Vous aimerez peut-être aussi
- Introduction SSISDocument13 pagesIntroduction SSISWafa HammamiPas encore d'évaluation
- Projet BIDocument22 pagesProjet BIHamza AbdollahPas encore d'évaluation
- Business Intelligence Ou Informatique DécisionnelleDocument7 pagesBusiness Intelligence Ou Informatique DécisionnelleHanen BouajajaPas encore d'évaluation
- Nouveau Document TexteDocument1 pageNouveau Document Texteporino7441Pas encore d'évaluation
- Support Cours Introduction BI Partie I Et IIDocument24 pagesSupport Cours Introduction BI Partie I Et IIEl Bachir AliPas encore d'évaluation
- Guide Bi Tableaux de Bord AnalysesDocument89 pagesGuide Bi Tableaux de Bord Analysesvaltech20086605100% (2)
- BI Brochure Microsoft Business IntelligenceDocument11 pagesBI Brochure Microsoft Business IntelligencejlkazadiPas encore d'évaluation
- LA BI en Mode SaaSDocument41 pagesLA BI en Mode SaaSmatrixleblancPas encore d'évaluation
- Les Fonctionnalités de La BIDocument6 pagesLes Fonctionnalités de La BIWissam MosPas encore d'évaluation
- Prise de NotesDocument4 pagesPrise de NotesBAHPas encore d'évaluation
- VSST 2007Document12 pagesVSST 2007usthbmilsdedPas encore d'évaluation
- Avantages BiDocument7 pagesAvantages BimariaPas encore d'évaluation
- Data Warehouse 3Document30 pagesData Warehouse 3Abbes RharrabPas encore d'évaluation
- Modélisation MultidimensionnelleDocument117 pagesModélisation Multidimensionnellemaison.tajeddinePas encore d'évaluation
- La Business IntelligenceDocument11 pagesLa Business IntelligencebadrouPas encore d'évaluation
- Informatique DécisionnelleDocument7 pagesInformatique DécisionnellenounightPas encore d'évaluation
- Rapport Power BIDocument33 pagesRapport Power BIMouna Rachid100% (2)
- Un Entrepôt de DonnéesDocument10 pagesUn Entrepôt de DonnéesLionelIrambonaPas encore d'évaluation
- Modélisation MultidimensionnelleDocument117 pagesModélisation Multidimensionnelleelilalik100% (2)
- Architecture BIDocument64 pagesArchitecture BImaison.tajeddinePas encore d'évaluation
- PDFDocument12 pagesPDFHenri Eugene BitoulefockPas encore d'évaluation
- Thème 4 Présentation PPT Business IntelligenceDocument27 pagesThème 4 Présentation PPT Business IntelligenceZakaria El Goud100% (1)
- TestDocument8 pagesTestAbdoulkader OumarouPas encore d'évaluation
- Rapport de Stage Imen ZouaghiDocument12 pagesRapport de Stage Imen ZouaghiHfd NourPas encore d'évaluation
- Power BI2Document6 pagesPower BI2nabiPas encore d'évaluation
- BIDocument26 pagesBIOuhourou NA Kazi0% (1)
- TP 0 DWDocument5 pagesTP 0 DWHamza Benarbia100% (1)
- Slide Projet Si FNDocument14 pagesSlide Projet Si FNYakoub IshaghPas encore d'évaluation
- 1 - Généralités BIDocument35 pages1 - Généralités BIFATIMA ZAHRA ENAGREPas encore d'évaluation
- Cours BIDocument78 pagesCours BIfaxena3486Pas encore d'évaluation
- Business IntelligenceDocument89 pagesBusiness Intelligenceamine_lemagni100% (1)
- Leilclic 544Document15 pagesLeilclic 544Auguste Elvis OuattaraPas encore d'évaluation
- UntitledDocument2 pagesUntitledHamed N’DiayePas encore d'évaluation
- Bi Etl Ssis SSRS 01Document83 pagesBi Etl Ssis SSRS 01We DyPas encore d'évaluation
- Cour SI Dseg1 2021-2022 Première PartieDocument10 pagesCour SI Dseg1 2021-2022 Première Partiekhardiata diattaPas encore d'évaluation
- Projet SID&DMDocument153 pagesProjet SID&DMOumima KhPas encore d'évaluation
- Chapitre 1Document43 pagesChapitre 1ABBES Nour-ElHoudaPas encore d'évaluation
- Data WarehouseDocument13 pagesData WarehouseIlyes BoukPas encore d'évaluation
- Modelisation D'un Système D'information Fichier N°1Document38 pagesModelisation D'un Système D'information Fichier N°1Magnamé BARADJIPas encore d'évaluation
- Cours Chap1Document23 pagesCours Chap1olfa jabriPas encore d'évaluation
- Partie Theorique BIDocument7 pagesPartie Theorique BIMysticalPas encore d'évaluation
- Power BIDocument3 pagesPower BIGNANOU HABIBPas encore d'évaluation
- Power BI Training EISTIDocument60 pagesPower BI Training EISTIDimitri Tibati100% (1)
- Rapport de Projet ERPDocument37 pagesRapport de Projet ERPZeineb Ben Azzouz100% (1)
- Erp 2007 2008 Volume 4Document49 pagesErp 2007 2008 Volume 4Radouane LemghariPas encore d'évaluation
- Brochure Mini Master - BI & Data Analysis - Job SkillZDocument9 pagesBrochure Mini Master - BI & Data Analysis - Job SkillZslim yaichPas encore d'évaluation
- Application Mobile Du Projet SynapseDocument9 pagesApplication Mobile Du Projet Synapsebomij92028Pas encore d'évaluation
- CV Ul - BCLDocument5 pagesCV Ul - BCLCOUNDOUL BiramePas encore d'évaluation
- Cours BI2024etudiantDocument126 pagesCours BI2024etudiantolfa jabriPas encore d'évaluation
- Chapitre 2 Les Dimensions Organisationnelles Et Managériales Des SIDocument41 pagesChapitre 2 Les Dimensions Organisationnelles Et Managériales Des SIchaima smatiPas encore d'évaluation
- Aide de Microsoft Dynamics 365 Customer Engagement (On-Premises), Version 9Document15 pagesAide de Microsoft Dynamics 365 Customer Engagement (On-Premises), Version 9zakaria abbadiPas encore d'évaluation
- Gestion Configuration It CMDBDocument21 pagesGestion Configuration It CMDBzribi_supcomPas encore d'évaluation
- Ingénierie DécisionnelDocument2 pagesIngénierie DécisionnelHindelhadajPas encore d'évaluation
- Chap 2 DATAWAREHOUSEDocument16 pagesChap 2 DATAWAREHOUSEjeffrey jaroldPas encore d'évaluation
- Business Intelligence: Qu'est-Ce Que L'informatique Décisionnelle ?Document9 pagesBusiness Intelligence: Qu'est-Ce Que L'informatique Décisionnelle ?mariaPas encore d'évaluation
- Chapitre 2 - Analyse de L'existentDocument9 pagesChapitre 2 - Analyse de L'existentDaniel BisimwaPas encore d'évaluation
- 1 Explosion de Linformatique DecisionnelDocument53 pages1 Explosion de Linformatique DecisionnelMohamed ESSALBI100% (1)
- Introduction à l'informatique décisionnelle (business intelligence)D'EverandIntroduction à l'informatique décisionnelle (business intelligence)Pas encore d'évaluation
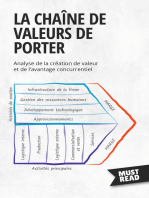
- La Chaîne De Valeurs De Porter: Analyse de la création de valeur et de l'avantage concurrentielD'EverandLa Chaîne De Valeurs De Porter: Analyse de la création de valeur et de l'avantage concurrentielPas encore d'évaluation
- InformationDocument1 pageInformationGNANOU HABIBPas encore d'évaluation
- LM345 TD10 1Document5 pagesLM345 TD10 1GNANOU HABIBPas encore d'évaluation
- SQL RemindDocument5 pagesSQL RemindGNANOU HABIBPas encore d'évaluation
- Power BIDocument3 pagesPower BIGNANOU HABIBPas encore d'évaluation
- Texte ECDocument1 pageTexte ECrauzierPas encore d'évaluation
- Khebbache Hicham PDFDocument154 pagesKhebbache Hicham PDFNoureddine GuersiPas encore d'évaluation
- PFE 2012 Sagemcom CatalogueDocument21 pagesPFE 2012 Sagemcom CatalogueKhalil AhmadiPas encore d'évaluation
- Bda2 Cours12 FR SlidesDocument27 pagesBda2 Cours12 FR SlidesAhmed Chaouki CHAOUCHEPas encore d'évaluation
- CurseursDocument4 pagesCurseursinfoderPas encore d'évaluation
- Exercices Assembleur M1 ELT ER Serie 2 Avec CorrigéDocument5 pagesExercices Assembleur M1 ELT ER Serie 2 Avec CorrigéAmir Na DzPas encore d'évaluation
- Recensement de La Faune Avec PDA (.AXF D'arcpadDocument73 pagesRecensement de La Faune Avec PDA (.AXF D'arcpadRachid SkoubassonPas encore d'évaluation
- Windows 7 - Le Mode D'emploi CompletDocument160 pagesWindows 7 - Le Mode D'emploi Completoswaldjosy619Pas encore d'évaluation
- Professeur Benzine Rachid Cours Optimisation Sans Contraintes Tome1 PDFDocument153 pagesProfesseur Benzine Rachid Cours Optimisation Sans Contraintes Tome1 PDFChemlal JalalPas encore d'évaluation
- Exposé Méthode AgileDocument10 pagesExposé Méthode AgileAlfred EbrottiePas encore d'évaluation
- Les Circuits Combinatoires Et SéquentielsDocument19 pagesLes Circuits Combinatoires Et SéquentielsADAMA HADJA ALIPas encore d'évaluation
- FP Module de Commande Wifi Access Thomson 520014 Maisonic 1641Document3 pagesFP Module de Commande Wifi Access Thomson 520014 Maisonic 1641Yassine DragãoPas encore d'évaluation
- Transformations Coordonnees GeodesiquesDocument16 pagesTransformations Coordonnees GeodesiquesAhmed EnnehriPas encore d'évaluation
- Cours Virtualisation Et Cloud Computing 2024Document66 pagesCours Virtualisation Et Cloud Computing 2024Issa hardaga abdelhackPas encore d'évaluation
- Socks 4 Proxy ListDocument75 pagesSocks 4 Proxy ListVibePas encore d'évaluation
- Réseaux Sans FilsDocument16 pagesRéseaux Sans FilsGhalia djerroudPas encore d'évaluation
- Cahors - Distribution Elec BT 2017 PDFDocument184 pagesCahors - Distribution Elec BT 2017 PDFMoulay m'hammed LOUKILIPas encore d'évaluation
- Senace 02Document13 pagesSenace 02medPas encore d'évaluation
- Note Cours Informatique Scientifique 2004Document60 pagesNote Cours Informatique Scientifique 2004Tahirindrainy Fanoela JeanPas encore d'évaluation
- DVR NextvisionDocument131 pagesDVR NextvisionPhilippe BlangenoisPas encore d'évaluation
- Procédure Récupération EBPDocument6 pagesProcédure Récupération EBPcarolinePas encore d'évaluation
- Poly TPDocument14 pagesPoly TPIma AutPas encore d'évaluation
- (Free Scores - Com) - Bogosh Noah Hope 29847 PDFDocument3 pages(Free Scores - Com) - Bogosh Noah Hope 29847 PDFEnrique RosasPas encore d'évaluation
- 1-Corbeille D'exercices TransmissionDocument2 pages1-Corbeille D'exercices TransmissionBoboy YOUSSAOU ISMAILAPas encore d'évaluation
- CFF - Horaire en LigneDocument2 pagesCFF - Horaire en Lignelyda15Pas encore d'évaluation
- TP Arduino N0Document11 pagesTP Arduino N0Amira Jebali100% (1)
- Exam-MEF - ENSMM-2015 PDFDocument10 pagesExam-MEF - ENSMM-2015 PDFاشراقةاملPas encore d'évaluation
- Examen de Fin de Formation 2015 Pratique Variante 8 TriDocument8 pagesExamen de Fin de Formation 2015 Pratique Variante 8 TriInnocent NdriPas encore d'évaluation
- Chi 5232Document156 pagesChi 5232MENANI ZineddinePas encore d'évaluation
- CryptoDocument836 pagesCryptoArnaud BizecPas encore d'évaluation