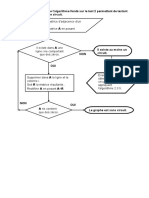
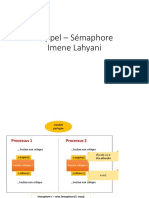
Vous aimerez peut-être aussi
- Fiche Module Théorie Des Langages Et Techniques de CompilationDocument3 pagesFiche Module Théorie Des Langages Et Techniques de CompilationOssama JdidiPas encore d'évaluation
- TD2 Tla 10-11Document2 pagesTD2 Tla 10-11Sabrine Souissi0% (1)
- TP1 CompilationDocument6 pagesTP1 CompilationEmna RekikPas encore d'évaluation
- Theorie Des Graphes-ExtraitDocument29 pagesTheorie Des Graphes-Extraitadel houchePas encore d'évaluation
- Ch4 - Les Automates À PilesDocument20 pagesCh4 - Les Automates À PilesYasmine TliliPas encore d'évaluation
- Chap 1 Partie 1 Logique ClassiqueDocument41 pagesChap 1 Partie 1 Logique ClassiqueOro LoloPas encore d'évaluation
- Solution TD Jeux LPODocument6 pagesSolution TD Jeux LPOⴷⵔⵉⵙ ⵜⴰⵣⵉⵖPas encore d'évaluation
- CH 4 Les Automates À PileDocument13 pagesCH 4 Les Automates À PileSouilem CHAHERPas encore d'évaluation
- TD1. Arbre CouvrantDocument2 pagesTD1. Arbre Couvrantsafe selmi100% (1)
- Résumer Genie Logiciel-1Document4 pagesRésumer Genie Logiciel-1HathatPas encore d'évaluation
- Introduction À La Théorie Des Graphes: 1) OriginesDocument12 pagesIntroduction À La Théorie Des Graphes: 1) OriginesSwitch GangPas encore d'évaluation
- TLA: Travaux Dirigés 2 (1 Génie Info) : (Avec Correction)Document4 pagesTLA: Travaux Dirigés 2 (1 Génie Info) : (Avec Correction)Chokri ChaimaPas encore d'évaluation
- Question de Cours Reseaux 2Document4 pagesQuestion de Cours Reseaux 2Eslemhoum MedlPas encore d'évaluation
- Exam 1617Document2 pagesExam 1617walidmgPas encore d'évaluation
- Aut TD1Document3 pagesAut TD1Sahbi Sk100% (1)
- Untitled 1Document5 pagesUntitled 1TheoPas encore d'évaluation
- Compilation 2Document20 pagesCompilation 2BouimizarPas encore d'évaluation
- Cours #9 - Diagramme D - ObjetDocument10 pagesCours #9 - Diagramme D - Objetidir belliliPas encore d'évaluation
- Correction Examen Final - TLC L3 2019Document3 pagesCorrection Examen Final - TLC L3 2019Ninå SåPas encore d'évaluation
- 13 TDC Uml Diagramme SequenceDocument2 pages13 TDC Uml Diagramme SequenceBoutaina BerradiPas encore d'évaluation
- TD 1Document2 pagesTD 1Amel Ben YaakoubPas encore d'évaluation
- Cours 4 Dependance FonctionnelDocument17 pagesCours 4 Dependance FonctionnelSonia BitPas encore d'évaluation
- Introduction À La LogiqueDocument35 pagesIntroduction À La Logiqueamore mio0% (1)
- Correction Partiel 2008 2009Document4 pagesCorrection Partiel 2008 2009micipsaPas encore d'évaluation
- Serie1 - Conception Orienté Objet Avec UML-2Document6 pagesSerie1 - Conception Orienté Objet Avec UML-2abdessamad.chohaidiPas encore d'évaluation
- Corrige GL 2021Document2 pagesCorrige GL 2021PapiPas encore d'évaluation
- Chap 2 Analyse Lexi CaleDocument17 pagesChap 2 Analyse Lexi CaleHarrag MahieddinePas encore d'évaluation
- Gomory PDFDocument47 pagesGomory PDFhalimPas encore d'évaluation
- Controle SystèmeDocument1 pageControle SystèmeAymane AsPas encore d'évaluation
- Introduction CopieDocument132 pagesIntroduction CopieLoubna EnnajiPas encore d'évaluation
- Problème Du Voyageur de Commerce (PVC) : Etude Théorique Du Problème & Etude ExpérimentaleDocument22 pagesProblème Du Voyageur de Commerce (PVC) : Etude Théorique Du Problème & Etude ExpérimentalemarwaabdPas encore d'évaluation
- Cours UMLDocument33 pagesCours UMLdeogratias davoPas encore d'évaluation
- Exercices RecursiviteDocument3 pagesExercices RecursiviteMed MohamedPas encore d'évaluation
- RODocument8 pagesROchaimaedroussiPas encore d'évaluation
- TP01 - BasesDocument5 pagesTP01 - BasesSoumana Abdou AmadouPas encore d'évaluation
- COMPLEXIT2Document4 pagesCOMPLEXIT2Rekia RPas encore d'évaluation
- TD N°1 Diagramme de Classes UMLDocument2 pagesTD N°1 Diagramme de Classes UMLOussama AyachiamorPas encore d'évaluation
- Ia TD1Document4 pagesIa TD1chaima ben ghorbalPas encore d'évaluation
- Serie N°3 CorrigéDocument7 pagesSerie N°3 CorrigélinaPas encore d'évaluation
- Intelligence Artificielle Sujet 04Document2 pagesIntelligence Artificielle Sujet 04Faralahy UlrichPas encore d'évaluation
- Série SI BD TD 1 Correction 2021Document14 pagesSérie SI BD TD 1 Correction 2021Omar BufteemPas encore d'évaluation
- TP 3-Poo 2022Document1 pageTP 3-Poo 2022Lamine DiengPas encore d'évaluation
- Chap3 AcsiDocument43 pagesChap3 AcsiarielkoliaPas encore d'évaluation
- TD3 Big DataDocument2 pagesTD3 Big DataMohamed Sidi BrahimPas encore d'évaluation
- TD2 IndexationDocument3 pagesTD2 IndexationAmine AmiriPas encore d'évaluation
- Securité Informatique ch3Document40 pagesSecurité Informatique ch3Rami RamiPas encore d'évaluation
- Abdd - L3Document2 pagesAbdd - L3Rezzag RezzagPas encore d'évaluation
- 1-Introduction Systèmes D'exploitation I Powerpoint PDFDocument13 pages1-Introduction Systèmes D'exploitation I Powerpoint PDFVino DongaPas encore d'évaluation
- 8 PDFDocument14 pages8 PDFons laadharPas encore d'évaluation
- TP 1Document1 pageTP 1Sarah IBPas encore d'évaluation
- Algorithmes Recherche Opérationnelle Et Théorie Des GraphesDocument23 pagesAlgorithmes Recherche Opérationnelle Et Théorie Des GraphesSfDPas encore d'évaluation
- Graphes Chapitre2Document30 pagesGraphes Chapitre2roPas encore d'évaluation
- Correction TD ProdConsDocument26 pagesCorrection TD ProdConsslim yaichPas encore d'évaluation
- TD2 2021-2022Document2 pagesTD2 2021-2022ayoub attiPas encore d'évaluation
- Cours CompilationDocument8 pagesCours CompilationElbaz AbdelilahPas encore d'évaluation
- Thèse Complète ElongDocument120 pagesThèse Complète ElongNihad HaPas encore d'évaluation
- DHDHDHSJSJDJDHDDHDHDHDHDDocument15 pagesDHDHDHSJSJDJDHDDHDHDHDHDngoue0% (1)
- Projet Programmation Orientée Objet Hotel BookingDocument3 pagesProjet Programmation Orientée Objet Hotel Bookingtebib hamzaPas encore d'évaluation
- Atelier 2 Encapsulation: Classe Et Objet: Objectif Du TPDocument13 pagesAtelier 2 Encapsulation: Classe Et Objet: Objectif Du TPnassim ksouriPas encore d'évaluation
- Suivi Therapeutique Des Mesicaments AntifongiquesDocument9 pagesSuivi Therapeutique Des Mesicaments AntifongiquesEle AkachaPas encore d'évaluation
- 01 - Les InterfacesDocument11 pages01 - Les InterfacesPablo SenePas encore d'évaluation
- BasesDocument11 pagesBasespilote13000Pas encore d'évaluation
- Compare DocumentDocument32 pagesCompare DocumentEle AkachaPas encore d'évaluation
- AntifongiquesDocument27 pagesAntifongiquesEle AkachaPas encore d'évaluation
- Yc OHQw 1 MM 6 D D7 Go 8 PW AOf LT4 Vqoje LL An Mgda LB 7Document143 pagesYc OHQw 1 MM 6 D D7 Go 8 PW AOf LT4 Vqoje LL An Mgda LB 7Ele AkachaPas encore d'évaluation
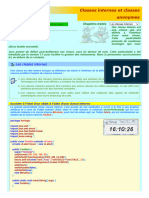
- Les Classes Internes Et Les Classes AnonymesDocument7 pagesLes Classes Internes Et Les Classes AnonymesEle AkachaPas encore d'évaluation
- ZZ FFAIQ4 Wnoo OLv NF4 U H8 KPCJ MRV 4 Hmajp O1 P 1 WoDocument47 pagesZZ FFAIQ4 Wnoo OLv NF4 U H8 KPCJ MRV 4 Hmajp O1 P 1 WoEle AkachaPas encore d'évaluation
- Chapitre 2.Document13 pagesChapitre 2.Ele AkachaPas encore d'évaluation
- TP 3Document4 pagesTP 3Ele AkachaPas encore d'évaluation
- Exercice 1Document1 pageExercice 1Ele AkachaPas encore d'évaluation
- TP 2Document2 pagesTP 2majdoub manelPas encore d'évaluation
- Cours de LinguistiqueDocument17 pagesCours de LinguistiqueKii raPas encore d'évaluation
- Espagnol D1Document5 pagesEspagnol D1Sarah Le PhilippePas encore d'évaluation
- Aggettivi e Pronomi IndefinitiDocument5 pagesAggettivi e Pronomi IndefinitiChristine AlbaPas encore d'évaluation
- En Et Y-PronomsDocument2 pagesEn Et Y-PronomsMonica StereaPas encore d'évaluation
- Dictionnaire Des Sciences Du LangageDocument328 pagesDictionnaire Des Sciences Du LangageRa diaPas encore d'évaluation
- Polycopiã© Annales Examens CompilationDocument48 pagesPolycopiã© Annales Examens Compilationhoss4am.chPas encore d'évaluation
- Liaisons Obligatoires Et Liaisons InterditesDocument2 pagesLiaisons Obligatoires Et Liaisons InterditesMaria PappaPas encore d'évaluation
- ReformulationDocument22 pagesReformulationMokrane ChikhiPas encore d'évaluation
- Accord GENSDocument4 pagesAccord GENSCarmen DogaruPas encore d'évaluation
- 5 - Conjugaison Verbes 1er GroupeDocument3 pages5 - Conjugaison Verbes 1er GroupeCamiloNuñezPas encore d'évaluation
- La Suborbonnee ConjonctiveDocument3 pagesLa Suborbonnee ConjonctiveBacar NiangPas encore d'évaluation
- Fiche de Langue Francaise PDFDocument13 pagesFiche de Langue Francaise PDFmekenasse arielPas encore d'évaluation
- Fiches UD2 Mes Apprentissages 2019 OMAR SERHANIDocument50 pagesFiches UD2 Mes Apprentissages 2019 OMAR SERHANIMouaad AlaouiPas encore d'évaluation
- Resumosfrancs1teste 101030062811 Phpapp02Document4 pagesResumosfrancs1teste 101030062811 Phpapp02ArmindaMoreiraPas encore d'évaluation
- Les Pronoms ToniquesDocument2 pagesLes Pronoms ToniquesAyman Zarefy100% (1)
- Grammaire TE Ce1 LB v2Document38 pagesGrammaire TE Ce1 LB v2zeno73100% (1)
- La Proposition TemporelleDocument2 pagesLa Proposition TemporelleAlexandra Chiricheş100% (2)
- Cours TLA 2023 p2Document42 pagesCours TLA 2023 p2arwabenhadhomPas encore d'évaluation
- Eval Passé Composé CMDocument3 pagesEval Passé Composé CMmoussa.breuillaud5329Pas encore d'évaluation
- La NégationDocument8 pagesLa NégationHelene DanzéPas encore d'évaluation
- Le Discours RapportéDocument4 pagesLe Discours RapportéSà L W ăaPas encore d'évaluation
- SL00502V Si 2017 18Document158 pagesSL00502V Si 2017 18Arno PatyPas encore d'évaluation
- PROGRESSIONS DE FRANCAIS A USAGE PEDAGOGIQUE - 2023-2024 1er Cycle DPFCDocument33 pagesPROGRESSIONS DE FRANCAIS A USAGE PEDAGOGIQUE - 2023-2024 1er Cycle DPFCIshak IshakPas encore d'évaluation
- Compehension Orale 2 - File ÉtudiantsDocument106 pagesCompehension Orale 2 - File ÉtudiantsHan NguyenPas encore d'évaluation
- CM1 Limparfait de Lindicatif ExercicesDocument10 pagesCM1 Limparfait de Lindicatif ExercicesAlejandra Gonzalez OrtizPas encore d'évaluation
- LES ACCORDS ExercicesDocument4 pagesLES ACCORDS Exercicesyukta emrithPas encore d'évaluation
- Orthographe cm2 2017Document7 pagesOrthographe cm2 2017SARAPas encore d'évaluation
- Fiches Parcours 3asc Période 6-1Document72 pagesFiches Parcours 3asc Période 6-1Harley Manning50% (2)
- Rev IerabDocument7 pagesRev IerabAissatou Inna YayaPas encore d'évaluation
- TECFÉE - Exercices PréparatoiresDocument28 pagesTECFÉE - Exercices Préparatoireschahinaze.mekidechePas encore d'évaluation