Vous aimerez peut-être aussi
- Inequation Et SystemeDocument8 pagesInequation Et SystemeMame serigne DiopPas encore d'évaluation
- Corrige Examen Stat Proba 21-22-1Document6 pagesCorrige Examen Stat Proba 21-22-1Ashraf MenchPas encore d'évaluation
- Minu Exetat 2023 Technique ADocument2 pagesMinu Exetat 2023 Technique AtshisuakacherubinPas encore d'évaluation
- Percept RonDocument33 pagesPercept RonJoël MentierePas encore d'évaluation
- 4e en 3e-Maths-Été19Document9 pages4e en 3e-Maths-Été19naglaaPas encore d'évaluation
- Cor Pro D 2006 PDFDocument10 pagesCor Pro D 2006 PDFfabricelPas encore d'évaluation
- Corrige Type - td7 2122Document5 pagesCorrige Type - td7 2122LoudjeinePas encore d'évaluation
- Practico # 3Document12 pagesPractico # 3Jamu Moreno UrquidiPas encore d'évaluation
- TD1, MatricesDocument3 pagesTD1, MatricesHedi cherifPas encore d'évaluation
- TD Algebre Lineaire Geologie-ITTGODocument2 pagesTD Algebre Lineaire Geologie-ITTGOOuedraogo HassanePas encore d'évaluation
- 01 DM 2 Matrice CorrigeDocument3 pages01 DM 2 Matrice CorrigeBint WooPas encore d'évaluation
- Agro td5Document14 pagesAgro td5Elvis Wilfried PossiPas encore d'évaluation
- Remédiation F1Document2 pagesRemédiation F1jordanxvierPas encore d'évaluation
- TP N 01 (Plan Dexpériences) SolutionDocument5 pagesTP N 01 (Plan Dexpériences) SolutionNak awad100% (1)
- Fasicule TP Modélisatio-SimulationDocument19 pagesFasicule TP Modélisatio-SimulationMohamed Ghassen BoudrigaPas encore d'évaluation
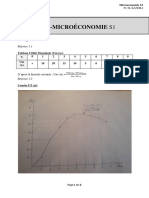
- TD n°1-MicroéconomieS1-CorrigéDocument6 pagesTD n°1-MicroéconomieS1-CorrigéChoaib MounjimPas encore d'évaluation
- 2sex Exponentielle Exe CorrDocument15 pages2sex Exponentielle Exe CorrsabbarPas encore d'évaluation
- Tddic 1 GCDocument2 pagesTddic 1 GCEl Hadj Abdoulaye SECKu.Pas encore d'évaluation
- Chap 10 - Ex 2 - Coefficient Directeur Et Vecteurs Directeurs - CORRIGEDocument3 pagesChap 10 - Ex 2 - Coefficient Directeur Et Vecteurs Directeurs - CORRIGEESSONNI SaadPas encore d'évaluation
- Examen TIM 2018-2019Document2 pagesExamen TIM 2018-2019aya gramiPas encore d'évaluation
- Plan D'expériences - Corrigé Fiche TD2Document10 pagesPlan D'expériences - Corrigé Fiche TD2Mohamed EL Amine100% (1)
- Econométrie Master GIE DevoirDocument3 pagesEconométrie Master GIE Devoirlamia lebharPas encore d'évaluation
- DS7 ch9 Fonctions Usuelles CorrDocument1 pageDS7 ch9 Fonctions Usuelles CorranissaPas encore d'évaluation
- Corr G Civil M2 Geostat S3 2022Document2 pagesCorr G Civil M2 Geostat S3 2022laich_mustaPas encore d'évaluation
- Correction Exercices Fonctions UsuellesDocument5 pagesCorrection Exercices Fonctions UsuellesJeannine Dibonga moukekePas encore d'évaluation
- Devoir 5emeDocument3 pagesDevoir 5emebuggsy kraPas encore d'évaluation
- Les Nombres RéelsDocument2 pagesLes Nombres Réelsimihi_hamidPas encore d'évaluation
- Exo Math22 2014 A5Document24 pagesExo Math22 2014 A5Abdallah GrimaPas encore d'évaluation
- Fonctions Exponentielles Corrige Serie D Exercices 1Document13 pagesFonctions Exponentielles Corrige Serie D Exercices 1younes boudounitPas encore d'évaluation
- Devoir de Synthèse N°2 - Math - 2ème Lettres (2010-2011) Mme GUESMIA AzizaDocument3 pagesDevoir de Synthèse N°2 - Math - 2ème Lettres (2010-2011) Mme GUESMIA AzizaKency Kelly JackPas encore d'évaluation
- FT9 PotenciasDocument5 pagesFT9 PotenciasJosé da CostaPas encore d'évaluation
- TD9RegCor PDFDocument2 pagesTD9RegCor PDFAmine Hafidi100% (1)
- Corrige Premiere STMG 6 2020Document4 pagesCorrige Premiere STMG 6 2020Mohammed SalamPas encore d'évaluation
- Statistique Descriptive TDDocument6 pagesStatistique Descriptive TDLesly MengaPas encore d'évaluation
- Ficha de Exercícios - TrigonometriaDocument2 pagesFicha de Exercícios - TrigonometriaLauro Da SilvaPas encore d'évaluation
- Serie TD2 Stat-Math 2021Document3 pagesSerie TD2 Stat-Math 2021F4S - محمدPas encore d'évaluation
- Exam-AN-juillet 16 CorrigéDocument3 pagesExam-AN-juillet 16 CorrigéAbderrahmane100% (1)
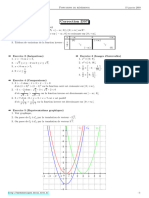
- Livre Du Professeur - Chapitre 2 - Nombres Complexes, Point de Vue Ge Üome ÜtriqueDocument87 pagesLivre Du Professeur - Chapitre 2 - Nombres Complexes, Point de Vue Ge Üome Ütriqueelise frouardPas encore d'évaluation
- TD0 ALgebre ExercicesDocument2 pagesTD0 ALgebre Exercicesbelinda kristaPas encore d'évaluation
- DEVOIRDocument11 pagesDEVOIRSouhaila LaghribPas encore d'évaluation
- Teste 3 2p 8ano 2022 2023 CLBDocument2 pagesTeste 3 2p 8ano 2022 2023 CLBPedro SimoesPas encore d'évaluation
- Formule de Calcul PrescurtatDocument5 pagesFormule de Calcul PrescurtatConcursEuclid AlbaPas encore d'évaluation
- Solution Exercice SDocument13 pagesSolution Exercice SivarkouadjeuPas encore d'évaluation
- Epac/si2/2022 2023Document3 pagesEpac/si2/2022 2023Allglory ADSPas encore d'évaluation
- Td2sii 2024Document2 pagesTd2sii 2024hiba ben nasrPas encore d'évaluation
- TD FC2 2023-2024Document4 pagesTD FC2 2023-2024hossein kouahiPas encore d'évaluation
- Hyp Exp LDP CompletDocument244 pagesHyp Exp LDP CompletTrinity Valent1Pas encore d'évaluation
- Fonctions Exponentielles: Exercices D'applications Et de Réflexions Avec SolutionsDocument15 pagesFonctions Exponentielles: Exercices D'applications Et de Réflexions Avec SolutionsYounes MountassirPas encore d'évaluation
- Chapitre 2 Criteres Statistiques2013 - CopieDocument26 pagesChapitre 2 Criteres Statistiques2013 - CopieOuzeren AbdelhakimPas encore d'évaluation
- Exercices CongruencesDocument3 pagesExercices CongruencesMehdi KhPas encore d'évaluation
- T D Algà Bre2 21 - 22 IUSTDocument4 pagesT D Algà Bre2 21 - 22 IUSThiyaxi3119Pas encore d'évaluation
- Examen Principal Eco 2019-2020Document4 pagesExamen Principal Eco 2019-2020Mariem FourtiPas encore d'évaluation
- Poser Operation 1 CorrigeDocument4 pagesPoser Operation 1 Corrigeboubacarmballo205Pas encore d'évaluation
- Feuille 3Document6 pagesFeuille 3Nakodja BadjelPas encore d'évaluation
- Solution-TD1 Méthode NumériqueDocument3 pagesSolution-TD1 Méthode NumériqueJean Oscar BadoPas encore d'évaluation
- CMN CorrigéDocument2 pagesCMN CorrigéNowe AhmadePas encore d'évaluation
- Numerical Methods in Engineering With Matlab 3rd Kiusalaas Solution ManualDocument24 pagesNumerical Methods in Engineering With Matlab 3rd Kiusalaas Solution ManualMaryHowardcwzan100% (29)
- TP N°3 OPM SolutionDocument2 pagesTP N°3 OPM SolutionGaya MhbPas encore d'évaluation
- Corrigé Spécialité Génie Meca STIDD GP1 2022Document5 pagesCorrigé Spécialité Génie Meca STIDD GP1 2022kara baPas encore d'évaluation
- Feuille Technique: Vitogas 050Document24 pagesFeuille Technique: Vitogas 050Oi69qEZPas encore d'évaluation
- TD Electronique AnalogiqueDocument8 pagesTD Electronique AnalogiqueFreight FreightoPas encore d'évaluation
- Commande-Publique Referentiel 2021-01 V1defDocument41 pagesCommande-Publique Referentiel 2021-01 V1deflecouveyPas encore d'évaluation
- Processus UnifiéDocument10 pagesProcessus UnifiéGaSton MazrouiPas encore d'évaluation
- Caténaire Et Fils de ContactDocument12 pagesCaténaire Et Fils de ContactMhammedPas encore d'évaluation
- Rapport ToopooDocument10 pagesRapport Toopooazzhamza605Pas encore d'évaluation
- WCM Questions and AnswersDocument26 pagesWCM Questions and Answersameer meerPas encore d'évaluation
- Plan de Montage Du Contrepoids - Stacker L21ST01 - Cbmi - 20122022 PDFDocument6 pagesPlan de Montage Du Contrepoids - Stacker L21ST01 - Cbmi - 20122022 PDFHa Kim BJPas encore d'évaluation
- IntroductioN Au Système GNU PDFDocument37 pagesIntroductioN Au Système GNU PDFSteve Loïc NGANDAPas encore d'évaluation
- CV 2abderrahim YAHYAOUI PDFDocument1 pageCV 2abderrahim YAHYAOUI PDFhaltreiz SarutobiiPas encore d'évaluation
- Cours AcpDocument18 pagesCours AcpHochi MimiPas encore d'évaluation
- Chap 2Document15 pagesChap 2benjunior ahmedPas encore d'évaluation
- CH MemoiresDocument71 pagesCH MemoiresN El kechaiPas encore d'évaluation
- Tchaikovsky 5 II Horn Solo - Score and PartsDocument9 pagesTchaikovsky 5 II Horn Solo - Score and PartsAlisson PedrosoPas encore d'évaluation
- Fiche EnseignantDocument4 pagesFiche EnseignantWulfaPas encore d'évaluation
- Abc P57 PDFDocument130 pagesAbc P57 PDFOthmane SettariPas encore d'évaluation
- Description Temporelle D'un Système Technique Par L'outil GRAFCETDocument16 pagesDescription Temporelle D'un Système Technique Par L'outil GRAFCETSsantrino OnirtnassPas encore d'évaluation
- tp1 PersistanceDocument3 pagestp1 PersistancenaasPas encore d'évaluation
- Un Diagramme de Gantt Excel GRATUIT AutomatiqueDocument4 pagesUn Diagramme de Gantt Excel GRATUIT AutomatiqueKenwolfPas encore d'évaluation
- ÉconométrieDocument24 pagesÉconométrieNicolas KiadivilaPas encore d'évaluation
- Thèse de DoctoratDocument134 pagesThèse de DoctoratKada BenhamidiPas encore d'évaluation
- Cours Photoshop Avancé 2022Document1 pageCours Photoshop Avancé 2022Dnc Services100% (1)
- Mode D'emploi D'une Étape: Temps LibreDocument1 pageMode D'emploi D'une Étape: Temps LibreOne Third Consulting AbroadPas encore d'évaluation
- TP-production D'eau ChaudeDocument15 pagesTP-production D'eau ChaudeFatna BelabbesPas encore d'évaluation
- TP Fouotsap Et Pesdjock ProfesseurDocument16 pagesTP Fouotsap Et Pesdjock ProfesseurBoris FouotsapPas encore d'évaluation
- Les Déterminants de La Compétitivité de L'entrepriseDocument27 pagesLes Déterminants de La Compétitivité de L'entrepriseDôn PhạmPas encore d'évaluation
- Se chp3 Gestionmemoire 170207132616Document44 pagesSe chp3 Gestionmemoire 170207132616Med Aref100% (1)
- Contrat ENGIEDocument5 pagesContrat ENGIEbiardPas encore d'évaluation
- Corrigé Analyse de Fabrication PF1 2019Document6 pagesCorrigé Analyse de Fabrication PF1 2019Dayang Dayang100% (4)