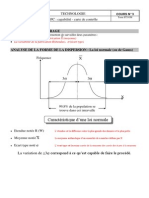
Vous aimerez peut-être aussi
- Les tableaux croisés dynamiques avec Excel: Pour aller plus loin dans votre utilisation d'ExcelD'EverandLes tableaux croisés dynamiques avec Excel: Pour aller plus loin dans votre utilisation d'ExcelPas encore d'évaluation
- Excel, remise à niveau et perfectionnement: Pour aller plus loin dans votre utilisation d'ExcelD'EverandExcel, remise à niveau et perfectionnement: Pour aller plus loin dans votre utilisation d'ExcelPas encore d'évaluation
- Dictionnaire Amoureux Des Dieux Et Des DéessesDocument273 pagesDictionnaire Amoureux Des Dieux Et Des DéessesKone Assane100% (1)
- CHAPITRE 2 StatistiqueDocument59 pagesCHAPITRE 2 StatistiqueAbdallahi SidiPas encore d'évaluation
- Les erreurs fréquentes en Mathématiques du cycle secondaire: Enquête statistique - TOME IID'EverandLes erreurs fréquentes en Mathématiques du cycle secondaire: Enquête statistique - TOME IIPas encore d'évaluation
- AcpDocument33 pagesAcpRachid El AlaouiPas encore d'évaluation
- Renard - Probabilites Et Statistiques Appliquees A L'hydrologieDocument63 pagesRenard - Probabilites Et Statistiques Appliquees A L'hydrologieAnonymous BZ0l8Qylp100% (2)
- Boite A Moustaches PDFDocument14 pagesBoite A Moustaches PDFMohammed RissaliPas encore d'évaluation
- Statistique CoDocument4 pagesStatistique CoYves-laurent Soumelong100% (1)
- TD3 Quanti R PDFDocument9 pagesTD3 Quanti R PDFkadda zerroukiPas encore d'évaluation
- Application StatistiqueDocument68 pagesApplication Statistiqueabdoul7Pas encore d'évaluation
- TD3 Janvier09Document9 pagesTD3 Janvier09pascalburumePas encore d'évaluation
- TP4 MLDocument10 pagesTP4 MLWalid LahsikiPas encore d'évaluation
- FR Tanagra AFDMDocument13 pagesFR Tanagra AFDMKasaPas encore d'évaluation
- Ressource1 Méthodes Et Outils Qualité-ConvertiDocument18 pagesRessource1 Méthodes Et Outils Qualité-ConvertiBEZZINE Chiheb50% (2)
- 3 - Cours Bisostat - M1 - ENSAF - Chapitre 3Document120 pages3 - Cours Bisostat - M1 - ENSAF - Chapitre 3Gervais MbahoukaPas encore d'évaluation
- Section 4Document32 pagesSection 4Souzak MelPas encore d'évaluation
- Graphes en Statistiques DescriptivesDocument3 pagesGraphes en Statistiques Descriptiveshakim hakimPas encore d'évaluation
- Essaie ACDocument29 pagesEssaie ACAns DiattaPas encore d'évaluation
- 1 Données Quantitatives Discrètes TP2: Analyse de Données Quantitatives Avec Le Logiciel RDocument6 pages1 Données Quantitatives Discrètes TP2: Analyse de Données Quantitatives Avec Le Logiciel Rmmorad aamraouyPas encore d'évaluation
- Analyse AnovaDocument28 pagesAnalyse AnovaPeter KaborePas encore d'évaluation
- Rsa 1995 43 3 5 0Document17 pagesRsa 1995 43 3 5 0Reda ChattahyPas encore d'évaluation
- Chapitres 2 Et 3 Stats 1ère Année Ing.Document10 pagesChapitres 2 Et 3 Stats 1ère Année Ing.fouadlaamiratelyasminPas encore d'évaluation
- Corrigé Du Test 1 SSDocument4 pagesCorrigé Du Test 1 SSthouraya hadj hassenPas encore d'évaluation
- GRAIE Criteres INDICATEURS AUTOEVALUTIONdesMODELES AUTOSURVEILLANCE WEB18 v1Document17 pagesGRAIE Criteres INDICATEURS AUTOEVALUTIONdesMODELES AUTOSURVEILLANCE WEB18 v1Lionel Cédric GohouedePas encore d'évaluation
- 379Document12 pages379Mounir FrijaPas encore d'évaluation
- Diagramme 2 NécessitéDocument8 pagesDiagramme 2 NécessitésanaePas encore d'évaluation
- Ressource HistogrammeDocument18 pagesRessource HistogrammeArbia KarmoussiPas encore d'évaluation
- Chapitre 02Document11 pagesChapitre 02mayar mimiPas encore d'évaluation
- Operateurs FonctionsDocument18 pagesOperateurs FonctionsAngelo mahafePas encore d'évaluation
- Cours 9 StatistiquesDocument2 pagesCours 9 StatistiquesPierre VandemierePas encore d'évaluation
- Statistique DescriptiveDocument19 pagesStatistique Descriptivemed elhaddadPas encore d'évaluation
- Statistiques UnivarieesDocument14 pagesStatistiques UnivarieesGaël Koboyo KAOPas encore d'évaluation
- Prédiction Des Prix Des Actions Des Boursiers en MalaisieDocument10 pagesPrédiction Des Prix Des Actions Des Boursiers en MalaisieSouid GhadaPas encore d'évaluation
- MR-Tekaya 06Document55 pagesMR-Tekaya 06tounkfodePas encore d'évaluation
- 02Document2 pages02sankhasubhra mandalPas encore d'évaluation
- Https:/helios2.Mi - Parisdescartes.fr/ Vperduca/cours/programmation/R2 SDocument25 pagesHttps:/helios2.Mi - Parisdescartes.fr/ Vperduca/cours/programmation/R2 SEsseba MarthePas encore d'évaluation
- Application de L'analyse en Composantes Principales ACP : Préparé Par: Encadrée ParDocument5 pagesApplication de L'analyse en Composantes Principales ACP : Préparé Par: Encadrée ParNouha AlaePas encore d'évaluation
- Guide D'utilisation de Stata - Chapitre 3: July 2017Document17 pagesGuide D'utilisation de Stata - Chapitre 3: July 2017Franck Armand Makay RobalaPas encore d'évaluation
- 1er Partiel De-Wps Office-4Document7 pages1er Partiel De-Wps Office-4markov dadavodounPas encore d'évaluation
- طلب66Document203 pagesطلب66zerfaouiPas encore d'évaluation
- MMCHAP 4 - ML - Ver Etudiant 23 - 24Document16 pagesMMCHAP 4 - ML - Ver Etudiant 23 - 24Sameh SebaiPas encore d'évaluation
- Project StatDocument6 pagesProject StatNassim JrPas encore d'évaluation
- PDF StatistiquesDocument13 pagesPDF StatistiquesbakasPas encore d'évaluation
- TD1 Statistique 2020-2021Document2 pagesTD1 Statistique 2020-2021Chrif NadorPas encore d'évaluation
- Polycop BioDocument57 pagesPolycop BioKa TiaPas encore d'évaluation
- FR Tanagra AfcDocument10 pagesFR Tanagra AfcEl Hadj NdoyePas encore d'évaluation
- Support TP MEF Tome 1Document11 pagesSupport TP MEF Tome 1Majda AmzirPas encore d'évaluation
- Intro Scilab PDFDocument39 pagesIntro Scilab PDFELmokhtar HamrouniPas encore d'évaluation
- 2 Intro ScilabDocument39 pages2 Intro Scilabblondelle noumoPas encore d'évaluation
- 1L Statistiques CoursDocument15 pages1L Statistiques CourshhedfiPas encore d'évaluation
- Chapitre 2 Les Analyses Univariées Et Bivariées 2LNSGDocument21 pagesChapitre 2 Les Analyses Univariées Et Bivariées 2LNSGSouad Bouabana100% (1)
- TD1 StatDocument3 pagesTD1 StatSK RUODAPas encore d'évaluation
- TD1 Stat PDFDocument3 pagesTD1 Stat PDFSK RUODAPas encore d'évaluation
- MSP-SPC 1Document100 pagesMSP-SPC 1HammamiSalahPas encore d'évaluation
- Evaluations Externes Internationales - PISA - Mathématiques - Questionnaire (Ressource 10416)Document12 pagesEvaluations Externes Internationales - PISA - Mathématiques - Questionnaire (Ressource 10416)Ogion123Pas encore d'évaluation
- Cours Biostat Chapitre1 L2 19 20Document13 pagesCours Biostat Chapitre1 L2 19 20zerfaouiPas encore d'évaluation
- TP Matlab TP1Document8 pagesTP Matlab TP1abahawi07Pas encore d'évaluation
- Histogramme d'image: Dévoilement d'informations visuelles, exploration des profondeurs des histogrammes d'images en vision par ordinateurD'EverandHistogramme d'image: Dévoilement d'informations visuelles, exploration des profondeurs des histogrammes d'images en vision par ordinateurPas encore d'évaluation
- Page D'accueil - Espace Élèves - PRONOTE 2023.0.2.7 - Centre National d' Enseignement E-LearningDocument1 pagePage D'accueil - Espace Élèves - PRONOTE 2023.0.2.7 - Centre National d' Enseignement E-LearningzhcczgfbmwPas encore d'évaluation
- Cours de Gestion de Production 1.2.3 Gmp2 VPDocument30 pagesCours de Gestion de Production 1.2.3 Gmp2 VPMohamed SabrePas encore d'évaluation
- Les Thèmes Du Dalf C1Document28 pagesLes Thèmes Du Dalf C1Ioana Babarus100% (1)
- Chauffeur SPLDocument1 pageChauffeur SPLmeryem.vfsPas encore d'évaluation
- Les Bases de La Thermodynamique 2 Chapitre II PDFDocument11 pagesLes Bases de La Thermodynamique 2 Chapitre II PDFmahdi amraouiPas encore d'évaluation
- Jeremie Gouyon Ok-2Document289 pagesJeremie Gouyon Ok-2leucinedijaPas encore d'évaluation
- Structure REFECTOIRE SODIGAZ PDFDocument44 pagesStructure REFECTOIRE SODIGAZ PDFheheheyPas encore d'évaluation
- TD2 MCC Corrigé InfotroniqueDocument3 pagesTD2 MCC Corrigé InfotroniqueRima AlayaPas encore d'évaluation
- NF EN 1993-1-7 NA Aout 2008Document4 pagesNF EN 1993-1-7 NA Aout 2008fauvyPas encore d'évaluation
- Is - Corrigé de L - Étude de Cas Ayda (Version 2016)Document5 pagesIs - Corrigé de L - Étude de Cas Ayda (Version 2016)Hicham DaouchPas encore d'évaluation
- Sup'air SellettesDocument1 pageSup'air SellettesStefanoPas encore d'évaluation
- AUguste Blanqui L'Éternité Par Les AstresDocument79 pagesAUguste Blanqui L'Éternité Par Les AstresYvan KalievPas encore d'évaluation
- ToyotismeDocument4 pagesToyotismeAbdelkarimPas encore d'évaluation
- Exos PDT Conjugaison G1Document16 pagesExos PDT Conjugaison G1Olivier Benard100% (1)
- TIG Ta33 Panneau de Commande FRDocument22 pagesTIG Ta33 Panneau de Commande FRk.a55Pas encore d'évaluation
- Solution TD3 Module POO Univ OuarglaDocument7 pagesSolution TD3 Module POO Univ OuarglaEmna KanzariPas encore d'évaluation
- Syllabus LAITS ET PRODUITS LAITIERS - 2Document3 pagesSyllabus LAITS ET PRODUITS LAITIERS - 2Gedion DouaPas encore d'évaluation
- Sco BP1Document5 pagesSco BP1Philippe Diego DelasvegasPas encore d'évaluation
- Cours OrdonnacementDocument17 pagesCours OrdonnacementMed ArefPas encore d'évaluation
- CPS ClimatisationDocument2 pagesCPS Climatisationilyass tourkiPas encore d'évaluation
- PDFDocument24 pagesPDFCompétitionPas encore d'évaluation
- Hygiène HospitalièreDocument4 pagesHygiène HospitalièreJamal MalouPas encore d'évaluation
- Methode de TravailDocument2 pagesMethode de Travailamal akhoulouPas encore d'évaluation
- AFAM - Projet de RechercheDocument23 pagesAFAM - Projet de RechercheAlbert Francis Abega MekongoPas encore d'évaluation
- Glossaire Les Littoraux - PufDocument11 pagesGlossaire Les Littoraux - PufAndréaPas encore d'évaluation
- Examples Questions Examen AcoustiqueDocument4 pagesExamples Questions Examen AcoustiquePierreFontenellePas encore d'évaluation
- Matièreexamen 4 Ème Aet DDocument6 pagesMatièreexamen 4 Ème Aet DToby 17Pas encore d'évaluation
- Composition Et Correction Français 1AP T2Document4 pagesComposition Et Correction Français 1AP T2Boud Aek100% (1)
- Exam MDMDocument4 pagesExam MDMHaithem AminePas encore d'évaluation