Vous aimerez peut-être aussi
- Aux 4 Vents Cahier Lecture PDFDocument12 pagesAux 4 Vents Cahier Lecture PDFfred100% (1)
- Jodadat Calcul-LittéralDocument6 pagesJodadat Calcul-LittéralSliman Akki100% (1)
- Premier Cours EDPDocument8 pagesPremier Cours EDPKevin Wilfried N'gouanPas encore d'évaluation
- Partie2CoursTALN UM6SS MasterBD-IA 2022Document33 pagesPartie2CoursTALN UM6SS MasterBD-IA 2022Fatima-ezzahraa Ben bouazzaPas encore d'évaluation
- Analyse Numérique a.lembARKIDocument102 pagesAnalyse Numérique a.lembARKIAder MedPas encore d'évaluation
- Cours Calcul Scientifique CP1Document72 pagesCours Calcul Scientifique CP1oufikmaroua40Pas encore d'évaluation
- Calculabilite SlidesDocument273 pagesCalculabilite SlidessalaPas encore d'évaluation
- Cours - Comparaison Des SuitesDocument11 pagesCours - Comparaison Des SuitesIngenieur EnsaPas encore d'évaluation
- Maths - Suites Numériques Et RéccurenceDocument7 pagesMaths - Suites Numériques Et RéccurenceAlexandre MarleauPas encore d'évaluation
- RCP208 2017 2018 RN 1Document26 pagesRCP208 2017 2018 RN 1Daly ZeddiniPas encore d'évaluation
- Cours 6 - Les VecteursDocument5 pagesCours 6 - Les VecteursAnne OnymePas encore d'évaluation
- NegligeabiliteDocument5 pagesNegligeabiliteDominiquePas encore d'évaluation
- Senace 04Document6 pagesSenace 04medPas encore d'évaluation
- 0007 - Liinstruction de Branchement - Aller À - GotoDocument6 pages0007 - Liinstruction de Branchement - Aller À - GotoAzedine SariyePas encore d'évaluation
- 1re S Suites NumeriquesDocument7 pages1re S Suites NumeriquesMariama DiédhiouPas encore d'évaluation
- Cours 3 Logique Et RaisonnementDocument20 pagesCours 3 Logique Et RaisonnementNessrine AzzouzPas encore d'évaluation
- Chapitre 01 Logique Et Raisonnements Avec Serie D ExerciceDocument21 pagesChapitre 01 Logique Et Raisonnements Avec Serie D ExerciceBadre-eddine FriferPas encore d'évaluation
- Maths 3e VECTEURS DU PLANDocument4 pagesMaths 3e VECTEURS DU PLANNgomaPas encore d'évaluation
- CoursDocument167 pagesCoursimaneeaouattaheePas encore d'évaluation
- 13 Comparaison SuitesDocument15 pages13 Comparaison SuitesBakrim OumaimaPas encore d'évaluation
- 19 Droites MDocument10 pages19 Droites MaliPas encore d'évaluation
- Part 2 - NLPDocument47 pagesPart 2 - NLPABDELHAK MAHFOUDPas encore d'évaluation
- Cours 1 Algèbre - 220928 - 160810Document10 pagesCours 1 Algèbre - 220928 - 160810redakabelfortnitePas encore d'évaluation
- Cours1 - Introduction Au Compressive Sensing Et La ParcimonieDocument45 pagesCours1 - Introduction Au Compressive Sensing Et La ParcimonieantoulysimPas encore d'évaluation
- ExcelDocument9 pagesExcelnour houdaPas encore d'évaluation
- Notes Calcul Differentiel FinalDocument121 pagesNotes Calcul Differentiel FinalEnzoPas encore d'évaluation
- Cours 4ieme Séquence6 Puissances Objectifs 1 Et 2 030123Document3 pagesCours 4ieme Séquence6 Puissances Objectifs 1 Et 2 030123lilirosePas encore d'évaluation
- Cours - Relations BinairesDocument6 pagesCours - Relations Binairesyacine99Pas encore d'évaluation
- LaTex CoursDocument22 pagesLaTex CoursAzizPas encore d'évaluation
- CM2 2014Document42 pagesCM2 2014zakia saadaouiPas encore d'évaluation
- Chapitre 1 Etude de La Deformation Partie 1Document13 pagesChapitre 1 Etude de La Deformation Partie 1Khlif NadaPas encore d'évaluation
- MMC Chapitre 1 DeformationDocument24 pagesMMC Chapitre 1 Deformationkassaui mohamed100% (1)
- Maths Analyse ContinuitéDocument52 pagesMaths Analyse ContinuitéEmmanuel Roche-PitardPas encore d'évaluation
- Chap4 Intro Mod Bool VectSansflouDocument34 pagesChap4 Intro Mod Bool VectSansfloukadaouikadabac35Pas encore d'évaluation
- Part 1Document22 pagesPart 1Areh yare abwan somaliyedPas encore d'évaluation
- Editeur EquationsDocument10 pagesEditeur EquationsFranc-junior FokaPas encore d'évaluation
- Cours - Relations BinairesDocument6 pagesCours - Relations Binairessamuel BiléPas encore d'évaluation
- Annale EDHEC AST1 Maths 2008Document15 pagesAnnale EDHEC AST1 Maths 2008hkPas encore d'évaluation
- Notations Symboles Representations Mathematique Secondaire 2021Document45 pagesNotations Symboles Representations Mathematique Secondaire 2021Bryolys OnangaPas encore d'évaluation
- SystCoord PreingenierieDocument4 pagesSystCoord Preingenieriemia ornedPas encore d'évaluation
- Effectuez Des Plongements de Mots Word EmbeddingsDocument6 pagesEffectuez Des Plongements de Mots Word EmbeddingspayPas encore d'évaluation
- L'enseignement Des Langues de Spécialité Comme Préparation À La Traduction SpécialiséeDocument15 pagesL'enseignement Des Langues de Spécialité Comme Préparation À La Traduction SpécialiséeEl OuafaaPas encore d'évaluation
- ADD Chapitre 2-1Document10 pagesADD Chapitre 2-1Irch NgoubiliPas encore d'évaluation
- Matrice TDM Viz Clust IramuteqDocument31 pagesMatrice TDM Viz Clust Iramuteqsondos khammeriPas encore d'évaluation
- Cours - Comparaison Des SuitesDocument11 pagesCours - Comparaison Des SuitesamenzouPas encore d'évaluation
- 2 Fiche M Mo 6 Vecteurs Partie 1Document2 pages2 Fiche M Mo 6 Vecteurs Partie 1noellielelasseuxPas encore d'évaluation
- Cours - Relations BinairesDocument5 pagesCours - Relations Binairesjuniorcharlesnion859Pas encore d'évaluation
- Diapo2 RI PDFDocument61 pagesDiapo2 RI PDFmePas encore d'évaluation
- C5 - Les Base de lIADocument44 pagesC5 - Les Base de lIAAmeni BoughanmiPas encore d'évaluation
- Calcul VectorielDocument3 pagesCalcul VectoriellauraPas encore d'évaluation
- AlgorithmDocument52 pagesAlgorithmAnonymous rfHrcLaIPas encore d'évaluation
- Chapitre 1 Les Nombres ReelsDocument74 pagesChapitre 1 Les Nombres ReelsRayan Nouibet (Btray05)Pas encore d'évaluation
- Chap4 Mod Bool VectDocument43 pagesChap4 Mod Bool VectBen SalaouPas encore d'évaluation
- HAX501X - Groupes Et Anneaux 1 CM2 08/09/2023: CL Ement DupontDocument36 pagesHAX501X - Groupes Et Anneaux 1 CM2 08/09/2023: CL Ement Dupontlogement31Pas encore d'évaluation
- Quelques ApplicationsDocument8 pagesQuelques ApplicationsIlham TimadjerPas encore d'évaluation
- 101 Savoirs-Savoir FaireDocument10 pages101 Savoirs-Savoir FaireThomas DronnePas encore d'évaluation
- 2 - Plan Incliné-1Document27 pages2 - Plan Incliné-1Tat pqtPas encore d'évaluation
- 2021-2022 Taln CiDocument4 pages2021-2022 Taln Cifatmazohra rezkellahPas encore d'évaluation
- C4 Programmation Par ContraintesDocument36 pagesC4 Programmation Par ContraintesAmeni BoughanmiPas encore d'évaluation
- Transformation linéaire directe: Applications et techniques pratiques en vision par ordinateurD'EverandTransformation linéaire directe: Applications et techniques pratiques en vision par ordinateurPas encore d'évaluation
- Chapitre1 - Réseaux de Neurones - ComplémentsDocument9 pagesChapitre1 - Réseaux de Neurones - ComplémentsChaymae DkhissiPas encore d'évaluation
- Chapitre1 - Réseaux de NeuronesDocument35 pagesChapitre1 - Réseaux de NeuronesChaymae DkhissiPas encore d'évaluation
- Diagramme de SéquenceDocument34 pagesDiagramme de SéquenceChaymae DkhissiPas encore d'évaluation
- Compilation ExamsDocument34 pagesCompilation ExamsChaymae DkhissiPas encore d'évaluation
- Diagramme D'objetDocument16 pagesDiagramme D'objetChaymae DkhissiPas encore d'évaluation
- Compilation Kerkour Elmiad 2021-2022Document124 pagesCompilation Kerkour Elmiad 2021-2022Chaymae DkhissiPas encore d'évaluation
- ReseauxDocument265 pagesReseauxChaymae DkhissiPas encore d'évaluation
- Cours GloutonDocument10 pagesCours GloutonChaymae DkhissiPas encore d'évaluation
- GHCDocument37 pagesGHCChaymae DkhissiPas encore d'évaluation
- PCFG 1Document51 pagesPCFG 1Chaymae DkhissiPas encore d'évaluation
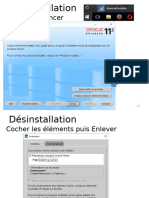
- DeinstallDocument5 pagesDeinstallChaymae DkhissiPas encore d'évaluation
- ComplexiteDocument144 pagesComplexiteChaymae DkhissiPas encore d'évaluation
- CreatedbDocument15 pagesCreatedbChaymae DkhissiPas encore d'évaluation
- PfileDocument11 pagesPfileChaymae DkhissiPas encore d'évaluation
- Condensateur Exercices Corrigés 04Document9 pagesCondensateur Exercices Corrigés 04Hamid OUTZGUINRIMTPas encore d'évaluation
- TD5 2022Document2 pagesTD5 2022Ourad CozartPas encore d'évaluation
- ExercicesDocument7 pagesExercicesTasnim amdouniPas encore d'évaluation
- Physique Chimie Extrait CorrigeDocument4 pagesPhysique Chimie Extrait Corrigetanguy bonnaudPas encore d'évaluation
- Listedescandidatsconvoqusauxpreuvescrites Techniciens 3 EMEGRADDocument24 pagesListedescandidatsconvoqusauxpreuvescrites Techniciens 3 EMEGRADpopoPas encore d'évaluation
- Merged (1) 2Document72 pagesMerged (1) 2DAP creatPas encore d'évaluation
- Boumaiza AbderraoufDocument92 pagesBoumaiza AbderraoufsetekanPas encore d'évaluation
- Devoir de Contrôle N°1 - Math - 3ème Sciences Exp (2020-2021) MR Assidi NasrDocument3 pagesDevoir de Contrôle N°1 - Math - 3ème Sciences Exp (2020-2021) MR Assidi Nasrsarra jouiliPas encore d'évaluation
- Anabolic Mass Gainer - GalsenfitDocument1 pageAnabolic Mass Gainer - GalsenfitOusmane DialloPas encore d'évaluation
- Dim PEADocument29 pagesDim PEADjouweinannodji YvesPas encore d'évaluation
- TSP2SP1Ch18T4-Corrige p478n6 n7Document1 pageTSP2SP1Ch18T4-Corrige p478n6 n7Rafael CastilloPas encore d'évaluation
- SysML. Applications Et TDDocument13 pagesSysML. Applications Et TDhangryPas encore d'évaluation
- ContreventementetLongrines PDFDocument52 pagesContreventementetLongrines PDFWissal gandouziPas encore d'évaluation
- La30bvibrations0607pdf PDF FreeDocument51 pagesLa30bvibrations0607pdf PDF FreeAdel AdenanePas encore d'évaluation
- 201801chimie MP PT Hachette PDFDocument260 pages201801chimie MP PT Hachette PDFRawda KhPas encore d'évaluation
- 2nd - 4. Puissances, Racine Carrée - CoursDocument3 pages2nd - 4. Puissances, Racine Carrée - Coursmax.levyPas encore d'évaluation
- Ateliers Manip Maths - PubDocument6 pagesAteliers Manip Maths - PubBERNARDPas encore d'évaluation
- Chapitre 1Document8 pagesChapitre 1LOUNDOU orthegaPas encore d'évaluation
- Algorithmique Avancée TP3 - Arbres Binaires de Recherche: 1 Représentation D'un NoeudDocument5 pagesAlgorithmique Avancée TP3 - Arbres Binaires de Recherche: 1 Représentation D'un Noeudy0ussef93シPas encore d'évaluation
- Exercices BarycentreDocument6 pagesExercices Barycentreamos djobzina djobzinaPas encore d'évaluation
- 03 Utilisation Des BD (SQL DDL)Document34 pages03 Utilisation Des BD (SQL DDL)echonozPas encore d'évaluation
- Reussir Concours Ecoles de CommerceDocument26 pagesReussir Concours Ecoles de CommerceThomas MakhloufPas encore d'évaluation
- 1 Présentation Calcul de Base Masse Et Centrage PDFDocument91 pages1 Présentation Calcul de Base Masse Et Centrage PDFDong Hai Nguyen100% (2)
- Dépôts Chimiques À Partir D'une Phase GazeuseDocument13 pagesDépôts Chimiques À Partir D'une Phase GazeuseOualidPas encore d'évaluation
- Examen-SW 21-22Document9 pagesExamen-SW 21-22Med Nour Elhak JouiniPas encore d'évaluation
- 01 Ctrle 17 10 2019 CorrectionDocument3 pages01 Ctrle 17 10 2019 Correctionraseldjebel75Pas encore d'évaluation
- ST2 Thermodynamique GourariDocument38 pagesST2 Thermodynamique GouraritthPas encore d'évaluation
- DS V4infobDocument6 pagesDS V4infobAbderrahim FatnassiPas encore d'évaluation
- TD - Thermo CorDocument4 pagesTD - Thermo CordalyyyamaraPas encore d'évaluation
- PhylogénieDocument22 pagesPhylogénieBeteapoilsPas encore d'évaluation