LinuxBOUJNAID NaimaPas encore d'évaluation
- Master IAO Année 2022: Pr. El Mamoun SOUIDIDocument12 pagesMaster IAO Année 2022: Pr. El Mamoun SOUIDIEasy GetinfoPas encore d'évaluation
- Profil LinkedinDocument5 pagesProfil LinkedinPhilippe VaillancourtPas encore d'évaluation
- Environnement Numérique, Sécurité Informatique Et MultimédiaDocument2 pagesEnvironnement Numérique, Sécurité Informatique Et MultimédiaErick TeyoPas encore d'évaluation
- C V-BibossDocument2 pagesC V-BibossGilbert GilbertoPas encore d'évaluation
- Web Tp1 HTMLDocument7 pagesWeb Tp1 HTMLjuliencouleau78Pas encore d'évaluation
- Tutoriel HTMLDocument21 pagesTutoriel HTMLChakib BenmhamedPas encore d'évaluation
- Creer Table Des MatieresDocument3 pagesCreer Table Des MatieresSamsung SamsungPas encore d'évaluation
- Fhir HH TrainingDocument42 pagesFhir HH TrainingFBPas encore d'évaluation
- Logiciel Ccleaner Professional Plus 6.02 Win Multi Activator PortableDocument4 pagesLogiciel Ccleaner Professional Plus 6.02 Win Multi Activator Portablestephen ruedaPas encore d'évaluation
- PfileDocument11 pagesPfileChaymae DkhissiPas encore d'évaluation
- Prog Form Module Culture Et Technique Du Numérique 22-09-2021Document50 pagesProg Form Module Culture Et Technique Du Numérique 22-09-2021Omar BouguatayaPas encore d'évaluation
- Config AlcatelDocument7 pagesConfig AlcatelJoseph EdwardsPas encore d'évaluation
- Jquery PDFDocument83 pagesJquery PDFIfa FakhriPas encore d'évaluation