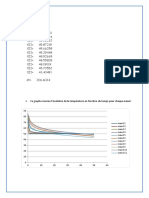
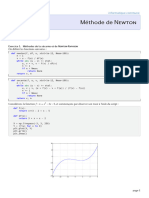
Vous aimerez peut-être aussi
- Pendule de Pohl (Réparé) .Docx Version 1Document16 pagesPendule de Pohl (Réparé) .Docx Version 1Mr AhmedPas encore d'évaluation
- Bulletin de Lille, 1916-03 Publié sous le contrôle de l'autorité allemandeD'EverandBulletin de Lille, 1916-03 Publié sous le contrôle de l'autorité allemandePas encore d'évaluation
- Cours6 Méthodes de PrévisionsDocument13 pagesCours6 Méthodes de PrévisionsSakù ExøTïc ØtāKůPas encore d'évaluation
- Devoir Corrigé de Contrôle N°3 - Sciences Physiques alcool+CNA+onde Progressive - Bac (2013-2014) MR ZGUED HICHEM PDFDocument6 pagesDevoir Corrigé de Contrôle N°3 - Sciences Physiques alcool+CNA+onde Progressive - Bac (2013-2014) MR ZGUED HICHEM PDFLotfi Bouchareb0% (1)
- TP 10 MultiplieurDocument4 pagesTP 10 MultiplieurNourallah AouinaPas encore d'évaluation
- Notes Econometrie PDFDocument39 pagesNotes Econometrie PDFBbaggi Bk100% (1)
- HA0805 CorrigeDocument4 pagesHA0805 Corrigesidiabdelli_83761508Pas encore d'évaluation
- TP N°03 de Phys Le Pendule de PohlDocument7 pagesTP N°03 de Phys Le Pendule de PohlWalid Matallah67% (12)
- TP MecaniqueDocument25 pagesTP Mecaniqueafaf.qadielidrissiPas encore d'évaluation
- TP MN La Puce Partie InstationnaireDocument9 pagesTP MN La Puce Partie InstationnaireILHEMPas encore d'évaluation
- CHAPITRE 1 Micro Ondes PDFDocument9 pagesCHAPITRE 1 Micro Ondes PDFUdei SchikhauiPas encore d'évaluation
- Compte Rendu TP 1 TSDocument10 pagesCompte Rendu TP 1 TSMohamed El Mehdi MEDDADPas encore d'évaluation
- Projet de TdsDocument16 pagesProjet de TdsRaymond BossonPas encore d'évaluation
- Serie Chro 1 Intro Determinsite PDFDocument54 pagesSerie Chro 1 Intro Determinsite PDFTina MariaPas encore d'évaluation
- 11.loi - Pearson III - Chouly - 17x24Document10 pages11.loi - Pearson III - Chouly - 17x24sidiabdelli_83761508Pas encore d'évaluation
- Compte Rendu TP2 PDFDocument14 pagesCompte Rendu TP2 PDFAbderrazak Abd0% (1)
- MTH0103 Calcul Integral 12 Ve Series Taylor MacLaurinDocument12 pagesMTH0103 Calcul Integral 12 Ve Series Taylor MacLaurinAzzam KamalPas encore d'évaluation
- TP 01Document8 pagesTP 01Hadil SellamiPas encore d'évaluation
- Corrigé TDTP1Document8 pagesCorrigé TDTP1Nowe AhmadePas encore d'évaluation
- Bac 78Document2 pagesBac 78Moussa KolyPas encore d'évaluation
- Le Pendule Tournant de PohlDocument11 pagesLe Pendule Tournant de PohlKacimo Odine100% (1)
- Exercise 3 - Logits Et Tables Types de MortaliteDocument3 pagesExercise 3 - Logits Et Tables Types de MortaliteRégis KroaPas encore d'évaluation
- Cours2 Tendance Composante SaisonniereDocument17 pagesCours2 Tendance Composante SaisonniereEco EnsemblePas encore d'évaluation
- Le Pendule Tournant de PohlDocument11 pagesLe Pendule Tournant de Pohlfati100% (1)
- Le modèle sinusoïdal:: = Asin (ωt +ϕ)Document6 pagesLe modèle sinusoïdal:: = Asin (ωt +ϕ)Piero CtPas encore d'évaluation
- MthedhgfghDocument15 pagesMthedhgfghBassem GhorbelPas encore d'évaluation
- Impulsion de DiracDocument17 pagesImpulsion de DiracOumarGarba100% (2)
- Controle (2017) ProbabilitéDocument1 pageControle (2017) ProbabilitéIssam AdochPas encore d'évaluation
- TP9 CorrigeDocument6 pagesTP9 CorrigeKhaled JberiPas encore d'évaluation
- Interpolation Par Fonctions SplinesDocument67 pagesInterpolation Par Fonctions SplinesbtkmouradPas encore d'évaluation
- Examen Signaux NumériqueDocument5 pagesExamen Signaux Numériquefazfrito lacaviataPas encore d'évaluation
- Serie 9 Calcul Approche D Une Integrale Methodes de Newton Cotes Methode de Romberg CorrigesDocument6 pagesSerie 9 Calcul Approche D Une Integrale Methodes de Newton Cotes Methode de Romberg CorrigesmissmaymounaPas encore d'évaluation
- Labo Excel 2Document11 pagesLabo Excel 2Léo FramboisePas encore d'évaluation
- Exercices Statistiques 2 VariablesDocument5 pagesExercices Statistiques 2 VariablesSebleberger RouffachPas encore d'évaluation
- Stats Proba 102011Document36 pagesStats Proba 102011Imane OuhadiPas encore d'évaluation
- Études Statique Et Dynamique Du Ressort: Safa Benelmekadem Safae Ouchen Adam Belabdi Ilyas Elasri Ousssama El AzoukiDocument7 pagesÉtudes Statique Et Dynamique Du Ressort: Safa Benelmekadem Safae Ouchen Adam Belabdi Ilyas Elasri Ousssama El Azoukimmm aaPas encore d'évaluation
- TP2 Signal CarréDocument4 pagesTP2 Signal Carrésafi edinPas encore d'évaluation
- A - Cuve À Ondes: Partie IDocument13 pagesA - Cuve À Ondes: Partie Ihedidbz38Pas encore d'évaluation
- Filtrage AnalogiqueDocument38 pagesFiltrage AnalogiqueMustapha El MetouiPas encore d'évaluation
- 14 AppendiceDDocument8 pages14 AppendiceDSanogo HamedPas encore d'évaluation
- Examen Signaux NumériqueDocument5 pagesExamen Signaux Numériquefazfrito lacaviataPas encore d'évaluation
- Comptes Rendus Des Travaux - Pratique - Electromagnétisme-VideDocument23 pagesComptes Rendus Des Travaux - Pratique - Electromagnétisme-Videhansaryh9Pas encore d'évaluation
- 2006 Liban Exo1 Correction Meca Logan 9ptsDocument5 pages2006 Liban Exo1 Correction Meca Logan 9ptsaa.aa1Pas encore d'évaluation
- Corrige Ps PDFDocument3 pagesCorrige Ps PDFSamah Sam BouimaPas encore d'évaluation
- Maths Bac Tseco 2023Document4 pagesMaths Bac Tseco 2023Demba KanoutePas encore d'évaluation
- Ex WeibellDocument10 pagesEx WeibellRachid TirdadPas encore d'évaluation
- Cours Regime Sinusoidal 2016Document30 pagesCours Regime Sinusoidal 2016pedro66100% (1)
- Exercices Fonctions Affines-1Document7 pagesExercices Fonctions Affines-1Bartholomé THURPas encore d'évaluation
- 2019 2020 Rattrapage - SMI3Document4 pages2019 2020 Rattrapage - SMI3FadelPas encore d'évaluation
- Poutres ContinuesDocument8 pagesPoutres ContinuesBassem GhorbelPas encore d'évaluation
- AOP Sommateur MoukhhDocument6 pagesAOP Sommateur Moukhhجمال سينغPas encore d'évaluation
- Corrigés Des Exercices: Corrigé de L'exerciceDocument50 pagesCorrigés Des Exercices: Corrigé de L'exercicekhalid100% (1)
- Volume 1 ExDocument36 pagesVolume 1 ExjeanlucbuathierPas encore d'évaluation
- Devoir MatlabDocument20 pagesDevoir MatlabBelinda DancheuPas encore d'évaluation
- Exercice AcpDocument4 pagesExercice AcpRashid Laanaya100% (1)
- ExamsDocument7 pagesExamsHaythem MzoughiPas encore d'évaluation
- TP S5 PDFDocument12 pagesTP S5 PDFmohammed LautfiPas encore d'évaluation
- RLMDocument6 pagesRLMČhAzoû Nâ-JîîPas encore d'évaluation
- Math PrepaDocument7 pagesMath PrepaFaouzi TlemcenPas encore d'évaluation
- CCP 2000 MP M1 PDFDocument4 pagesCCP 2000 MP M1 PDFSara MarouchePas encore d'évaluation
- CCP 2000 MP M2 Corrige PDFDocument5 pagesCCP 2000 MP M2 Corrige PDFSara MarouchePas encore d'évaluation
- CCP - 2000 - MP - M1 - Corrige 1 PDFDocument4 pagesCCP - 2000 - MP - M1 - Corrige 1 PDFSara MarouchePas encore d'évaluation
- Page de Garde Dans LateX - Forum Mathématiques - 430852Document3 pagesPage de Garde Dans LateX - Forum Mathématiques - 430852Stimphat Jean ColsonPas encore d'évaluation
- BarycentreDocument4 pagesBarycentreespoirPas encore d'évaluation
- La Physique Des Montagnes RussesDocument19 pagesLa Physique Des Montagnes Russesrayassmine18Pas encore d'évaluation
- Chap3 TD Induction Mobile CorrDocument11 pagesChap3 TD Induction Mobile Corrt123medPas encore d'évaluation
- Le Binaire PDFDocument36 pagesLe Binaire PDFEL KANDOUSSI KMPas encore d'évaluation
- Matlab MMC-SMP6Document18 pagesMatlab MMC-SMP6Hamid InekachPas encore d'évaluation
- Document From Jaber KhlieDocument3 pagesDocument From Jaber Khlieoussama khatrouniPas encore d'évaluation
- Codeur IncDocument4 pagesCodeur IncassiahakmiPas encore d'évaluation
- Cours Math ST-SMDocument208 pagesCours Math ST-SMeduppzPas encore d'évaluation
- Projet Diagnostic Des Systèmes AutomatiquesDocument12 pagesProjet Diagnostic Des Systèmes AutomatiquesfatimaPas encore d'évaluation
- MM624-042Document124 pagesMM624-042bouchra oulhajPas encore d'évaluation
- ProjetDocument31 pagesProjetchrif el fahsiPas encore d'évaluation
- Serie2 Ondes ElectromagnétiquesDocument3 pagesSerie2 Ondes ElectromagnétiquesAhamada AnisPas encore d'évaluation
- Chaines de MarkovDocument5 pagesChaines de MarkovHeIsMyGoalPas encore d'évaluation
- D 029 ADocument2 pagesD 029 AninaPas encore d'évaluation
- Expo CPDocument2 pagesExpo CPawayombe2021Pas encore d'évaluation
- EPREUVE HARMONISEE DE MATHEMATIQUES - 1ères Années - Période 4 - 2021-2022Document3 pagesEPREUVE HARMONISEE DE MATHEMATIQUES - 1ères Années - Période 4 - 2021-2022MbilongoPas encore d'évaluation
- Exos Chap 0Document10 pagesExos Chap 0Mohamed KonatePas encore d'évaluation
- Communication JadeDocument7 pagesCommunication JadeMya Ben QueenPas encore d'évaluation
- Correction DS2 4emeDocument1 pageCorrection DS2 4emedarknesss34Pas encore d'évaluation
- Intérêts Composés REL Charfeddine JiheneDocument7 pagesIntérêts Composés REL Charfeddine JihenekramoPas encore d'évaluation
- Support Spss TDDocument32 pagesSupport Spss TDAymane Allak50% (2)
- TD Variables Aléatoire Lois23Document3 pagesTD Variables Aléatoire Lois23Mohamed TraorePas encore d'évaluation
- Cours Calcul D Ouvrages PDFDocument49 pagesCours Calcul D Ouvrages PDFjoelPas encore d'évaluation
- Examen LM2018correction PDFDocument4 pagesExamen LM2018correction PDFMounira IratniPas encore d'évaluation
- 1ere Serie de TDDocument2 pages1ere Serie de TDbermone.a00Pas encore d'évaluation
- TD 5Document2 pagesTD 5Aiman BougdiraPas encore d'évaluation
- Vocabulaire Scientifique AnglaisDocument2 pagesVocabulaire Scientifique AnglaisSamira Moutaoikkil Basskar100% (1)
- Comment Construire Sa Carte de ContrôleDocument5 pagesComment Construire Sa Carte de ContrôleabdelhafidPas encore d'évaluation
- Mécanique Appliquée: Cours Et Exercices Corrigés PDF - Télécharger, LireDocument7 pagesMécanique Appliquée: Cours Et Exercices Corrigés PDF - Télécharger, Lirenabara83% (6)
- Je me prépare aux examens du ministère en mathématiques: Es-tu prêt à passer le test ?D'EverandJe me prépare aux examens du ministère en mathématiques: Es-tu prêt à passer le test ?Évaluation : 4 sur 5 étoiles4/5 (1)
- Les LES TRUCS MATHEMATIQUES AU PRIMAIRE: et si on leur donnait du sens!D'EverandLes LES TRUCS MATHEMATIQUES AU PRIMAIRE: et si on leur donnait du sens!Évaluation : 2 sur 5 étoiles2/5 (1)
- La Conscience Et L'Univers Existent Sans Commencement Ni FinD'EverandLa Conscience Et L'Univers Existent Sans Commencement Ni FinPas encore d'évaluation
- L'univers est intelligent. L'âme existe. Mystères quantiques, multivers, intrication, synchronicité. Au-delà de la matérialité, pour une vision spirituelle du cosmos.D'EverandL'univers est intelligent. L'âme existe. Mystères quantiques, multivers, intrication, synchronicité. Au-delà de la matérialité, pour une vision spirituelle du cosmos.Pas encore d'évaluation
- L'Ombre à l'Univers: La structure des particules élémentaires XIIfD'EverandL'Ombre à l'Univers: La structure des particules élémentaires XIIfPas encore d'évaluation
- La particule de temps: Une approche quantique du tempsD'EverandLa particule de temps: Une approche quantique du tempsPas encore d'évaluation
- Enjeux contemporains de l'éducation scientifique et technologiqueD'EverandEnjeux contemporains de l'éducation scientifique et technologiqueAbdelkrim HasniPas encore d'évaluation
- Quand 7 x 6 = 37: Partir des connaissances des élèves pour enseigner les mathématiquesD'EverandQuand 7 x 6 = 37: Partir des connaissances des élèves pour enseigner les mathématiquesPas encore d'évaluation
- La LA RECHERCHE EN DIDACTIQUE DES MATHEMATIQUES ET LES ELEVES EN DIFFICULTE: Quels enjeux et quelles perspectives?D'EverandLa LA RECHERCHE EN DIDACTIQUE DES MATHEMATIQUES ET LES ELEVES EN DIFFICULTE: Quels enjeux et quelles perspectives?Pas encore d'évaluation
- Représenter pour mieux raisonner - Résolution de problèmes écrits de multiplication et de divisionD'EverandReprésenter pour mieux raisonner - Résolution de problèmes écrits de multiplication et de divisionPas encore d'évaluation
- Du Néant à la Formule Universelle et retour: La structure des particules élémentaires XIIIfD'EverandDu Néant à la Formule Universelle et retour: La structure des particules élémentaires XIIIfPas encore d'évaluation
- Les singularités comme limites ontologiques de la relativité généraleD'EverandLes singularités comme limites ontologiques de la relativité généralePas encore d'évaluation
- Mathématiques ludiques pour les enfants de 4 à 8 ansD'EverandMathématiques ludiques pour les enfants de 4 à 8 ansPas encore d'évaluation
- Se SE PREPARER A ENSEIGNER LES MATHEMATIQUES AU PRIMAIRED'EverandSe SE PREPARER A ENSEIGNER LES MATHEMATIQUES AU PRIMAIREPas encore d'évaluation
- Évaluations nationales des acquis scolaires, Volume 4: Analyser les données issues d'une évaluation nationale des acquis scolairesD'EverandÉvaluations nationales des acquis scolaires, Volume 4: Analyser les données issues d'une évaluation nationale des acquis scolairesPas encore d'évaluation
- Les Êtres Vivants Dépendent De La Mécanique QuantiqueD'EverandLes Êtres Vivants Dépendent De La Mécanique QuantiquePas encore d'évaluation
- Pour une intervention précoce: Dépister, repérer, identifier les difficultés et les troubles d'apprentissage - guideD'EverandPour une intervention précoce: Dépister, repérer, identifier les difficultés et les troubles d'apprentissage - guidePas encore d'évaluation
- Représenter pour mieux raisonner: Résolution de problèmes écrits d'addition et de soustractionD'EverandReprésenter pour mieux raisonner: Résolution de problèmes écrits d'addition et de soustractionPas encore d'évaluation
- Les premiers apprentissages scolaires à la loupe: Des liens entre énumération, oralité et littératieD'EverandLes premiers apprentissages scolaires à la loupe: Des liens entre énumération, oralité et littératiePas encore d'évaluation