Vous aimerez peut-être aussi
- Équations différentielles: Les Grands Articles d'UniversalisD'EverandÉquations différentielles: Les Grands Articles d'UniversalisPas encore d'évaluation
- Techniques de Calcul de L'exponentiel D'une MatriceDocument9 pagesTechniques de Calcul de L'exponentiel D'une MatriceEssaidi Ali75% (8)
- Les Nombres PremiersDocument12 pagesLes Nombres PremiersKarl MalongaPas encore d'évaluation
- Leçons sur les séries trigonométriques : professées au Collège de FranceD'EverandLeçons sur les séries trigonométriques : professées au Collège de FrancePas encore d'évaluation
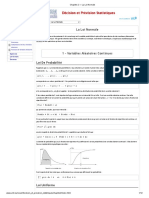
- Variables Aléatoires Et Lois de ProbabilitéDocument8 pagesVariables Aléatoires Et Lois de Probabilitésjaubert100% (3)
- Proba Chapitre4-MkiDocument7 pagesProba Chapitre4-MkisdfdgdPas encore d'évaluation
- Annexe de ProbaDocument32 pagesAnnexe de Probasarajfr2003Pas encore d'évaluation
- ECO304 Support Seance 5Document5 pagesECO304 Support Seance 5iwaf dorPas encore d'évaluation
- Chap4 Variable Aléatoire Continue-1Document8 pagesChap4 Variable Aléatoire Continue-1NajlaealalawiPas encore d'évaluation
- Les Lois ProbabilitéDocument27 pagesLes Lois Probabilitéhananaharchi19Pas encore d'évaluation
- ITI3 - RAN - Probas - 3 (1) Cours ZwiiinDocument4 pagesITI3 - RAN - Probas - 3 (1) Cours Zwiiinsalma abaraghiPas encore d'évaluation
- L'Exemple de La Loi Normale.Document6 pagesL'Exemple de La Loi Normale.rachid.ensecPas encore d'évaluation
- ResumeVAetLois 10Document1 pageResumeVAetLois 10Wadii SGPas encore d'évaluation
- Chap3 ProbaDocument10 pagesChap3 ProbaOumaima FakhrPas encore d'évaluation
- Exos Variables A DensiteDocument10 pagesExos Variables A DensiteAndronet TechniquePas encore d'évaluation
- ProbasEnsai MagalieDocument34 pagesProbasEnsai Magaliekukis14Pas encore d'évaluation
- Conducteur 1Document20 pagesConducteur 1RisalaPas encore d'évaluation
- Cvaraleatoire2122 p1p2 PetudDocument7 pagesCvaraleatoire2122 p1p2 Petudabir taamallahPas encore d'évaluation
- Cours Variables Aleatoires ContinuesDocument10 pagesCours Variables Aleatoires ContinuesPablo EscobarPas encore d'évaluation
- Calcul Des Probabiltés (Chapitre3) - PolyDocument51 pagesCalcul Des Probabiltés (Chapitre3) - Polybernardino monayongPas encore d'évaluation
- ResumeVAetLois 10Document2 pagesResumeVAetLois 10Douraid DridiPas encore d'évaluation
- Résumé Chapitre 1Document2 pagesRésumé Chapitre 1Essyl SAIDIPas encore d'évaluation
- UntitledDocument7 pagesUntitledZ CoulPas encore d'évaluation
- CH5 Vac Et Loi PresDocument30 pagesCH5 Vac Et Loi Preschaimaeelhmami20Pas encore d'évaluation
- Agreg TD EsperanceDocument4 pagesAgreg TD Esperancechristbest682Pas encore d'évaluation
- Math504 Chap3Document8 pagesMath504 Chap3Réda Ait HammouPas encore d'évaluation
- Cours Probabilites Lois ContinuesDocument12 pagesCours Probabilites Lois ContinuesJEAN JOSUE RAKOTOARIMANANAPas encore d'évaluation
- Cogmaster Probas ContinuesDocument136 pagesCogmaster Probas ContinuesColmain NassiriPas encore d'évaluation
- Chapitre 3Document15 pagesChapitre 3Döūãe OđPas encore d'évaluation
- Resume Var DiscretesDocument2 pagesResume Var DiscretesSaid JoariPas encore d'évaluation
- Chapitre 0-Rappels Des ProbabilitésDocument6 pagesChapitre 0-Rappels Des ProbabilitésWael KsilaPas encore d'évaluation
- Variables Aleatoires - MedecineDocument10 pagesVariables Aleatoires - MedecineSalif OUEDRAOGOPas encore d'évaluation
- Chapitre 3Document11 pagesChapitre 3Murchy NtselePas encore d'évaluation
- Chap 1 MF 1 2020 2021Document8 pagesChap 1 MF 1 2020 2021Black StarPas encore d'évaluation
- Rappel ProbabilitéDocument6 pagesRappel ProbabilitéBlgPas encore d'évaluation
- Poly - Probabilites-Seance 2pdfDocument12 pagesPoly - Probabilites-Seance 2pdfKADDAMI SaousanPas encore d'évaluation
- Probabilités. CH2 - S2 (Pr. Boulmane)Document10 pagesProbabilités. CH2 - S2 (Pr. Boulmane)Isma elPas encore d'évaluation
- KH 12 VadensiteDocument16 pagesKH 12 Vadensitekukis14Pas encore d'évaluation
- Cours Des V A R TTLDocument18 pagesCours Des V A R TTLbriki ayoubPas encore d'évaluation
- Chapitre5 ECG2Document17 pagesChapitre5 ECG2motivation31102001Pas encore d'évaluation
- Loi de Probabilité Continue - Cours ÉlèvesDocument7 pagesLoi de Probabilité Continue - Cours ÉlèvesMolinier MélaniePas encore d'évaluation
- Variables Aleatoires GenDocument11 pagesVariables Aleatoires Genpape saliou wadePas encore d'évaluation
- Chapitre 2 - La Loi NormaleDocument12 pagesChapitre 2 - La Loi NormaleGnamadio Yves Eugène SékongoPas encore d'évaluation
- Chapitre 5 Variables Aléatoires: 5.1 Définitions Et PropriétésDocument13 pagesChapitre 5 Variables Aléatoires: 5.1 Définitions Et PropriétésMeriem AIT AHMED OABDPas encore d'évaluation
- ProbaDocument6 pagesProbaAmal BãPas encore d'évaluation
- Chapitre 3Document23 pagesChapitre 3OusswaPas encore d'évaluation
- TD Proba CorrectionDocument44 pagesTD Proba CorrectionLerrys Obiang100% (1)
- CoursTD2 2Document23 pagesCoursTD2 2pcsi babsahraPas encore d'évaluation
- I w ∈ Ω/ X w: Chapitre 2: Lois De Probabilite DiscretesDocument7 pagesI w ∈ Ω/ X w: Chapitre 2: Lois De Probabilite DiscretesZ CoulPas encore d'évaluation
- Econometrie Finance Slides Partie2Document6 pagesEconometrie Finance Slides Partie2exemple exPas encore d'évaluation
- FONCTIONDocument23 pagesFONCTIONDAHRAOUI Mohamed RiadPas encore d'évaluation
- Variables AléatoiresDocument17 pagesVariables Aléatoireslili edouardPas encore d'évaluation
- Cour 3Document8 pagesCour 3NininePas encore d'évaluation
- Chapitre3 PROBA1-2022 2023Document11 pagesChapitre3 PROBA1-2022 2023hibaPas encore d'évaluation
- Ch3 ProbaDocument30 pagesCh3 ProbaAchraf FadelPas encore d'évaluation
- Lois UsuellesDocument4 pagesLois UsuellesEyaPas encore d'évaluation
- F ConvexesDocument4 pagesF ConvexesNOUREDDINE OUSAIDPas encore d'évaluation
- Math Matiques Pour ConomistesDocument2 pagesMath Matiques Pour ConomistesOussama NaouiPas encore d'évaluation
- SupportProbabilite Chap 2Document16 pagesSupportProbabilite Chap 2Döūãe OđPas encore d'évaluation
- Chapitre1 ReprésentationDocument61 pagesChapitre1 ReprésentationgharbiaPas encore d'évaluation
- Devoir SDocument7 pagesDevoir SALI MESSAOUD HanaPas encore d'évaluation
- Thermodynamique II Examens Corr 06Document7 pagesThermodynamique II Examens Corr 06ayoub dahbiPas encore d'évaluation
- DS04 SuitesDocument7 pagesDS04 SuitesRamanujan SrinivasaPas encore d'évaluation
- 1re STI2D Definition Produit ScalaireDocument9 pages1re STI2D Definition Produit ScalaireSarrPas encore d'évaluation
- Evaluation N°3 - Probas Cond Et Indép CorrectionDocument4 pagesEvaluation N°3 - Probas Cond Et Indép CorrectionYass LrbPas encore d'évaluation
- F1 F2 F3Document4 pagesF1 F2 F3Kathirasan Ramalingam0% (2)
- Chapitre 2: Transformée en Z D'un Signal ÉchantillonnéDocument8 pagesChapitre 2: Transformée en Z D'un Signal ÉchantillonnéAhmed Free100% (1)
- AnalyseDocument9 pagesAnalyseKamal ElamraouiPas encore d'évaluation
- Corrige CHAP5Document14 pagesCorrige CHAP5techmohPas encore d'évaluation
- CR tp3Document7 pagesCR tp3Maroua SederPas encore d'évaluation
- Chap - 01 - Généralités sur la commande numérique-١Document45 pagesChap - 01 - Généralités sur la commande numérique-١Toutou KHATRIPas encore d'évaluation
- Voirie Et Réseau Divers (V.R.D) : I. Rappels MathématiqueDocument4 pagesVoirie Et Réseau Divers (V.R.D) : I. Rappels MathématiqueAchraf BenhadjPas encore d'évaluation
- Chapitre 4 Choix Dinnvestissement Dans Un Avenir IncertainDocument22 pagesChapitre 4 Choix Dinnvestissement Dans Un Avenir IncertainArab AlaouiPas encore d'évaluation
- P3-4-Conducteurs en Equilibre ElectrostatiqueDocument17 pagesP3-4-Conducteurs en Equilibre ElectrostatiquesoumiaPas encore d'évaluation
- Exo Tech 18Document2 pagesExo Tech 18Théo AngamaPas encore d'évaluation
- CH 1 Nombres ComplexesDocument18 pagesCH 1 Nombres ComplexesCharle StonksPas encore d'évaluation
- Analyse FactorielleDocument30 pagesAnalyse FactorielleZakaria KadiriPas encore d'évaluation
- Champ de Gibbs-Markov Sur RéseauDocument4 pagesChamp de Gibbs-Markov Sur RéseauAnonymous Tph9x741Pas encore d'évaluation
- Support Etudiants 3Document14 pagesSupport Etudiants 3sambe.elPas encore d'évaluation
- Examen NationnalDocument4 pagesExamen NationnalCatuk EllaPas encore d'évaluation
- Cours de Codage de L'information1Document16 pagesCours de Codage de L'information1Massa DickoPas encore d'évaluation
- Maths Disc 1 Sabrina OuazzaniDocument56 pagesMaths Disc 1 Sabrina OuazzaniPayet angelaPas encore d'évaluation
- Le Chainon Deductif: en Mathématique Tout Énoncé Peut-Être Vrai Ou Faux !Document34 pagesLe Chainon Deductif: en Mathématique Tout Énoncé Peut-Être Vrai Ou Faux !Bou NajPas encore d'évaluation
- RAHMANI Magister PDFDocument192 pagesRAHMANI Magister PDFWalidBenHamidouchePas encore d'évaluation
- TD Fonction LimitesDocument27 pagesTD Fonction LimitesIbrahim HARBPas encore d'évaluation
- 04 Cours Algorithme NewtonDocument4 pages04 Cours Algorithme NewtonminouchPas encore d'évaluation
- Quelques Méthodes de Résolution Des Problèmes Aux Limites Non LinéairesDocument7 pagesQuelques Méthodes de Résolution Des Problèmes Aux Limites Non LinéairesFaresdzb100% (1)
- Operations Sur Les Nombres en Ecriture FractionnaireDocument6 pagesOperations Sur Les Nombres en Ecriture FractionnaireAlae dine GamerPas encore d'évaluation
- Serie N°2Document4 pagesSerie N°2Rafik SaadaPas encore d'évaluation